动机
其实差不多半年之前就想吐槽Tensorflow的seq2seq了(后面博主去干了些别的事情),官方的代码已经抛弃原来用静态rnn实现的版本了,而官网的tutorial现在还是介绍基于静态的rnn的模型,加bucket那套,看这里。

看到了吗?是legacy_seq2seq的。本来Tensorflow的seq2seq的实现相比于pytorch已经很复杂了,还没有个正经的tutorial,哎。
好的,回到正题,遇到问题解决问题,想办法找一个 最佳的Tensorflow的seq2seq解决方案!
学习的资料
- 知名博主WildML给google写了个通用的seq2seq,文档地址,Github地址。这个框架已经被Tensorflow采用,后面我们的代码也会基于这里的实现。但本身这个框架是为了让用户直接写参数就能简单地构建网络,因此文档没有太多参考价值,我们直接借用其中的代码构建自己的网络。
- 俄罗斯小伙ematvey写的:tensorflow-seq2seq-tutorials,Github地址。介绍使用动态rnn构建seq2seq,decoder使用
raw_rnn,原理和WildML的方案差不多。多说一句,这哥们当时也是吐槽Tensorflow的文档,写了那么个仓库当第三方的文档使,现在都400+个star了。真是有漏洞就有机遇啊,哈哈。
Tensorflow的动态rnn
先来简单介绍动态rnn和静态rnn的区别。
tf.nn.rnn creates an unrolled graph for a fixed RNN length. That means, if you call tf.nn.rnn with inputs having 200 time steps you are creating a static graph with 200 RNN steps. First, graph creation is slow. Second, you’re unable to pass in longer sequences (> 200) than you’ve originally specified.tf.nn.dynamic_rnn solves this. It uses a tf.While loop to dynamically construct the graph when it is executed. That means graph creation is faster and you can feed batches of variable size.
摘自Whats the difference between tensorflow dynamic_rnn and rnn?。也就是说,静态的rnn必须提前将图展开,在执行的时候,图是固定的,并且最大长度有限制。而动态rnn可以在执行的时候,将图循环地的复用。
一句话,能用动态的rnn就尽量用动态的吧。
Seq2Seq结构分析
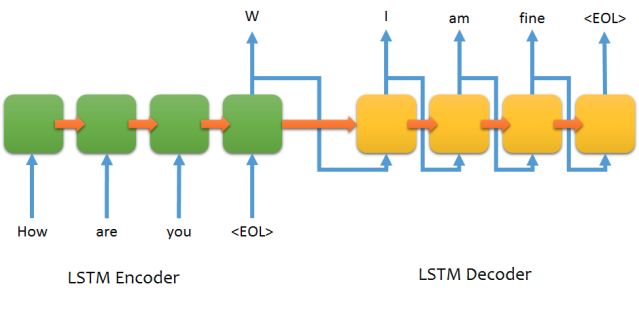
seq2seq由Encoder和Decoder组成,一般Encoder和Decoder都是基于RNN。Encoder相对比较简单,不管是多层还是双向或者更换具体的Cell,使用原生API还是比较容易实现的。难点在于Decoder:不同的Decoder对应的rnn cell的输入不同,比如上图的示例中,每个cell的输入是上一个时刻cell输出的预测对应的embedding。
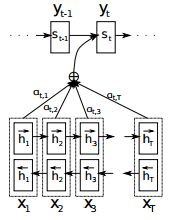
如果像上图那样使用Attention,则decoder的cell输入还包括attention加权求和过的context。
通过示例讲解
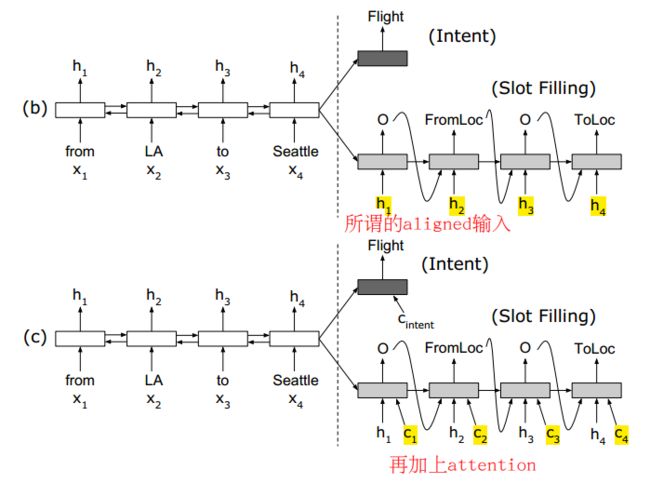
下面通过一个用seq2seq做slot filling(一种序列标注)的例子讲解。完整代码地址: https://github.com/applenob/RNN-for-Joint-NLU
Encoder的实现示例
# 首先构造单个rnn cell
encoder_f_cell = LSTMCell(self.hidden_size)
encoder_b_cell = LSTMCell(self.hidden_size)
(encoder_fw_outputs, encoder_bw_outputs),
(encoder_fw_final_state, encoder_bw_final_state) = \
tf.nn.bidirectional_dynamic_rnn(cell_fw=encoder_f_cell,
cell_bw=encoder_b_cell,
inputs=self.encoder_inputs_embedded,
sequence_length=self.encoder_inputs_actual_length,
dtype=tf.float32, time_major=True)
上面的代码使用了tf.nn.bidirectional_dynamic_rnn构建单层双向的LSTM的RNN作为Encoder。
参数:
-
cell_fw:前向的lstm cell -
cell_bw:后向的lstm cell -
time_major:如果是True,则输入需要是T×B×E,T代表时间序列的长度,B代表batch size,E代表词向量的维度。否则,为B×T×E。输出也是类似。
返回:
-
outputs:针对所有时间序列上的输出。 -
final_state:只是最后一个时间节点的状态。
一句话,Encoder的构造就是构造一个RNN,获得输出和最后的状态。
Decoder实现示例
下面着重介绍如何使用Tensorflow的tf.contrib.seq2seq实现一个Decoder。
我们这里的Decoder中,每个输入除了上一个时间节点的输出以外,还有对应时间节点的Encoder的输出,以及attention的context。
Helper
常用的Helper:
-
TrainingHelper:适用于训练的helper。 -
InferenceHelper:适用于测试的helper。 -
GreedyEmbeddingHelper:适用于测试中采用Greedy策略sample的helper。 -
CustomHelper:用户自定义的helper。
先来说明helper是干什么的:参考上面提到的俄罗斯小哥用raw_rnn实现decoder,需要传进一个loop_fn。这个loop_fn其实是控制每个cell在不同的时间节点,给定上一个时刻的输出,如何决定下一个时刻的输入。
helper干的事情和这个loop_fn基本一致。这里着重介绍CustomHelper,要传入三个函数作为参数:
-
initialize_fn:返回finished,next_inputs。其中finished不是scala,是一个一维向量。这个函数即获取第一个时间节点的输入。 -
sample_fn:接收参数(time, outputs, state)返回sample_ids。即,根据每个cell的输出,如何sample。 -
next_inputs_fn:接收参数(time, outputs, state, sample_ids)返回(finished, next_inputs, next_state),根据上一个时刻的输出,决定下一个时刻的输入。
BasicDecoder
有了自定义的helper以后,可以使用tf.contrib.seq2seq.BasicDecoder定义自己的Decoder了。再使用tf.contrib.seq2seq.dynamic_decode执行decode,最终返回:(final_outputs, final_state, final_sequence_lengths)。其中:final_outputs是tf.contrib.seq2seq.BasicDecoderOutput类型,包括两个字段:rnn_output,sample_id。
回到示例
# 传给CustomHelper的三个函数
def initial_fn():
initial_elements_finished = (0 >= decoder_lengths) # all False at the initial step
initial_input = tf.concat((sos_step_embedded, encoder_outputs[0]), 1)
return initial_elements_finished, initial_input
def sample_fn(time, outputs, state):
# 选择logit最大的下标作为sample
prediction_id = tf.to_int32(tf.argmax(outputs, axis=1))
return prediction_id
def next_inputs_fn(time, outputs, state, sample_ids):
# 上一个时间节点上的输出类别,获取embedding再作为下一个时间节点的输入
pred_embedding = tf.nn.embedding_lookup(self.embeddings, sample_ids)
# 输入是h_i+o_{i-1}+c_i
next_input = tf.concat((pred_embedding, encoder_outputs[time]), 1)
elements_finished = (time >= decoder_lengths) # this operation produces boolean tensor of [batch_size]
all_finished = tf.reduce_all(elements_finished) # -> boolean scalar
next_inputs = tf.cond(all_finished, lambda: pad_step_embedded, lambda: next_input)
next_state = state
return elements_finished, next_inputs, next_state
# 自定义helper
my_helper = tf.contrib.seq2seq.CustomHelper(initial_fn, sample_fn, next_inputs_fn)
def decode(helper, scope, reuse=None):
with tf.variable_scope(scope, reuse=reuse):
memory = tf.transpose(encoder_outputs, [1, 0, 2])
attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(
num_units=self.hidden_size, memory=memory,
memory_sequence_length=self.encoder_inputs_actual_length)
cell = tf.contrib.rnn.LSTMCell(num_units=self.hidden_size * 2)
attn_cell = tf.contrib.seq2seq.AttentionWrapper(
cell, attention_mechanism, attention_layer_size=self.hidden_size)
out_cell = tf.contrib.rnn.OutputProjectionWrapper(
attn_cell, self.slot_size, reuse=reuse
)
# 使用自定义helper的decoder
decoder = tf.contrib.seq2seq.BasicDecoder(
cell=out_cell, helper=helper,
initial_state=out_cell.zero_state(
dtype=tf.float32, batch_size=self.batch_size))
# 获取decode结果
final_outputs, final_state, final_sequence_lengths = tf.contrib.seq2seq.dynamic_decode(
decoder=decoder, output_time_major=True,
impute_finished=True, maximum_iterations=self.input_steps
)
return final_outputs
outputs = decode(my_helper, 'decode')
Attntion
上面的代码,还有几个地方没有解释:BahdanauAttention,AttentionWrapper,OutputProjectionWrapper。
先从简单的开始:OutputProjectionWrapper即做一个线性映射,比如之前的cell的ouput是T×B×D,D是hidden size,那么这里做一个线性映射,直接到T×B×S,这里S是slot class num。wrapper内部维护一个线性映射用的变量:W和b。
BahdanauAttention是一种AttentionMechanism,另外一种是:BahdanauMonotonicAttention。具体二者的区别,读者请自行深入调查。关键参数:
-
num_units:隐层维度。 -
memory:通常就是RNN encoder的输出 -
memory_sequence_length=None:可选参数,即memory的mask,超过长度数据不计入attention。
继续介绍AttentionWrapper:这也是一个cell wrapper,关键参数:
-
cell:被包装的cell。 -
attention_mechanism:使用的attention机制,上面介绍的。
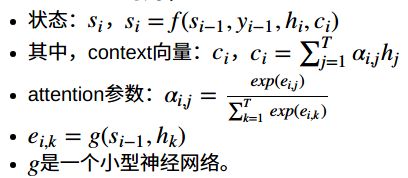
memory对应公式中的h,wrapper的输出是s。
那么一个AttentionWrapper具体的操作流程如何呢?看官网给的流程:

Loss Function
tf.contrib.seq2seq.sequence_loss可以直接计算序列的损失函数,重要参数:
-
logits:尺寸[batch_size, sequence_length, num_decoder_symbols] -
targets:尺寸[batch_size, sequence_length],不用做one_hot。 -
weights:[batch_size, sequence_length],即mask,滤去padding的loss计算,使loss计算更准确。
后记
这里只讨论了seq2seq在序列标注上的应用。seq2seq还广泛应用于翻译和对话生成,涉及到生成的策略问题,比如beam search。后面会继续研究。除了sample的策略,其他seq2seq的主要技术,本文已经基本涵盖,希望对大家踩坑有帮助。
完整代码:https://github.com/applenob/RNN-for-Joint-NLU