HDFS
hadoop 的基础分布式文件存储系统,分为NameNode和DataNode.
NameNode负责存储文件系统的metadata,管理DataNode的数据存储和数据安全
DataNode负责存储数据文件
- 对应配置文件
core-site.xml和hdfs-site.xml - NameNode本地存储位置配置:
dfs.namenode.name.dir(hdfs-site.xml) - DataNode本地存储位置配置:
dfs.datanode.data.dir(hdfs-site.xml)
单NameNode配置
Cluster配置
支持NameNode的配置成Cluster
- 注意事项:
- NameNode 的active和standby需要有同等的硬件配置
Note: the machines on which you run the Active and Standby NameNodes should have equivalent hardware to each other, and equivalent hardware to what would be used in a non-HA cluster.
- 当前只支持两个NameNode结点,配置在集群的NameService中
Note: Currently, only a maximum of two NameNodes may be configured per nameservice.
- 配置
- hdfs-site.xml
-
dfs.nameservices - the logical name for this new nameservice
Choose a logical name for this nameservice, for example “mycluster”, and use this logical name for the value of this config option. The name you choose is arbitrary. It will be used both for configuration and as the authority component of absolute HDFS paths in the cluster.
Note: If you are also using HDFS Federation, this configuration setting should also include the list of other nameservices, HA or otherwise, as a comma-separated list.dfs.nameservices mycluster dfs.ha.namenodes.[nameservice ID] - unique identifiers for each NameNode in the nameservice
-
- core-site.xml
Yarn
名词含义
- ResourceManager: 以下简称RM。YARN的中控模块,负责统一规划资源的使用。
- NodeManager: 以下简称NM。YARN的资源结点模块,负责启动管理container。
- ApplicationMaster: 以下简称AM。YARN中每个应用都会启动一个AM,负责向RM申请资源,请求NM启动container,并告诉container做什么事情。
- Container:资源容器。YARN中所有的应用都是在container之上运行的。AM也是在container上运行的,不过AM的container是RM申请的。
架构
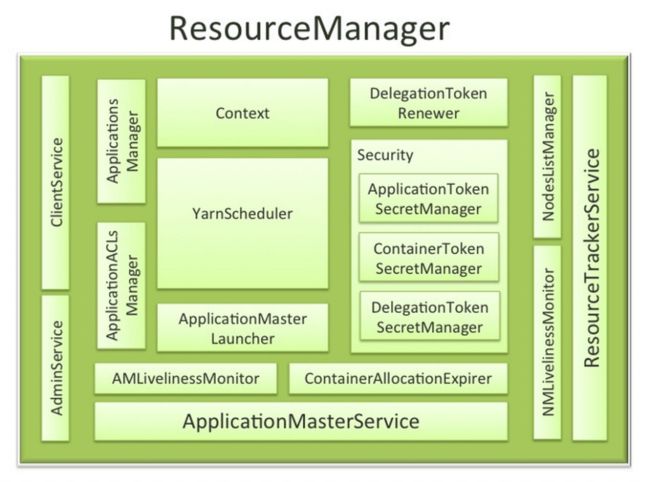
- RM
ResourceManager是YARN资源控制框架的中心模块,负责集群中所有的资源的统一管理和分配。它接收来自NM的汇报,建立AM,并将资源派送给AM.
-
调度器概览
最初的hadoop的版本只有FifoScheduler(先进先出调度器)。
后来,Yahoo!和facebook先后开发了CapacityScheduler(容量调度器)和FairScheduler(公平调度器)。内存中都会维护一个队列,应用,NM,Container的关系。
-
事件处理器,通过RM的异步的事件调用机制知晓外部的发生的事情。要跟外部交互也要发送相应的事件。调度器一共要处理6个调度事件
 Schedule events
Schedule events
除了这6个事件,还有一个函数会在AM跟RM心跳的时候会被调用。
Allocation allocate(ApplicationAttemptId appAttemptId,Listask,List release);
AM会告诉调度器一些资源申请的请求和已经使用完的container的列表,然后获取到已经在NODE_UPDATE分配给这个应用的container的分配。
可以看到调度器接受资源的申请和分配资源这个动作是异步的。
RM每次分配,先获取一个资源队列,从队列中获取一个job,然后依次在各个机器上尝试分配资源,直到成功或者失败次数过多。- 调度算法
FifoScheduler:最简单的调度器,按照先进先出的方式处理应用。只有一个队列可提交应用,所有用户提交到这个队列。可以针对这个队列设置ACL。没有应用优先级可以配置。
CapacityScheduler:可以看作是FifoScheduler的多队列版本。每个队列可以限制资源使用量。但是,队列间的资源分配以使用量作排列依据,使得容量小的队列有竞争优势。集群整体吞吐较大。延迟调度机制使得应用可以放弃跨机器的调度机会,争取本地调度。
FairScheduler:多队列,多用户共享资源。特有的客户端创建队列的特性,使得权限控制不太完美。根据队列设定的最小共享量或者权重等参数,按比例共享资源。延迟调度机制跟CapacityScheduler的目的类似,但是实现方式稍有不同。资源抢占特性,是指调度器能够依据公平资源共享算法,计算每个队列应得的资源,将超额资源的队列的部分容器释放掉的特性。 - 本地优化与延迟调度
- 在YARN运行应用的时候,AM会将输入文件进行切割,然后,AM向RM申请的container来运行task来处理这些被切割的文件段。Yarn是基于HDFS文件系统的资源管理。
- 如果一个HDFS文件有N个副本,存在N台机器上。那如果AM申请到的container在这N台机器上的其中一个,那这个task就无须从其它机器上传输要处理的文件段,节省网络传输。这就是Hadoop的本地优化。
- YARN的实现本地优化的方式是AM给RM提交的资源申请的时候,会同时发送本地申请,机架申请和任意申请。然后,RM的匹配这些资源申请的时候,会先匹配本地申请,再匹配机架申请,最后才匹配任意申请。
- 延迟调度机制,就是调度器在匹配本地申请失败的时候,匹配机架申请或者任意申请成功的时候,允许略过这次的资源分配,直到达到延迟调度次数上限。CapacityScheduler和FairScheduler在延迟调度上的实现稍有不同,前者的调度次数是根据规则计算的,后者的调度次数通过配置指定的,但实际的含义是一样的。
-
容量调度器
在hadoop集群配置中启动容量调度器之后,调度器会从classpath中加载capacity-scheduler.xml文件,完成容量调度器的初始化总结起来有如下特性:
1) 动态更新配置:容量调度器的配置文件在运行时可以随时重新加载来调整分配参数。除非重启ResourceManager,否则队列只能添加不能删除,但是允许关闭。修改配置文件后,使用以下命令可以刷新配置。
yarn rmadmin -refreshQueues
2) 树形组织队列:容量调度器的队列是按照树形结构组织的。根队列只有一个root队列。子队列分享父队列的资源。每个队列设定一个容量值代表可使用父队列的容量值,容量值会影响队列的排序。父队列的所有子队列的容量相加一定是100,否则加载失败。还有一个最大容量值表示子队列绝对不会超过的使用上限。
3) 队列应用限制:队列可以设定最大提交的应用数量和AM占用资源的百分比。AM占用资源的百分 比这个配置是用来计算队列的最大活跃应用数量。这里有个小问题。调度器中最大活跃应用数量=AM占用资源的百分比队列最大可使用资源量/最小的container分配额度。但是我们在mapred-site.xml中会配置AM的内存额度会比最小container分配额度大,造成最大活跃应用数量虚高(可以理解,如果YARN加入不同的计算框架,AM的分配会不一致,所以这里使用最小container分配额度来计算。但是,如果是这样的话,应该直接计算AM的内存使用量来控制)。
4) 用户参数限制:用户可以提交应用到多个队列。不同队列间用户的应用运行情况,不相互影响。用户在队列中最大可占用资源受两个参数控制,一个是单用户占据队列的百分比上限,一个是单用户内存使用上限。具体参看下面的参数表。
5)资源分配选择:不同队列之间,按照队列的资源使用比排序。同一队列中的应用按照应用id排序,也就是先进先出。
6)延迟调度*:当调度次数小于本地延迟调度次数的时候不接受机架调度。本地延迟调度次数,由yarn.scheduler.capacity.node-locality-delay配置,默认是-1,不开启延迟调度。官方文档中没有提及这个参数。而任意调度的延迟调度上限是应用申请的机器的数量,不能配置。容量调度器的参数计算关系
在RM的管理界面参数:
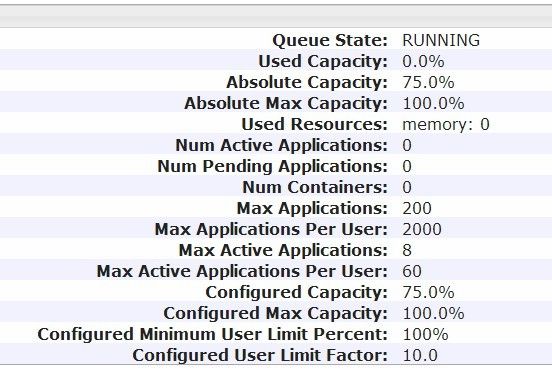 容量调度参数
容量调度参数
队列绝对容量=父队列的 队列绝对容量*队列容量
队列最大容量=yarn.scheduler.capacity..maximum-capacity/100
队列绝对最大容量=父队列的 队列绝对最大容量*队列最大容量
绝对资源使用比=使用的资源/全局资源
资源使用比=使用的资源/(全局资源 * 队列绝对容量)
最小分配量=yarn.scheduler.minimum-allocation-mb
用户上限=MAX(yarn.scheduler.capacity..minimum-user-limit-percent,1/队列用户数量)
用户调整因子=yarn.scheduler.capacity..user-limit-factor
最大提交应用=yarn.scheduler.capacity..maximum-applications
如果小于0 设置为(yarn.scheduler.capacity.maximum-applications*队列绝对容量)
单用户最大提交应用=最大提交应用*(用户上限/100)*用户调整因子
AM资源占比(AM可占用队列资源最大的百分比)
=yarn.scheduler.capacity..maximum-am-resource-percent
如果为空,设置为yarn.scheduler.capacity.maximum-am-resource-percent
最大活跃应用数量=全局总资源/最小分配量*AM资源占比*队列绝对最大容量
单用户最大活跃应用数量=(全局总资源/最小分配量*AM资源占比*队列绝对容量)*用户上限*用户调整因子
本地延迟分配次数=yarn.scheduler.capacity.node-locality-delay
-
公平调度器
在hadoop集群配置中启动公平调度器之后,调度器会从classpath中加载fair-scheduler.xml和fair-allocation.xml文件,完成公平调度器的初始化。其中fair-scheduler.xml主要描述重要特性的配置,fair-allocation.xml主要描述了具体的队列及其参数配置。总结起来有如下特性:
1) 动态更新配置:公平调度器的fair-allocation.xml配置文件在运行时可以随时重新加载来调整分配参数。除非重启ResourceManager,否则队列只能添加不能删除。修改fair-allocation.xml后,使用以下命令可以刷新配置。
yarn rmadmin -refreshQueues
2) 树形组织队列:公平调度器的队列是按照树形结构组织的。根队列只有一个root队列。父子队列除了ACL参数外,其余参数都不继承。
3) 队列应用参数:应用只能提交到叶子队列。受队列最大应用数量限制。队列可以设定权重,最小共享量和最大使用量。权重和最小共享量将影响在公平排序算法中的排名,从而影响资源调度倾向。队列还可以设定最大运行的应用数量。
4) 用户参数限制:一个用户可以提交应用到多个队列。用户受全局的最大可运行数量限制。
5) 资源分配选择:资源分配的时候,使用公平排序算法选择要调度的队列,然后在队列中使用先进先出算法或者公平排序算法选择要调度的应用。
6) 延迟调度:每种资源申请的优先级都有一个资源等级标记。一开始标记都是NODE_LOCAL,只允许本地调度。如果调度机会大于NM数量乘以上界(locality.threshold.node),资源等级转变为RACK_LOCAL、重置调度机会为0、接受机架调度。如果调度机会再次大于NM数量乘以上界(locality.threshold.rack),资源等级转变为OFF_SWITCH、重置调度机会为0、接受任意调度。详情代码参看[FSSchedulerApp.getAllowedLocalityLevel:470]
7) 资源抢占:调度器会使用公平资源共享算法计算每个队列应该得到的资源总量。如果一个队列长时间得不到应得到的资源量,调度器可能会杀死占用掉该部分资源的容器。
配置: fair-scheduler.xml
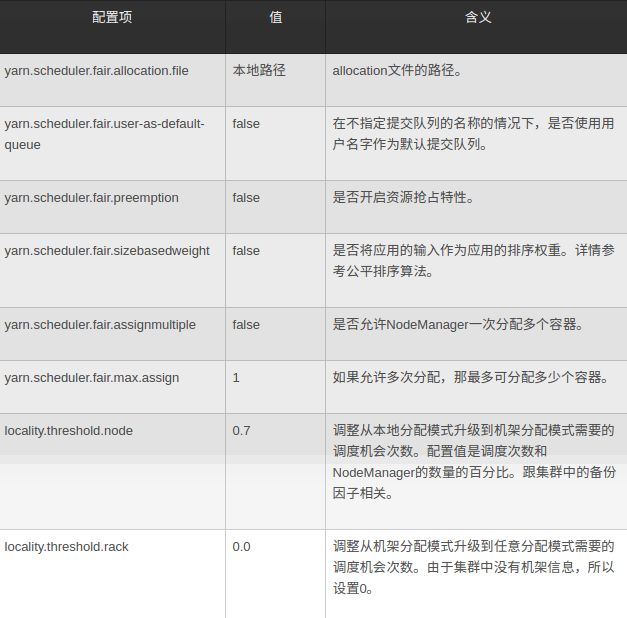 fair-scheduler.xml公平调度配置
fair-scheduler.xml公平调度配置公平排序算法:
公平排序算法是公平调度器的核心算法。调度器在选取哪个队列和队列中的哪个应用需要优先得到资源调度的时候使用。每个队列或者应用都有以下几个供排序的参数:
- 资源需求量。当前队列或者应用希望获得的资源的总量。
2)** 最小共享量。队列的最小共享量在配置中指定。应用的最小共享量为0。
3) 资源使用量。**当前队列或者应用分配到的总资源。 - 权值。队列的权重值在配置中指定。在开启sizebasedweight特性的情况下,应用的权重=(log2(资源需求量))优先级调整因子。优先级当前都是1,。当应用运行超过5分钟,调整因子为3。
排序算法的核心是两个比较体的比较算法,具体如下:
1.计算比较体是否需要资源。即资源使用量是否小于资源需求量且小于最小共享量。
2.如果两者都需要资源,计算资源分配比=资源使用量/Min(资源需求量,最小共享量)。资源分配比较小的优先。
3.如果一个需要,一个不需要,需要的优先。
4.如果两者都不需要资源,计算使用权值比=资源使用量/权值。使用权值比较小的优先。
5.如果2或者4中的比较相同,则先提交的优先。
详情代码参看[SchedulingAlgorithms.FairShareComparator.compare:81]
*公平资源共享算法:*
公平调度器为公平地分配资源,在开启资源抢占的特性的情况下,可能会杀死部分运行中的容器,释放超额的资源。
公平调度器启动的时候会建立一个UpdateThread的线程,负责计算公平资源量和进行资源抢占。其中,调度器使用了公平资源共享算法重新计算队列的公平资源量。
名词解释: 资源权重比=资源获得量/队列权重。知道全局的资源权重比,每个队列就可以根据自己的权值,知道自己能分配多少资源。
公平资源共享算法的目的是为了每个队列公平地使用资源,这个公平体现在每个队列得到的资源比等于他们的权值比。如果只是单纯地求一个资源权重比,可以直接相除。但是由于需要满足队列的资源分配满足最小共享量、最大资源量这些队列上下界的限制,资源权重比不能直接计算。
反过来,如果知道资源权重比,就可以计算出集群一共需要多少资源,而且,集群资源需求量=Fun(资源权重比)是单调的。
所以可以使用二分资源权重比的方法,计算集群资源需求量,使得集群资源需求量逼近当前的集群资源量。
具体算法流程如下:
1.设置根队列的公平资源量为全局资源总和
2.根队列调用recomputeFairShares,计算公平资源量
2.1计算当前队列的分配量=MIN(队列总需求,公平资源量)
2.2计算资源权重比最大值。最大值=2^n,使得Fun(最大值)>集群资源量>Fun(最大值/2)。
2.2计算资源权重比。采用二分法计算,二分法次数最多25次。每个队列的公平资源量= (权重*权重资源比,用最小共享量修正下界,用资源需求量修正上界)
2.3设置每个子队列的公平资源量=资源权重比*权值。
2.4各个子队列调用recomputeFairShares,递归计算。
详情代码参看[FairScheduler:221]
*公平调度器的使用设计建议:*
- 队列的最小共享量越大,在集群繁忙的时候分配到的资源就越多。
- 但是,如果每个用户都将最小共享量设置到最大,不利于集群间的资源共享。建议,将队列愿意共享出来的内存大小和队列的权值挂钩。含义就是,你愿意共享得越多,在整体资源分配中就越能分得更多的资源。
*公平调度器的全局配置:*
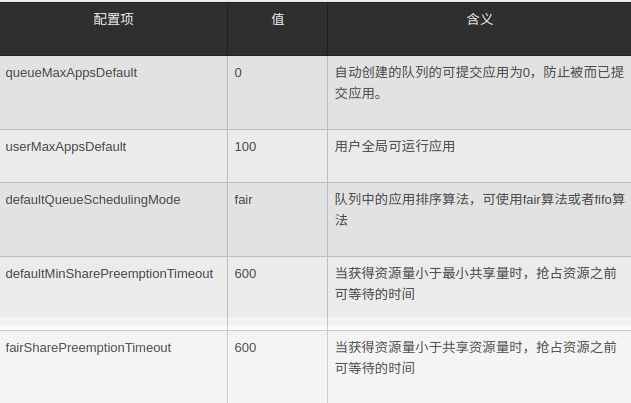
基本配置
- yarn-site.xml
yarn.timeline-service.hostname 配置timeline-service存储的历史记录所在的结点
yarn.timeline-service.leveldb-timeline-store.path 配置timeline-service存储的历史记录所在的结点的目录
资源配置
配置说明
-
yarn.nodemanager.resource.memory-mb (NM: yarn-site.xml)
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而YARN不会智能的探测节点的物理内存总量。 (
每个nodemanager可分配的内存总量)Amount of physical memory, in MB, that can be allocated for containers.
-
yarn.nodemanager.vmem-pmem-ratio (NM: yarn-site.xml)
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.
-
yarn.nodemanager.pmem-check-enabled (NM: yarn-site.xml)
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。Whether physical memory limits will be enforced for containers.
-
** yarn.nodemanager.vmem-check-enabled** (NM: yarn-site.xml)
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。Whether virtual memory limits will be enforced for containers.
-
yarn.scheduler.minimum-allocation-mb (RM: yarn-site.xml)
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。(container最小可申请的内存。在调度器中,很多资源计算部分会转化为这个最小值的N倍进行计算。所以,设定可分配内存等资源的时候,最好是刚好为这个最小值的倍数。)The minimum allocation for every container request at the RM, in MBs. Memory requests lower than this won't take effect, and the specified value will get allocated at minimum.
-
yarn.scheduler.maximum-allocation-mb (RM: yarn-site.xml)
单个任务可申请的最多物理内存量,默认是8192(MB)。 (container最多可申请的内存数量)The maximum allocation for every container request at the RM, in MBs. Memory requests higher than this won't take effect, and will get capped to this value.
mapreduce.map.memory.mb (AM: mapred-site.xml)
mapreduce.reduce.memory.mb (AM: mapred-site.xml)
指定map和reduce task的内存大小,该值应该在RM的最大最小container之间。如果不设置,则默认用以下规则进行计算:max{MIN_Container_Size,(Total Available RAM/containers)}。mapreduce.map.java.opts (AM: mapred-site.xml)
mapreduce.reduce.java.opts (AM: mapred-site.xml)
需要运行JVM程序(java,scala等)准备,通过这两个参数可以向JVM中传递参数,与内存有关的是-Xmx, -Xms等选项,数值的大小应该相应的在AM中的map.mb或reduce.mb之间。
默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制。
其他
NameNode, ResourceManager通过 slaves 读取到结点列表
链接
- 集群篇
- 运维篇
- 使用篇