一、参数设置
之前有说到HDFS的备份数量和切块大小都是可以配置的,默认是备份3,切块大小默认128M
文件的切块大小和存储的副本数量,都是由客户端决定!
所谓的由客户端决定,是通过客户端机器上面的配置参数来定
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
更多参数详见:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
因此我们只需要在客户端的机器上面hdfs-site.xml中进行配置:
<property> <name>dfs.blocksizename> <value>64mvalue> property> <property> <name>dfs.replicationname> <value>2value> property>
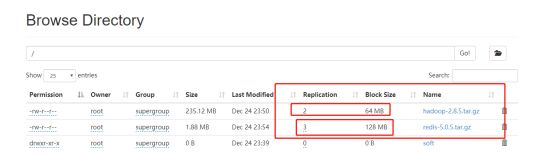
我们在两个客户端进行上传,一个客户端修改为上述配置,查看上传文件信息
可以看见一个文件是3和128m,另外一个是2和64m
二、客户端命令行操作
1、上传文件到hdfs中
hadoop fs -put /本地文件 /aaa
2、下载文件到客户端本地磁盘
hadoop fs -get /hdfs中的路径 /本地磁盘目录
3、在hdfs中创建文件夹
hadoop fs -mkdir -p /aaa/xxx
4、移动hdfs中的文件(更名)
hadoop fs -mv /hdfs的路径1 /hdfs的另一个路径2
复制hdfs中的文件到hdfs的另一个目录
hadoop fs -cp /hdfs路径_1 /hdfs路径_2
5、删除hdfs中的文件或文件夹
hadoop fs -rm -r /aaa
6、查看hdfs中的文本文件内容
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt
更多命令:https://www.cnblogs.com/houkai/p/3848089.html
三、java连接
1.首先需要搭建本地开发环境,因为本地启动应用的时候会从hadoop里面回去调用c的函数操作本地文件系统,因此我们需要在本地配置hadoop的环境信息。
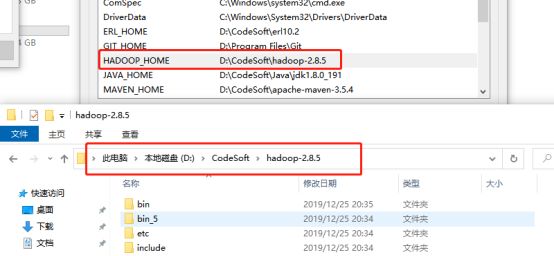
将hadoop压缩包解压出来,留下脚本所在的目录就可以了,其他的一些目录可以丢掉,留下下图圈上的即可

配置hadoop环境变量,将bin目录的里面的文件替换问windows的脚本文件。
windows的脚本文件去哪儿弄呢,可以自己去编译,也可以找别人编译好的:
https://github.com/steveloughran/winutils
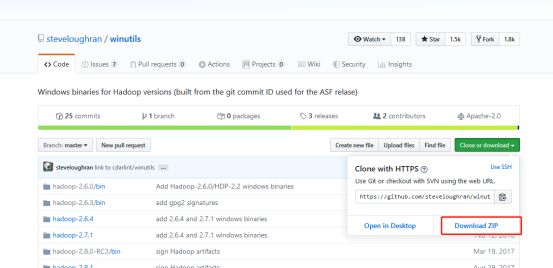
这是别人已经编译好的windows脚本,换到自己的bin目录里面去就行了。
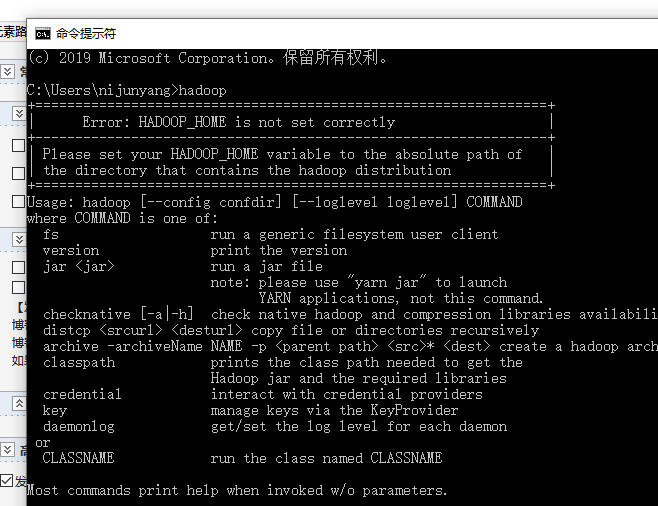
配置好之后检查下能否识别hadoop指令
2. 准备完毕就可以导包撸代码了
导包:版本最好和自己安装hadoop版本一致
<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-commonartifactId> <version>${hadoop.version}version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-hdfsartifactId> <version>${hadoop.version}version> dependency> <dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-hdfs-clientartifactId> <version>${hadoop.version}version> dependency>
上代码:
package com.nijunyang.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.junit.Before; import org.junit.Test; import java.net.URI; import java.util.Arrays; /** * Description: * Created by nijunyang on 2019/12/25 20:26 */ public class HDFSDemo { FileSystem fs; @Before public void init() throws Exception{ URI uri = new URI("hdfs://nijunyang68:9000/"); /** * Configuration 构造会从 classpath中加载core-default.xml hdfs-default.xml core-site.xml hdfs-site.xml等文件 * 也可使用set方法进行自己设置值 * https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml */ Configuration conf = new Configuration(); conf.set("dfs.replication", "2"); // 切块的规格大小:32M conf.set("dfs.blocksize", "32m"); fs = FileSystem.get(uri, conf, "root"); } @Test public void test1() throws Exception { // 上传一个文件到HDFS中 fs.copyFromLocalFile(new Path("E:/安装包/linux/jdk-8u191-linux-x64.tar.gz"), new Path("/soft/")); //下载到本地 fs.copyToLocalFile(new Path("/soft/jdk-8u191-linux-x64.tar.gz"), new Path("f:/")); //在hdfs内部移动文件/修改名称 fs.rename(new Path("/redis-5.0.5.tar.gz"), new Path("/redis5.0.5.tar.gz")); //在hdfs中创建文件夹 fs.mkdirs(new Path("/xx/yy/zz")); //在hdfs中删除文件或文件夹 fs.delete(new Path("/xx/yy/zz"), true); //查询hdfs指定目录下的文件信息 RemoteIteratoriter = fs.listFiles(new Path("/"), true); while(iter.hasNext()){ LocatedFileStatus status = iter.next(); System.out.println("文件全路径:"+status.getPath()); System.out.println("块大小:"+status.getBlockSize()); System.out.println("文件长度:"+status.getLen()); System.out.println("副本数量:"+status.getReplication()); System.out.println("块信息:"+ Arrays.toString(status.getBlockLocations())); System.out.println("--------------------------------"); } //查询hdfs指定目录下的文件和文件夹信息 FileStatus[] listStatus = fs.listStatus(new Path("/")); for(FileStatus status:listStatus){ System.out.println("文件全路径:"+status.getPath()); System.out.println(status.isDirectory()?"这是文件夹":"这是文件"); System.out.println("块大小:"+status.getBlockSize()); System.out.println("文件长度:"+status.getLen()); System.out.println("副本数量:"+status.getReplication()); System.out.println("--------------------------------"); } fs.close(); } }
简单来说java代码也就是一个客户端访问,所以说配置信息都可以塞到Configuration里面去。