前言
近年来随着互联网2.0时代的发展,越来越多的公司更加注重用户体验和互动,这些公司的平台上会出现越来越多方便用户操作和选择的新功能,如优惠券发放、抢红包、购物车、热点新闻、购物排行榜等,这些业务的特点是数据更新频繁、数据结构简单、功能模块相对独立、以及访问量巨大,对于这些业务来说,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSql出现的原因
关系型数据库面临的问题
– 扩展困难:由于存在类似Join这样多表查询机制,使得数据库在扩展方面很艰难;
– 读写慢:这种情况主要发生在数据量达到一定规模时由于关系型数据库的系统逻辑非常复杂,使得其非常容易发生死锁等的并发问题,所以导致其读写速度下滑非常严重;
– 成本高:企业级数据库的License价格很惊人,并且随着系统的规模,而不断上升;
– 有限的支撑容量:现有关系型解决方案还无法支撑Google这样海量的数据存储;
数据库访问的新需求
– 低延迟的读写速度:应用快速地反应能极大地提升用户的满意度;
– 支撑海量的数据和流量:对于搜索这样大型应用而言,需要利用PB级别的数据和能应对百万级的流量;
– 大规模集群的管理:系统管理员希望分布式应用能更简单的部署和管理;
– 庞大运营成本的考量:IT经理们希望在硬件成本、软件成本和人力成本能够有大幅度地降低;
NoSQL数据库仅仅是关系数据库在某些方面(性能、扩展)的一个弥补,单从功能上讲,NoSQL的几乎所有的功能,在关系数据库上都能够满足。 一般会把NoSQL和关系数据库进行结合使用,各取所长,各得其所。
在某些应用场合,比如一些配置的关系键值映射存储、用户名和密码的存储、Session 会话存储等等 ;在某些场景下,用NoSQL完全可以替代关系数据库(如:MySQL)存储。不但具有更高 的性能,而且开发也更加方便。
关系型数据和nosql数据的不同
关系型数据库:
- 强调ACID:
原子性(Atomicity)
一致性(Consistency)
隔离性(Isolation)
持久性(Durability)
目的就是通过事务支持,保证数据的完整性和正确性。
NoSql:
对于许多互联网应用来说,对于一致性要求可以降低,而可用性的要求则更为明显,在CAP理论基础上,从而产生了弱一致性的理论BASE,BASE分别是英文:
Basically, Available(基本可用)
Soft- state(软状态)非实时同步
Eventual Consistency(最终一 致)的缩写,这个模型是反 ACID模型。Nosql 的优缺点
优点:扩展简单、读写速度快、成本低廉
缺点:不提供对SQL的支持、支持的特性不够丰富、现有产品不够成熟 - NoSQL数据库的出现,弥补了关系数据(比如MySQL)在某些方面的不足, 在某些方面能极大的节省开发成本和维护成本。
- MySQL和NoSQL都有各自的特点和使用的应用场景,两者的紧密结合将会 给web2.0的数据库发展带来新的思路。让关系数据库关注在关系上, NoSQL关注在功能、性能上。
- 随着移动互联网的发展,以及业务场景的多样化,社交元素的普遍化, Nosql从性能和功能上很好的补充了web2.0时代的原关系型数据的缺点, 目前已经是各大公司必备的技术之一。

目前企业常见的nosql应用
1.纯nosql架构(nosql为主)
适用于查询关系非常简单;数据结构经常变化,比如监控系统中存储的监控信息;
2.以nosql为数据源的架构(nosql为主)
数据直接写入nosql,再通过同步协议复制到其他存储,这种架构需要考虑数据复制的延迟问 题,这跟使用MySQL的master- salve模式的延迟问题是一样的,解决方法也一样。
3.nosql作为镜像(nosql为辅)
不改变原有的以MySQL作为存储的架构,使用NoSQL作为辅助镜像存储,用NoSQL的优势辅助提升性能。 在原有基于MySQL数据库的架构上增加了一层辅助的NoSQL存储,在写入MySQL数据库后,同时写入到NoSQL数据库,让MySQL和 NoSQL拥有相同的镜像数据,在某些可以根据主键查询的地方,使用高效的NoSQL数据库查询。
4.NoSQL为镜像(同步模式,nosql为辅)
通过MySQL把数据同步到NoSQL中, 是一种对写入透明但是具有更高技术难度一种模式,适用于现有的比较复杂的老系统,通过修改代码不易实现,可能引起新的问题。同时也适用于需要把数据同步到多种类型的存储中。
5.MySQL和NoSQL组合(nosql为辅)
MySQL中只存储需要查询的小字段,NoSQL存储所有数据。把需要查询的字段,一般都是数字,时间等类型的小字段存储于 MySQL中,根据查询建立相应的索引,其他不需要的字段,包括大文本字段都存储在NoSQL中。在查询的时候,我们先从MySQL中查询出数据的主键,然后从NoSQL 中直接取出对应的数据即可。
总结:
由于NoSQL数据库天生具有高性能、易扩展的特点,所以我们常常结合关 系数据库,存储一些高性能的、海量的数据。 从另外一个角度看,根据NoSQL的高性能特点,它同样适合用于缓存数据,用NoSQL缓存数据可以分为内存模式和磁盘持久化模式。 - 内存模式:
Memcached提供了相当高的读写性能,在互联网发展过程中,一直是缓存服务器的首选。 NoSQL数据库Redis又为我们提供了功能更加强大的内存存储功能。跟 Memcached比,Redis的一个key的可以存储多种数据结构Strings、 Hashes、Lists、Sets、Sorted sets。Redis不但功能强大,而且它的性能完全超越大名鼎鼎的Memcached。 Redis支持List、hashes等多种数据结构的功能,提供了更加易于使用的api和操作性能,比如对缓存的list数据的修改。 - 持久化模式:
虽然基于内存的缓存服务器具有高性能,低延迟的特点,但是内存成本高、内存数据易失却不容忽视。大部分互联网应用的特点都是数据访问有热点,也就是说,只有一部分 数据是被频繁访问的。
其实NoSQL数据库内部也是通过内存缓存来提高性能的,通过一些比较好的算法 ,把热点数据进行内存cache ,非热点数据存储到磁盘以节省内存占用;使用NoSQL来做缓存,由于其不受内存大小的限制,我们可以把一些不常访问、不怎么更新的数据也缓存起来。NoSql代表——Redis
Redis是什么
redis是一个key-value存储系统。和Memcached类似,它支持存储的value 类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、 add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子 性的。在此基础上,redis支持各种不同方式的排序。与memcached一样, 为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的 数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了 memcached这类key/value存储的不足,在部 分场合可以对关系数据库起 到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl ,Object-C,Python,Ruby,Erlang等客户端,使用很方便。 Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步, 从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树 复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机 制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完 整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。 redis的官网地址,非常好记,是redis.io。
Redis特点
1、完全居于内存,数据实时的读写内存,定时闪回到文件中。采用单线程,避免了不必要的上下文切换和竞争条件
2、支持高并发量,官方宣传支持10万级别的并发读写
3、支持持久存储,机器重启后的,重新加载模式,不会掉数据
4、海量数据存储,分布式系统支持,数据一致性保证,方便的集群节点添加/删除
5、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结 构的存储。
6、灾难恢复--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;
7、虚拟内存--Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘;
8、Redis支持数据的备份,即master-slave模式的数据备份;
Redis架构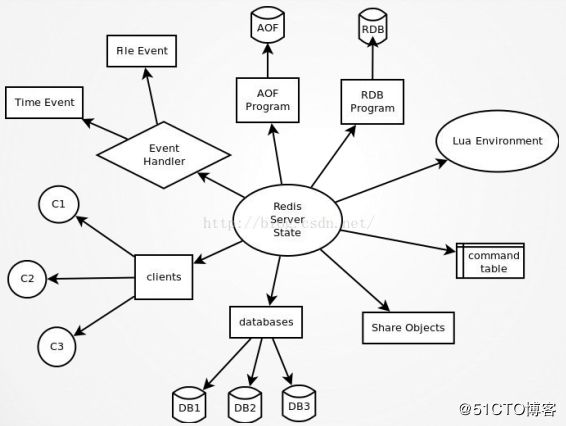
各功能模块说明如下:
File Event: 处理文件事件,接受它们发来的命令请求(读事件),并将命令的执行结果返 回给客户端(写事件))
Time Event: 时间事件(更新统计信息,清理过期数据,附属节点同步,定期持久化等)
AOF: 命令日志的数据持久化
RDB:实际的数据持久化
Lua Environment : Lua 脚本的运行环境. 为了让 Lua 环境符合 Redis 脚本功能的需求, Redis 对 Lua 环境进行了一系列的修改, 包括添加函数库、更换随机函数、保护全局变量 , 等等 Command table(命令表):在执行命令时,根据字符来查找相应命令的实现函数。
Share Objects(对象共享):主要存储常见的值: a.各种命令常见的返回值,例如返回值OK、ERROR、WRONGTYPE等字符; b. 小于 redis.h/REDIS_SHARED_INTEGERS (默认1000)的所有整数。通过预分配的一些 常见的值对象,并在多个数据结构之间共享对象,程序避免了重复分配的麻烦。也就是说 ,这些常见的值在内存中只有一份。
Databases: Redis数据库是真正存储数据的地方。当然,数据库本身也是存储在内存中的。
Redis的相关基本配置 - 程序环境:
配置文件:/etc/redis.conf
主程序:/usr/bin/redis-server
客户端:/usr/bin/redis-cli
Unit File: /usr/lib/systemd/system/redis.service
数据目录:/var/lib/redis
监听:6379/tcp - 配置文件
网络配置项
基本配置项
持久化相关配置
复制相关的配置
安全相关配置
Limit相关的配置
Cluster相关配置
SlowLog相关的配置
Advanced配置
Redis 命令介绍
redis-benchmark #redis性能测试工具,可以测试在本系统本配 置下的读写性能
redis-check-aof #对更新日志appendonly.aof检查,是否可用
redis-check-dump #用于检查本地数据库的rdb文件
redis-cli #redis命令行操作工具,也可以用telnet根据 其纯文本协议来操作默认选择 db库是 0 :redis-cli -p 6379 查看当前所在“db库”所有的缓存key: redis 127.0.0.1:6379> keys * 选择 db库: redis 127.0.0.1:6379> select 8 清除所有的缓存key: redis 127.0.0.1:6379> FLUSHALL 清除当前“db库”所有的缓存key: redis 127.0.0.1:6379[8]> FLUSHDB 设置缓存值: redis 127.0.0.1:6379> set keyname keyvalue 获取缓存值: redis 127.0.0.1:6379> get keyname 删除缓存值:返回删除数量(0代表没删除): redis 127.0.0.1:6379> del keyname time:返回当前服务器时间 client list: 返回所有连接到服务器的客户端信息和统计数据 参见 http://redisdoc.com/server/client_list.html client kill ip:port:关闭地址为 ip:port 的客户端 save:将数据同步保存到磁盘 bgsave:将数据异步保存到磁盘 lastsave:返回上次成功将数据保存到磁盘的Unix时戳 shundown:将数据同步保存到磁盘,然后关闭服务 info:提供服务器的信息和统计 config resetstat:重置info命令中的某些统计数据 config get:获取配置文件信息 config set:动态地调整 Redis 服务器的配置(configuration)而无须重启,可以修改的配置参数可以使用命令 CONFIG GET * 来列出 config rewrite:Redis 服务器时所指定的 redis.conf 文件进行改写 monitor:实时转储收到的请求 slaveof:改变复制策略设置 debug: sleep segfault slowlog get 获取慢查询日志 slowlog len 获取慢查询日志条数 slowlog reset 清空慢查询redis-sentinel Redis-sentinel 是Redis实例的监控管理、通知和 实例失效备援服务,是Redis集群的管理工具
redis-server #redis服务器的daemon启动程序
常用的数据类型
对key操作的命令:
exists(key):确认一个key是否存在
del(key):删除一个
key type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有
key randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
move(key, dbindex):移动当前数据库中的key到dbindex数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
数据类型:字符串(string),散列表(hash),列表(list),集合(set),有序集合(sorted set)。
各数据类型的应用场景: - string应用场景:String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类.即可以完全实现目前 Memcached 的功 能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get 、set、incr、decr 等操作外,Redis还提供了下面一些操作:
set(key, value):给数据库中名称为key的string赋予值value get(key):返回数据库中名称为key的string的value getset(key, value):给名称为key的string赋予上一次的value mget(key1, key2,…, key N):返回库中多个string的value setnx(key, value):添加string,名称为key,值为value setex(key, time, value):向库中添加string,设定过期时间time mset(key N, value N):批量设置多个string的值 msetnx(key N, value N):如果所有名称为key i的string都不存在 incr(key):名称为key的string增1操作 incrby(key, integer):名称为key的string增加integer decr(key):名称为key的string减1操作 decrby(key, integer):名称为key的string减少integer append(key, value):名称为key的string的值附加value substr(key, start, end):返回名称为key的string的value的子串 - hash 应用场景:在Memcached中,我们经常将一些结构化的信息打包成HashMap,在客户端序列化后存储为一个字符串的值, 比如用户的昵称、年龄、性别、积分等,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的 值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分) 。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。经常用于电子商务类平台的购物车场景中。
hset(key, field, value):向名称为key的hash中添加元素field hget(key, field):返回名称为key的hash中field对应的value hmget(key, (fields)):返回名称为key的hash中field i对应的value hmset(key, (fields)):向名称为key的hash中添加元素field hincrby(key, field, integer):将名称为key的hash中field的value增加integer hexists(key, field):名称为key的hash中是否存在键为field的域 hdel(key, field):删除名称为key的hash中键为field的域 hlen(key):返回名称为key的hash中元素个数 hkeys(key):返回名称为key的hash中所有键 hvals(key):返回名称为key的hash中所有键对应的value hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value - list应用场景:比如twitter的关注列表,粉丝列表
rpush(key, value):在名称为key的list尾添加一个值为value的元素 lpush(key, value):在名称为key的list头添加一个值为value的 元素 llen(key):返回名称为key的list的长度 lrange(key, start, end):返回名称为key的list中start至end之间的元素 ltrim(key, start, end):截取名称为key的list lindex(key, index):返回名称为key的list中index位置的元素 lset(key, index, value):给名称为key的list中index位置的元素赋值 lrem(key, count, value):删除count个key的list中值为value的元素 lpop(key):返回并删除名称为key的list中的首元素 rpop(key):返回并删除名称为key的list中的尾元素 blpop(key1, key2,… key N, timeout):lpop命令的block版本。 brpop(key1, key2,… key N, timeout):rpop的block版本。 rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部 - set 应用场景:比如QQ中共同好友
sadd(key, member):向名称为key的set中添加元素member srem(key, member) :删除名称为key的set中的元素member spop(key) :随机返回并删除名称为key的set中一个元素 smove(srckey, dstkey, member) :移到集合元素 scard(key) :返回名称为key的set的基数 sismember(key, member) :member是否是名称为key的set的元素 sinter(key1, key2,…key N) :求交集 sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合 sunion(key1, (keys)) :求并集 sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合 sdiff(key1, (keys)) :求差集 sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合 smembers(key) :返回名称为key的set的所有元素 srandmember(key) :随机返回名称为key的set的一个元素 - sorted set 应用场景:比如电商平台的评论列表,有按各种标签的权重先后排序。
zadd,zrange,zrem,zcard,zcount等Redis主从复制(主库写、从库读)
Redis的复制方式有两种,一种是主(master)-从(slave)模式,一种是从(slave)-从(slave)模式,因此Redis的复制 拓扑图会丰富一些,可以像星型拓扑,也可以像个有向无环。一个Master可以有多个slave主机,支持链式复制; Master以非阻塞方式同步数据至slave主机。
复制的优点:高可用、高性能和水平扩展性。
但是也同样存在一定的问题:数据一致性问题和读写分离问题。这两个问题,尤其是第一个问题是Redis服务实现一直在演变,致力于解决的一个问题:复制实时性和数据一致性矛盾 Redis提供了提高数据一致性的解决方案,一致性程度的增加虽然使得我能够更信任数据,但是更好的一致性方案通常伴随着性 能的损失,从而减少了吞吐量和服务能力。然而我们希望系统的性能达到最优,则必须要牺牲一致性的程度,因此Redis的复制 实时性和数据一致性是存在矛盾的。
复制过程原理:
1、slave向master发送sync命令。
2、master开启子进程来将dataset写入rdb文件,同时将子进程完成之前 接收到的写命令缓存起来。
3、子进程写完,父进程得知,开始将RDB文件发送给slave。 master发送完RDB文件,将缓存的命令也发给slave。 master增量的把写命令发给slave。
值得注意的是,当slave跟master的连接断开时,slave可以自动的重新连 接master,在redis2.8版本之前,每当slave进程挂掉重新连接master的 时候都会开始新的一轮全量复制。如果master同时接收到多个slave的同 步请求,则master只需要备份一次RDB文件。实验过程:
一、项目规划:
centos系统服务器4台、一台作为redis主,三台作为从节点,配置好yum源、防火墙关闭、各节点时钟服务同步、各节点之间可以通过主机名互相通信。
| 机器名称 | IP配置 | 服务角色 |
|---|---|---|
| redis-master01 | 192.168.42.150 | redis主 |
| redis-slave02 | 192.168.42.151 | redis从 |
| redis-slave03 | 192.168.42.152 | redis从 |
| redis-slave04 | 192.168.42.153 | redis从 |
二、安装redis,配置好基本配置
yum install redis
cp /etc/redis.conf{,.back}
vim redis.conf
daemonize yes
bind 0.0.0.0 #改为各个节点的IP 三.依照上面设定的从主机,在从主机配置文件中开启从配置(需要配置3台机器):
### REPLICATION ###
slaveof 192.168.42.150 6379 #主节点地址,
#masterauth #如果设置了访问认证就需要设定此项。
slave-server-stale-data yes #当slave与master连接断开或者slave正处于同步状态时,如果slave收到请求允许响应,no表示返回错误。
slave-read-only yes #slave节点是否为只读。
slave-priority 100 #设定此节点的优先级,是否优先被同步四、redis主从复制测试
set master-slave ok 五、高级配置
一个RDB文件从master端传到slave端,分为两种情况: 1、支持disk:master端将RDB file写到disk,稍后再传送到slave端; 2、无磁盘diskless:master端直接将RDB file传到slave socket,不需要与disk进行交互。 无磁盘diskless方式适合磁盘读写速度慢但网络带宽非常高的环境。
repl-diskless-sync no #默认不使用diskless同步方式
repl-diskless-sync-delay 5 #无磁盘diskless方式在进行数据传递之前会有一个时间的延迟,以便slave端能够进行到待传送 的目标队列中,这个时间默认是5秒
repl-ping-slave-period 10 #slave端向server端发送pings的时间区间设置,默认为10秒
repl-timeout 60 #设置超时时间
slave-priority 100 复制集群中,主节点故障时,sentinel应用场景中的主节点选举时使用的优先级;数字越小优先级越高,但0表示不参与选举;
min-slaves-to-write 3 #主节点仅允许其能够通信的从节点数量大于等于此处的值时接受写操作;
min-slaves-max-lag 10 #从节点延迟时长,超出此处指定的时长时,主节点会拒绝写入操作;利用sentinel 实现高可用的主从复制:
Sentinel是Redis的高可用性(HA)解决方案,由一个或多个Sentinel实例组成的Sentinel系统可以监视任意多个主服务器, 以及这些主服务器属下的所有从服务器,并在被监视的主服务器进行下线状态时,自动将下线主服务器属下的某个从服务器升级 为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。Redis提供的sentinel(哨兵)机制,通过 sentinel模式启动redis后,自动监控master/slave的运行状态,基本原理是:心跳机制+投票裁决
- 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送 通知。
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端 试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
只需在sentinel节点的配置文件中修改以下配置即可:vim /etc/redis-sentinel.conf port 26379 #sentinel announce-ip 1.2.3.4 #默认监听在0.0.0.0 所以此处可以注释。 dir “/tmp” sentinel monitor mymaster 192.168.1.29 6379 1 #sentinel moitor <法定人数 quorum> #设定master节点的名称和位置,法定人数表示多少台sentinel节点认同才可以上线。 表示sentinel集群的quorum机制,即至少有quorum个sentinel节点同时判定主节点故障时,才认为其真的故障 s_down: subjectively down o_down: objectively down sentinel down-after-milliseconds mymaster 5000 #如果联系不到节点5000毫秒,我们就认为此节点下线。 sentinel failover-timeout mymaster 60000 #设定转移主节点的目标节点的超时时长。 sentinel auth-pass #如果redis节点启用了auth,此处也要设置password。 sentinel parallel-syncs #指在failover过程中,能够被sentinel并行配置的从节点的数量;一些关于sentinel的命令:
redis-cli -h SENTINEL_HOST -p SENTINEL_PORT
sentinel masters #查看此复制集群的主节点信息。
sentinel slaves #查看此复制集群的从节点信息。
sentinel failover #切换指定的节点为节点为主节点。总结
NoSQL数据库的出现,弥补了关系数据(比如MySQL)在某些方面的不足,在某些方面能极大的节省开发成本和维护成本。
MySQL和NoSQL都有各自的特点和使用的应用场景,两者的紧密结合将会给web2.0的数据库发展带来新的思路。让关系数据库关注在关系上,NoSQL关注在功能、性能上。
随着移动互联网的发展,以及业务场景的多样化,社交元素的普遍化,Nosql从性能和功能上很好的补充了web2.0时代的原关系型数据的缺点,
目前已经是各大公司必备的技术之一。