1、小知识点
(1) ctrl+/ :快速注释(或取消)
(2) 寻找数据路径:(python) data-找到所需数据-右键copy path-粘贴
(文件名不能为文字)
(3) Excel不能展示数据原貌,只是便于观看,所以用文本编辑器(如Sublime)导入数据可以处理(Excel表格中的表格→逗号(,))
2、代码详解
```
"""
程序开头注释
author: xingbuxing
date: 2018年01月28日
功能:本程序主要介绍pandas最最常用的一些方法。这些方法在之后的课程、作业中都会用到。
"""
```
import pandas as pd # 将pandas作为第三方库导入,我们一般为pandas取一个别名叫做pd
pd.set_option('expand_frame_repr', False) # 当列太多时不换行
# =====导入数据
df = pd.read_csv(
# 该参数为数据在电脑中的路径
filepath_or_buffer='E:\pythonliang\program\practice1.py',
# 该参数代表数据的分隔符,csv文件默认是逗号。其他常见的是'\t'
sep=',',
# 该参数代表跳过数据文件的的第1行不读入(如:可以跳过第一行的标题)
skiprows=1,
# nrows,只读取前n行数据,若不指定,读入全部的数据(可以输入少量数据进行调试,减少运行时间)
nrows=15,
# 将指定列的数据识别为日期格式。若不指定,时间数据将会以字符串形式读入。一开始先不用。
parse_dates=['candle_begin_time'],
# 将指定列设置为index。若不指定,index默认为0, 1, 2, 3, 4...
index_col=['candle_begin_time'],
# 读取指定的这几列数据,其他数据不读取。若不指定,读入全部列
usecols=['candle_begin_time', 'close'], (表示读取'candle_begin_time', 'close'这两列)
# 当某行数据有问题时,报错。设定为False时即不报错,直接跳过该行。当数据比较脏乱的时候用这个。
error_bad_lines=False,
# 将数据中的null识别为空值
na_values='NULL',
# 更多其他参数,请直接搜索"pandas read_csv",要去逐个查看一下。比较重要的,header等
)
print(df)
# 使用read_csv导入数据非常方便
# 导入的数据的数据类型是DataFrame。
# 导入数据主要使用read系列函数
# 还有read_table(如txt文件)、read_excel、read_json等,他们的参数内容都是大同小异,可以自行搜索查看。
3、补充
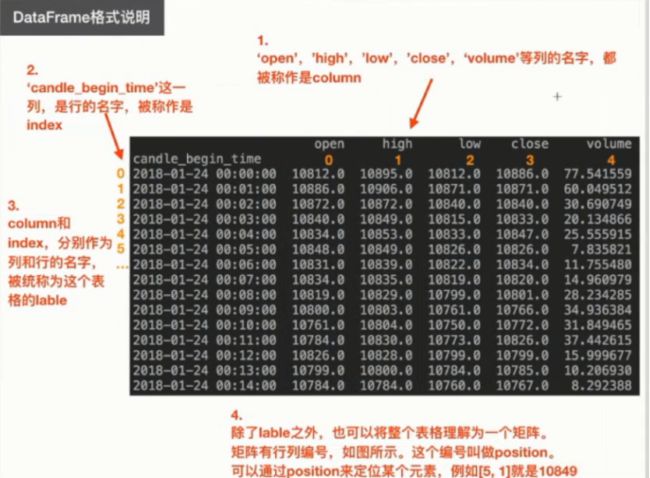
(1)DataFrame格式介绍: