一.分析
Spark提供了非常丰富的算子,可以实现大部分的逻辑处理,例如,要实现行转列,可以用hiveContext中支持的concat_ws(',', collect_set('字段'))实现。但是这有明显的局限性【sqlContext不支持】,因此,基于编码逻辑或自定义聚合函数实现相同的逻辑就显得非常重要了。
二.列转行代码实现
1 package utils 2 import com.hankcs.hanlp.tokenizer.StandardTokenizer 3 import org.apache.log4j.{Level, Logger} 4 import org.apache.spark.sql.{SparkSession, Row} 5 import org.apache.spark.sql.types.{StringType, StructType, StructField} 6 /** 7 * Created by Administrator on 2019/12/17. 8 */ 9 object Column2Row { 10 /** 11 * 设置日志级别 12 */ 13 Logger.getLogger("org").setLevel(Level.WARN) 14 def main(args: Array[String]) { 15 val spark = SparkSession.builder().master("local[2]").appName(s"${this.getClass.getSimpleName}").getOrCreate() 16 val sc = spark.sparkContext 17 val sqlContext = spark.sqlContext 18 19 val array : Array[String] = Array("spark-高性能大数据解决方案", "spark-机器学习图计算", "solr-搜索引擎应用广泛", "solr-ES灵活高效") 20 val rdd = sc.parallelize(array) 21 22 val termRdd = rdd.map(row => { // 标准分词,挂载Hanlp分词器 23 var result = "" 24 val type_content = row.split("-") 25 val termList = StandardTokenizer.segment(type_content(1)) 26 for(i <- 0 until termList.size()){ 27 val term = termList.get(i) 28 if(!term.nature.name.contains("w") && !term.nature.name().contains("u") && !term.nature.name().contains("m")){ 29 if(term.word.length > 1){ 30 result += term.word + " " 31 } 32 } 33 } 34 Row(type_content(0),result) 35 }) 36 37 val structType = StructType(Array( 38 StructField("arth_type", StringType, true), 39 StructField("content", StringType, true) 40 )) 41 42 val termDF = sqlContext.createDataFrame(termRdd,structType) 43 termDF.show(false) 44 /** 45 * 列转行 46 */ 47 val termCheckDF = termDF.rdd.flatMap(row =>{ 48 val arth_type = row.getAs[String]("arth_type") 49 val content = row.getAs[String]("content") 50 var res = Seq[Row]() 51 val content_array = content.split(" ") 52 for(con <- content_array){ 53 res = res :+ Row(arth_type,con) 54 } 55 res 56 }).collect() 57 58 val termListDF = sqlContext.createDataFrame(sc.parallelize(termCheckDF), structType) 59 termListDF.show(false) 60 61 sc.stop() 62 } 63 }
三.列转行执行结果
列转行之前:
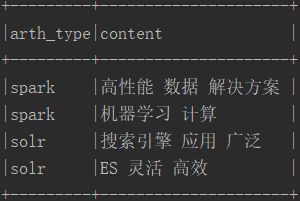
列转行:
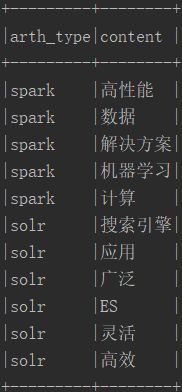
四.行转列代码实现
1 package test 2 3 import org.apache.log4j.{Level, Logger} 4 import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction} 5 import org.apache.spark.sql.types._ 6 import org.apache.spark.sql.{Row, SparkSession} 7 8 /** 9 * 自定义聚合函数实现行转列 10 */ 11 object AverageUserDefinedAggregateFunction extends UserDefinedAggregateFunction{ 12 //聚合函数输入数据结构 13 override def inputSchema:StructType = StructType(StructField("input", StringType) :: Nil) 14 15 //缓存区数据结构 16 override def bufferSchema: StructType = StructType(StructField("result", StringType) :: Nil) 17 18 //结果数据结构 19 override def dataType : DataType = StringType 20 21 // 是否具有唯一性 22 override def deterministic : Boolean = true 23 24 //初始化 25 override def initialize(buffer : MutableAggregationBuffer) : Unit = { 26 buffer(0) = "" 27 } 28 29 //数据处理 : 必写,其它方法可选,使用默认 30 override def update(buffer: MutableAggregationBuffer, input: Row): Unit = { 31 if(input.isNullAt(0)) return 32 if(buffer.getString(0) == null || buffer.getString(0).equals("")){ 33 buffer(0) = input.getString(0) //拼接字符串 34 }else{ 35 buffer(0) = buffer.getString(0) + "," + input.getString(0) //拼接字符串 36 } 37 } 38 39 //合并 40 override def merge(bufferLeft: MutableAggregationBuffer, bufferRight: Row): Unit ={ 41 if(bufferLeft(0) == null || bufferLeft(0).equals("")){ 42 bufferLeft(0) = bufferRight.getString(0) //拼接字符串 43 }else{ 44 bufferLeft(0) = bufferLeft(0) + "," + bufferRight.getString(0) //拼接字符串 45 } 46 } 47 48 //计算结果 49 override def evaluate(buffer: Row): Any = buffer.getString(0) 50 } 51 52 /** 53 * Created by Administrator on 2019/12/17. 54 */ 55 object Row2Columns { 56 /** 57 * 设置日志级别 58 */ 59 Logger.getLogger("org").setLevel(Level.WARN) 60 def main(args: Array[String]): Unit = { 61 val spark = SparkSession.builder().master("local[2]").appName(s"${this.getClass.getSimpleName}").getOrCreate() 62 val sc = spark.sparkContext 63 val sqlContext = spark.sqlContext 64 65 val array : Array[String] = Array("大数据-Spark","大数据-Hadoop","大数据-Flink","搜索引擎-Solr","搜索引擎-ES") 66 67 val termRdd = sc.parallelize(array).map(row => { // 标准分词,挂载Hanlp分词器 68 val content = row.split("-") 69 Row(content(0), content(1)) 70 }) 71 72 val structType = StructType(Array( 73 StructField("arth_type", StringType, true), 74 StructField("content", StringType, true) 75 )) 76 77 val termDF = sqlContext.createDataFrame(termRdd,structType) 78 termDF.show() 79 termDF.createOrReplaceTempView("term") 80 81 /** 82 * 注册udaf 83 */ 84 spark.udf.register("concat_ws", AverageUserDefinedAggregateFunction) 85 spark.sql("select arth_type,concat_ws(content) content from term group by arth_type").show() 86 } 87 }
五.行转列执行结果
行转列之前:
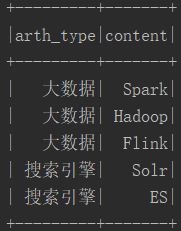
行转列:
