本文测试文本:
tom 20 8000
nancy 22 8000
ketty 22 9000
stone 19 10000
green 19 11000
white 39 29000
socrates 30 40000
MapReduce中,根据key进行分区、排序、分组
MapReduce会按照基本类型对应的key进行排序,如int类型的IntWritable,long类型的LongWritable,Text类型,默认升序排序
为什么要自定义排序规则?现有需求,需要自定义key类型,并自定义key的排序规则,如按照人的salary降序排序,若相同,则再按age升序排序
以Text类型为例:


Text类实现了WritableComparable接口,并且有write()、readFields()和compare()方法
readFields()方法:用来反序列化操作
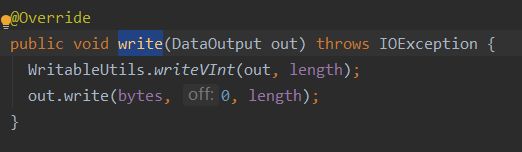
write()方法:用来序列化操作
所以要想自定义类型用来排序需要有以上的方法
自定义类代码:
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Person implements WritableComparable {
private String name;
private int age;
private int salary;
public Person() {
}
public Person(String name, int age, int salary) {
//super();
this.name = name;
this.age = age;
this.salary = salary;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
@Override
public String toString() {
return this.salary + " " + this.age + " " + this.name;
}
//先比较salary,高的排序在前;若相同,age小的在前
public int compareTo(Person o) {
int compareResult1= this.salary - o.salary;
if(compareResult1 != 0) {
return -compareResult1;
} else {
return this.age - o.age;
}
}
//序列化,将NewKey转化成使用流传送的二进制
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(name);
dataOutput.writeInt(age);
dataOutput.writeInt(salary);
}
//使用in读字段的顺序,要与write方法中写的顺序保持一致
public void readFields(DataInput dataInput) throws IOException {
//read string
this.name = dataInput.readUTF();
this.age = dataInput.readInt();
this.salary = dataInput.readInt();
}
}
MapReuduce程序:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
public class SecondarySort {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME","hadoop2.7");
Configuration configuration = new Configuration();
//设置本地运行的mapreduce程序 jar包
configuration.set("mapreduce.job.jar","C:\\Users\\tanglei1\\IdeaProjects\\Hadooptang\\target\\com.kaikeba.hadoop-1.0-SNAPSHOT.jar");
Job job = Job.getInstance(configuration, SecondarySort.class.getSimpleName());
FileSystem fileSystem = FileSystem.get(URI.create(args[1]), configuration);
if (fileSystem.exists(new Path(args[1]))) {
fileSystem.delete(new Path(args[1]), true);
}
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(Person.class);
job.setMapOutputValueClass(NullWritable.class);
//设置reduce的个数
job.setNumReduceTasks(1);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Person.class);
job.setOutputValueClass(NullWritable.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class MyMap extends
Mapper {
//LongWritable:输入参数键类型,Text:输入参数值类型
//Persion:输出参数键类型,NullWritable:输出参数值类型
@Override
//map的输出值是键值对,NullWritable说关心V的值
protected void map(LongWritable key, Text value,
Context context)
throws IOException, InterruptedException {
//LongWritable key:输入参数键值对的键,Text value:输入参数键值对的值
//获得一行数据,输入参数的键(距首行的位置),Hadoop读取数据的时候逐行读取文本
//fields:代表着文本一行的的数据
String[] fields = value.toString().split(" ");
// 本列中文本一行数据:nancy 22 8000
String name = fields[0];
//字符串转换成int
int age = Integer.parseInt(fields[1]);
int salary = Integer.parseInt(fields[2]);
//在自定义类中进行比较
Person person = new Person(name, age, salary);
context.write(person, NullWritable.get());
}
}
public static class MyReduce extends
Reducer {
@Override
protected void reduce(Person key, Iterable values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
}
运行结果:
40000 30 socrates
29000 39 white
11000 19 green
10000 19 stone
9000 22 ketty
8000 20 tom
8000 22 nancy