管理进程状态
当程序运行为进程后,如果希望停止进程,怎么办呢? 那么此时我们可以使用linux的kill命令对进程发送关闭信号。当然除了kill、还有killall,pkill
1.使用kill -l列出当前系统所支持的信号
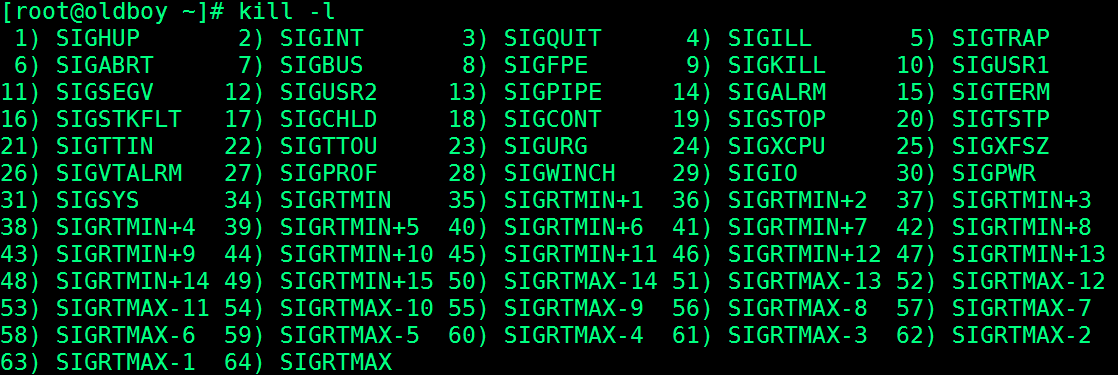
常用的三个信号
数字编号 信号含义 信号翻译
1 SIGHUP 通常用来重新加载配置文件
9 SIGKILL 强制杀死进程
15 SIGTERM 终止进程,默认kill使用该信号
1.使用kill命令杀死PID的进程
1.给 vsftpd 进程发送信号
[root@oldboy ~]# yum install vsftpd -y
[root@oldboy ~]# systemctl start vsftpd
[root@oldboy ~]# ps uax|grep vsftpd
2.重新加载vsftpd
[root@oldboy ~]# kill -1 2405
[root@oldboy ~]# psuax|grep vsftpd
3.发送停止信号
[root@oldboy ~]# kill 2405
[root@oldboy ~]# ps uax|grep vsftpd
[root@oldboy ~]# systemctl start vsftpd
[root@oldboy ~]# ps uax|grep vsftpd
4.发送强制停止信号,当无法停止服务时,可强制终止信号
[root@oldboy ~]# kill -9 2421
[root@oldboy ~]# ps uax|grep vsftpd
root 2429 0.0 0.0 112708 976 pts/2 R+ 13:43 0:00 grep --color=auto vsftpd
2.Linux系统中的killall、pkill命令用于杀死指定名字的进程。
通过服务名称杀掉进程
[root@oldboy ~]# pkill nginx
[root@oldboy ~]# killall nginx
使用pkill踢出从远程登录到本机的用户,终止pts/0上所有进程, 并且bash也结束(用户被强制退出)
[root@oldboy ~]# pkill -9 -t pts/0
管理进程kill、killall、pkill
kill PID 正常停止一个程序
kill -1 PID 平滑重载配置文件
kill -9 PID 强制杀死进程 (对于mysql这类有状态的慎用)
pkill Name 批量干掉程序
killall Name 批量干掉程序
管理后台进程
1.什么是后台进程
通常进程都会在终端前台运行,一旦关闭终端,进程也会随着结束,那么此时我们就希望进程能在后台运行,就是将在前台运行的进程放入后台运行,这样即使我们关闭了终端也不影响进程的正常运行。
2.我们为什么要将进程放入后台运行
比如:我们此前在国内服务器往国外服务器传输大文件时,由于网络的问题需要传输很久,如果在传输的过程中出现网络抖动或者不小心关闭了终端则会导致传输失败,如果能将传输的进程放入后台,就能解决此类问题了。
3.使用什么工具将进程放入后台
早期的时候选择使用&符号将进程放入后台,然后在使用jobs、bg、fg等方式查看进程状态,我们使用screen。
1.安装
[root@oldboy ~]# yum install screen -y
2.开启一个screen窗口,指定名称
[root@oldboy ~]# screen -S Linux
3.在screen窗口中执行任务即可
[root@oldboy ~]# wget https://mirrors.aliyun.com/centos/7.6.1810/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso
4.平滑的退出screen,但不会终止screen中的任务。注意: 如果使用exit 才算真的关闭screen窗口
ctrl+a+d
[detached from 2730.Linux]
5.查看当前正在运行的screen有哪些
[root@oldboy ~]# screen -list
There are screens on:
2730.Linux (Detached)
6.进入正在运行的screen
[root@oldboy ~]# screen -r 2730
[root@oldboy ~]# screen -r Linux
后台进程该如何管理jobs bg fg screen?
screen -S Name
Ctrl+ad 关闭会话
screen -list ---> screen -r Name| pid
进程的优先级
什么是优先级?
优先级指的是优先享受资源。
系统中如何给进程配置优先级?
在启动进程时,为不同的进程使用不同的调度策略。
nice 值越高: 表示优先级越低,例如+19,该进程容易将CPU 使用量让给其他进程。
nice 值越低: 表示优先级越高,例如-20,该进程更不倾向于让出CPU。
1.使用top查看nice优先级
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
908 root 20 0 300824 6328 4972 S 0.3 0.3 0:28.45 vmtoolsd
1 root 20 0 193828 6840 4132 S 0.0 0.3 0:05.45 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.05 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:03.44 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:00.78 kworker/u256:0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 S 0.0 0.0 0:02.23 rcu_sched
10 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 lru-add-drain
2.使用ps查看进程优先级
[root@oldboy ~]# ps axo command,nice
|grep ssh|grep -v grep
/usr/sbin/sshd -D 0
sshd: root@pts/0 0
[root@oldboy ~]#
nice优先级
1.开启vim并且指定程序优先级为-5
[root@oldboy ~]#nice -n -5 vim old
2.查看该进程的优先级情况
[root@oldboy ~]# ps aux|grep vim
root 3058 0.3 0.2 151516 5220 pts/5 S<+ 16:18 0:00 vim old
root 3060 0.0 0.0 112708 972 pts/1 S+ 16:18 0:00 grep --color=auto
vim
3.退出后优先级消失
[root@oldboy ~]# ps aux|grep vim
root 3065 0.0 0.0 112708 976 pts/1 R+ 16:20 0:00 grep --color=auto
vim
renice优先级
1.查看当前sshd进程当前的优先级状态
[root@oldboy ~]# ps axo pid,command,nice|grep ssh
1441 /usr/sbin/sshd -D 0
3037 sshd: root@pts/1 0
3115 sshd: root@pts/0 0
3139 grep --color=auto ssh 0
2.调整sshd主进程的优先级
[root@oldboy ~]# renice -n -20 -p 1441
1441 (process ID) old priority 0, new priority -20
3.调整之后记得退出终端
[root@oldboy ~]# ps axo pid,command,nice|grep ssh
1441 /usr/sbin/sshd -D -20
3037 sshd: root@pts/1 0
3115 sshd: root@pts/0 0
3143 grep --color=auto ssh 0
4.退出后重新登录
[root@oldboy ~]# ps axo pid,command,nice|grep ssh
1441 /usr/sbin/sshd -D -20
3115 sshd: root@pts/0 0
3145 sshd: root@pts/1 -20
3168 grep --color=auto ssh -20
[root@oldboy ~]# renice -n 19 -p 1441
1441 (process ID) old priority -20, new priority 19
[root@oldboy ~]# ps axo pid,command,nice|grep ssh
1441 /usr/sbin/sshd -D 19
3115 sshd: root@pts/0 0
3145 sshd: root@pts/1 -20
3173 grep --color=auto ssh 0
调整以后
[root@oldboy ~]# ps aux|grep sshd
root 1441 0.0 0.2 112864 4332 ? SNs 10:58 0:00 /usr/sbin/sshd -D
root 3115 0.1 0.2 158868 5580 ? Ss 16:39 0:00 sshd: root@pts/0
root 3145 0.2 0.2 158868 5576 ? S重新连接
[root@oldboy ~]# ps aux|grep sshd
root 1441 0.0 0.2 112864 4332 ? SNs 10:58 0:00 /usr/sbin/sshd -D
root 3115 0.1 0.2 158868 5580 ? Ss 16:39 0:00 sshd: root@pts/0
root 3177 3.3 0.2 158868 5584 ? SNs 16:49 0:00 sshd: root@pts/1
root 3199 0.0 0.0 112708 976 pts/1 RN+ 16:49 0:00 grep --color=auto
sshd
服务器假死;
什么是假死现象
所谓假死,就是能ping通,但是ssh登不上去,任何其他操作也没反应。
建议使用nice命令将sshd的进程优先级调高,这样当系统内存紧张时,还能勉强登录服务器
进行调试,分析故障。
进程优先级是什么?nice、renice? 服务器假死?
优先体验
银行 | 买票 |
nice值越高:表示优先级越低,例如+19该进程容易将CPU 使
用量让给其他进程。
nice 值越低: 表示优先级越高,例如-20,该进程更不倾向于
让出CPU。
NI =0 PR=20
NI =-20 PR=0
NI = 10 PR=30
NI = 19 PR =39
[root@oldboy ~]# nice -n Number 启动一个程序为其设定优先级
[root@oldboy ~]# renice 调整已经启动过的进程优先级
平均负载
平均负载其实就是单位时
间内的活跃进程数。(处于运行+处于等待运行+不可中断的进程)
[root@oldboy ~]# uptime
17:17:41 up 6:19, 3 users, load average: 0.00, 0.01, 0.05
最后三个数字呢,依次则是过去 1 分钟、5 分钟、15 分钟的平均负载(Load Average)
平均负载为多少时合理
最理想的状态是每个 CPU 上都刚好运行着一个进程,这样每个 CPU 都得到了充分利用。所以在
评判平均负载时,首先你要知道系统有几个 CPU,这可以通过 top 命令获取,也可以使用
grep 'model name' /proc/cpuinfo
假设现在在 4、2、1核的CPU上,如果平均负载为 2 时,意味着什么呢?
Q1.在4 个 CPU 的系统上,意味着 CPU 有 50% 的空闲。
Q2.在2 个 CPU 的系统上,意味着所有的 CPU 都刚好被完全占用。
Q3.而1 个 CPU 的系统上,则意味着有一半的进程竞争不到 CPU。
假设我们在有2个 CPU 系统上看到平均负载为 2.73,6.90,12.98
那么说明在过去1 分钟内,系统有 136% 的超载 (2.73/2=136%)
而在过去 5 分钟内,有 345% 的超载 (6.90/2=345%)
而在过去15 分钟内,有 649% 的超载,(12.98/2=649%)
但从整体趋势来看,系统的负载是在逐步的降低。
实际生产环境中,我们应该把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的
变化趋势。
平均负载与 CPU 使用率有什么关系
平均负载是指单位时间内,处于可运行状态和不可中断状态的进程数。所以,它不仅包括了正在
使用 CPU 的进程,还包括等待 CPU 和等待 I/O 的进程。
而 CPU 使用率,是单位时间内 CPU 繁忙情况的统计,跟平均负载并不一定完全对应。比如:
CPU 密集型进程,使用大量 CPU 会导致平均负载升高,此时这两者是一致的;
I/O 密集型进程,等待 I/O 也会导致平均负载升高,但 CPU 使用率不一定很高;
大量等待 CPU 的进程调度也会导致平均负载升高,此时的 CPU 使用率也会比较高。
一,CPU密集型进程
1.首先,我们在第一个终端运行 stress 命令,模拟一个 CPU 使用率 100% 的场景:
[root@oldboy ~]# stress --cpu 2 --timeout 600
2.接着,在第二个终端运行 uptime 查看平均负载的变化情况使用watch -d 参数表示高亮显示变化的区域(注意负载会持续升高
[root@oldboy ~]# watch -d uptime
3.最后,在第三个终端运行 mpstat 查看 CPU 使用率的变化情况 -P ALL 表示监控所有 CPU,后面数字 5 表示间隔 5 秒后输出一组数据
[root@oldboy ~]# mpstat -P ALL 5
Linux 3.10.0-957.27.2.el7.x86_64 (oldboy) 08/22/2019 _x86_64_ (1 CPU)
06:00:39 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
06:00:44 PM all 0.00 99.80 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00
06:00:44 PM 0 0.00 99.80 0.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00
4.从终端二中可以看到,1 分钟的平均负载会慢慢增加到 1.00,而从终端三中还可以看到,正好有一个 CPU 的使用率为 100%,但它的 iowait 只有 0。这说明,平均负载的升高正是由于 CPU 使用率为 100% 。那么,到底是哪个进程导致了 CPU 使用率为 100% 呢?可以使用 pidstat 来查询间隔 5 秒后输出一组数据
[root@oldboy ~]# pidstat -u 5 1
Linux 3.10.0-957.27.2.el7.x86_64 (oldboy) 08/22/2019 _x86_64_ (1 CPU)
06:44:13 PM UID PID %usr %system %guest %CPU CPU Command
06:44:18 PM 0 908 0.00 0.20 0.00 0.20 0 vmtoolsd
06:44:18 PM 0 3502 0.00 0.20 0.00 0.20 0 kworker/0:0
06:44:18 PM 0 3519 32.87 0.00 0.00 32.87 0 stress
06:44:18 PM 0 3520 33.07 0.00 0.00 33.07 0 stress
场景二:I/O 密集型进程
1.首先还是运行 stress 命令,但这次模拟 I/O 压力,即不停地执行 sync
[root@oldboy ~]# stress --io 1 --timeout 600s
2.然后在第二个终端运行 uptime 查看平均负载的变化情况:
[root@oldboy ~]# watch -d uptime
3.最后第三个终端运行 mpstat 查看 CPU 使用率的变化情况:显示所有 CPU 的指标,并在间隔 5 秒输出一组数据
[root@oldboy ~]# mpstat -P ALL 5
Linux 3.10.0-957.27.2.el7.x86_64 (oldboy) 08/22/2019 _x86_64_ (1 CPU)
06:49:59 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
06:50:04 PM all 0.80 0.60 97.80 0.00 0.00 0.20 0.00 0.00 0.00 0.60
06:50:04 PM 0 0.80 0.60 97.80 0.00 0.00 0.20 0.00 0.00 0.00 0.60
4.那么到底是哪个进程,导致 iowait 这么高呢?我们还是pidstat 来查询间隔 5 秒后输出一组数据,-u 表示 CPU 指标
[root@oldboy ~]# pidstat -u 5 1
Linux 3.10.0-957.27.2.el7.x86_64 (oldboy) 08/22/2019 _x86_64_ (1 CPU)
06:51:37 PM UID PID %usr %system %guest %CPU CPU Command
06:51:42 PM 0 9 0.00 0.20 0.00 0.20 0 rcu_sched
06:51:42 PM 0 2631 0.00 6.93 0.00 6.93 0 kworker/u256:1
06:51:42 PM 0 3233 0.00 9.90 0.00 9.90 0 kworker/u256:0
06:51:42 PM 0 3502 0.00 0.20 0.00 0.20 0 kworker/0:0
06:51:42 PM 0 3529 0.20 81.78 0.00 81.98 0 stress
大量进程的场景
当系统中运行进程超出 CPU 运行能力时,就会出现等待 CPU 的进程。
1.首先,我们还是使用 stress,但这次模拟的是 4 个进程
[root@oldboy ~]# stress -c 4 --timeout 600
2.由于系统只有 1 个 CPU,明显比 4 个进程要少得多,因而,系统的 CPU 处于严重过载状态
[root@oldboy ~]# watch -d uptime
3.然后,再运行 pidstat 来看一下进程的情况:间隔 5 秒后输出一组数据
[root@oldboy ~]# pidstat -u 5 1
Linux 3.10.0-957.27.2.el7.x86_64 (oldboy) 08/22/2019 _x86_64_ (1 CPU)
06:56:22 PM UID PID %usr %system %guest %CPU CPU Command
06:56:27 PM 0 1 0.00 0.20 0.00 0.20 0 systemd
06:56:27 PM 0 9 0.00 0.20 0.00 0.20 0 rcu_sched
06:56:27 PM 0 3630 26.22 0.00 0.00 26.22 0 stress
06:56:27 PM 0 3631 25.00 0.00 0.00 25.00 0 stress
06:56:27 PM 0 3632 25.20 0.00 0.00 25.20 0 stress
06:56:27 PM 0 3633 25.00 0.00 0.00 25.00 0 stress
06:56:27 PM 0 3652 0.00 0.20 0.00 0.20 0 pidstat
归纳一下平均负载与CPU
平均负载提供了一个快速查看系统整体性能的手段,反映了整体的负载情况。但只看平均负载本身,我们并不能直接发现,到底是哪里出现了瓶颈。所以,在理解平均负载时,也要注意:
平均负载高有可能是 CPU 密集型进程导致的;
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了;
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源