摘要: 原创出处:www.bysocket.com 泥瓦匠BYSocket 希望转载,保留摘要,谢谢!
“清醒时做事,糊涂时跑步,大怒时睡觉,独处时思考”
本文提纲
一、多数据源的应用场景
二、运行 springboot-mybatis-mutil-datasource 工程案例
三、springboot-mybatis-mutil-datasource 工程代码配置详解
一、多数据源的应用场景
目前,业界流行的数据操作框架是 Mybatis,那 Druid 是什么呢?
Druid 是 Java 的数据库连接池组件。Druid 能够提供强大的监控和扩展功能。比如可以监控 SQL ,在监控业务可以查询慢查询 SQL 列表等。Druid 核心主要包括三部分:
1. DruidDriver 代理 Driver,能够提供基于 Filter-Chain 模式的插件体系。
2. DruidDataSource 高效可管理的数据库连接池
3. SQLParser
当业务数据量达到了一定程度,DBA 需要合理配置数据库资源。即配置主库的机器高配置,把核心高频的数据放在主库上;把次要的数据放在从库,低配置。开源节流嘛,就这个意思。把数据放在不同的数据库里,就需要通过不同的数据源进行操作数据。这里我们举个 springboot-mybatis-mutil-datasource 工程案例:
user 用户表在主库 master 上,地址表 city 在从库 cluster 上。下面实现获取 根据用户名获取用户信息,包括从库的地址信息 REST API,那么需要从主库和从库中分别获取数据,并在业务逻辑层组装返回。逻辑如图:
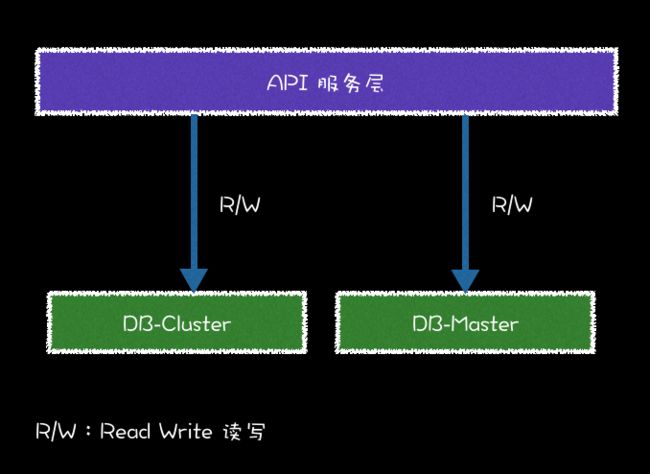
下面就运行这个案例。
二、运行 springboot-mybatis-mutil-datasource 工程案例
git clone 下载工程 springboot-learning-example ,项目地址见 GitHub – https://github.com/JeffLi1993/springboot-learning-example。下面开始运行工程步骤(Quick Start):
1.数据库准备
a.创建 cluster 数据库 springbootdb:
CREATE DATABASE springbootdb;
b.创建表 city :(因为我喜欢徒步)
DROP TABLE IF EXISTS `city`;
CREATE TABLE `city` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT'城市编号',
`province_id` int(10) unsigned NOT NULL COMMENT'省份编号',
`city_name` varchar(25) DEFAULT NULL COMMENT'城市名称',
`description` varchar(25) DEFAULT NULL COMMENT'描述',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
c.插入数据
INSERT city VALUES (1 ,1,'温岭市','BYSocket 的家在温岭。');
然后,再创建一个 master 数据库
a.创建数据库 springbootdb_cluster:
CREATE DATABASE springbootdb_cluster;
b.创建表 user :
DROP TABLE IF EXISTS `city`;
CREATE TABLE user
(
idINT(10) unsigned PRIMARY KEY NOT NULL COMMENT'用户编号'AUTO_INCREMENT,
user_name VARCHAR(25) COMMENT'用户名称',
description VARCHAR(25) COMMENT'描述'
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
c.插入数据
INSERT user VALUES (1 ,’泥瓦匠','他有一个小网站 bysocket.com');
(以上数据库创建无先后顺序)
2. 项目结构介绍
项目结构如下图所示:
org.spring.springboot.config.ds – 配置层,这里是数据源的配置,包括 master 和 cluster 的数据源配置
org.spring.springboot.controller – Controller 层
org.spring.springboot.dao – 数据操作层 DAO,细分了 master 和 cluster 包下的 DAO 操作类
org.spring.springboot.domain – 实体类
org.spring.springboot.service – 业务逻辑层
Application – 应用启动类
application.properties – 应用配置文件,应用启动会自动读取配置
3.改数据库配置
打开 application.properties 文件, 修改相应的主从数据源配置,比如数据源地址、账号、密码等。(如果不是用 MySQL,自行添加连接驱动 pom,然后修改驱动名配置。)
4.编译工程
在项目根目录 springboot-learning-example,运行 maven 指令:
mvn cleaninstall
5.运行工程
右键运行 Application 应用启动类(位置:/springboot-learning-example/springboot-mybatis-mutil-datasource/src/main/java/org/spring/springboot/Application.java)的 main 函数,这样就成功启动了 springboot-mybatis-mutil-datasource 案例。
在浏览器打开:
http://localhost:8080/api/user?userName=泥瓦匠
浏览器返回 JSON 结果:
{
"id": 1,
"userName":"泥瓦匠",
"description":"他有一个小网站 bysocket.com",
"city": {
"id": 1,
"provinceId": 1,
"cityName":"温岭市",
"description":"BYSocket 的家在温岭。"
}
}
这里 city 结果体来自 cluster 库,user 结果体来自 master 库。
三、springboot-mybatis-mutil-datasource 工程代码配置详解
代码共享在我的GitHub上:
https://github.com/JeffLi1993/springboot-learning-example/tree/master/springboot-mybatis-mutil-datasource
首先代码工程结构如下:
org.spring.springboot.config.ds 包包含了多数据源的配置,同样有第三个数据源,按照前几个复制即可
resources/mapper 下面有两个模块,分别是 Mybatis 不同数据源需要扫描的 mapper xml 目录
├── pom.xml
└── src
└── main
├── java
│ └── org
│ └── spring
│ └── springboot
│ ├── Application.java
│ ├── config
│ │ └── ds
│ │ ├── ClusterDataSourceConfig.java
│ │ └── MasterDataSourceConfig.java
│ ├── controller
│ │ └── UserRestController.java
│ ├── dao
│ │ ├── cluster
│ │ │ └── CityDao.java
│ │ └── master
│ │ └── UserDao.java
│ ├── domain
│ │ ├── City.java
│ │ └── User.java
│ └── service
│ ├── UserService.java
│ └── impl
│ └── UserServiceImpl.java
└── resources
├── application.properties
└── mapper
├── cluster
│ └── CityMapper.xml
└── master
└── UserMapper.xml
1. 依赖 pom.xml
Mybatis 通过 Spring Boot Mybatis Starter 依赖
Druid 是数据库连接池依赖
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4.0.0
springboot
springboot-mybatis-mutil-datasource
0.0.1-SNAPSHOT
springboot-mybatis-mutil-datasource :: Spring Boot 实现 Mybatis 多数据源配置
org.springframework.boot
spring-boot-starter-parent
1.5.1.RELEASE
1.2.0
5.1.39
1.0.18
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-test
test
org.mybatis.spring.boot
mybatis-spring-boot-starter
${mybatis-spring-boot}
mysql
mysql-connector-java
${mysql-connector}
com.alibaba
druid
${druid}
junit
junit
4.12
2. application.properties 配置两个数据源配置
数据源配置会被数据源数据源配置如下
## master 数据源配置
master.datasource.url=jdbc:mysql://localhost:3306/springbootdb?useUnicode=true&characterEncoding=utf8
master.datasource.username=root
master.datasource.password=123456
master.datasource.driverClassName=com.mysql.jdbc.Driver
## cluster 数据源配置
cluster.datasource.url=jdbc:mysql://localhost:3306/springbootdb_cluster?useUnicode=true&characterEncoding=utf8
cluster.datasource.username=root
cluster.datasource.password=123456
cluster.datasource.driverClassName=com.mysql.jdbc.Driver
3. 数据源配置
多数据源配置的时候注意,必须要有一个主数据源,即 MasterDataSourceConfig 配置:
@Configuration
//扫描 Mapper 接口并容器管理
@MapperScan(basePackages = MasterDataSourceConfig.PACKAGE, sqlSessionFactoryRef ="masterSqlSessionFactory")
public class MasterDataSourceConfig {
//精确到 master 目录,以便跟其他数据源隔离
static final String PACKAGE ="org.spring.springboot.dao.master";
static final String MAPPER_LOCATION ="classpath:mapper/master/*.xml";
@Value("${master.datasource.url}")
private String url;
@Value("${master.datasource.username}")
private String user;
@Value("${master.datasource.password}")
private String password;
@Value("${master.datasource.driverClassName}")
private String driverClass;
@Bean(name ="masterDataSource")
@Primary
public DataSource masterDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
returndataSource;
}
@Bean(name ="masterTransactionManager")
@Primary
public DataSourceTransactionManager masterTransactionManager() {
returnnew DataSourceTransactionManager(masterDataSource());
}
@Bean(name ="masterSqlSessionFactory")
@Primary
public SqlSessionFactory masterSqlSessionFactory(@Qualifier("masterDataSource") DataSource masterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(masterDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(MasterDataSourceConfig.MAPPER_LOCATION));
returnsessionFactory.getObject();
}
}
@Primary 标志这个 Bean 如果在多个同类 Bean 候选时,该 Bean 优先被考虑。「多数据源配置的时候注意,必须要有一个主数据源,用 @Primary 标志该 Bean」
@MapperScan 扫描 Mapper 接口并容器管理,包路径精确到 master,为了和下面 cluster 数据源做到精确区分
@Value 获取全局配置文件 application.properties 的 kv 配置,并自动装配
sqlSessionFactoryRef 表示定义了 key ,表示一个唯一 SqlSessionFactory 实例
同理可得,从数据源 ClusterDataSourceConfig 配置如下:
@Configuration
//扫描 Mapper 接口并容器管理
@MapperScan(basePackages = ClusterDataSourceConfig.PACKAGE, sqlSessionFactoryRef ="clusterSqlSessionFactory")
public class ClusterDataSourceConfig {
//精确到 cluster 目录,以便跟其他数据源隔离
static final String PACKAGE ="org.spring.springboot.dao.cluster";
static final String MAPPER_LOCATION ="classpath:mapper/cluster/*.xml";
@Value("${cluster.datasource.url}")
private String url;
@Value("${cluster.datasource.username}")
private String user;
@Value("${cluster.datasource.password}")
private String password;
@Value("${cluster.datasource.driverClassName}")
private String driverClass;
@Bean(name ="clusterDataSource")
public DataSource clusterDataSource() {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(user);
dataSource.setPassword(password);
returndataSource;
}
@Bean(name ="clusterTransactionManager")
public DataSourceTransactionManager clusterTransactionManager() {
returnnew DataSourceTransactionManager(clusterDataSource());
}
@Bean(name ="clusterSqlSessionFactory")
public SqlSessionFactory clusterSqlSessionFactory(@Qualifier("clusterDataSource") DataSource clusterDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(clusterDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(ClusterDataSourceConfig.MAPPER_LOCATION));
returnsessionFactory.getObject();
}
}
上面数据配置分别扫描 Mapper 接口,org.spring.springboot.dao.master(对应 xml classpath:mapper/master ) 和 org.spring.springboot.dao.cluster(对应 xml classpath:mapper/cluster ) 包中对应的 UserDAO 和 CityDAO 。
都有 @Mapper 标志为 Mybatis 的并通过容器管理的 Bean。Mybatis 内部会使用反射机制运行去解析相应 SQL。
3.业务层 biz
biz 照常注入了两个 DAO,如同以前一样正常工作。不用关心和指定到具体说明数据源。
/**
* 用户业务实现层
*
* Created by bysocket on 07/02/2017.
*/
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;//主数据源
@Autowired
private CityDao cityDao;//从数据源
@Override
public User findByName(String userName) {
User user = userDao.findByName(userName);
City city = cityDao.findByName("温岭市");
user.setCity(city);
returnuser;
}
}
四、小结
多数据源适合的场景很多。不同的 DataSource ,不同的 SqlSessionFactory 和 不同的 DAO 层,在业务逻辑层做 整合。总结的架构图如下:
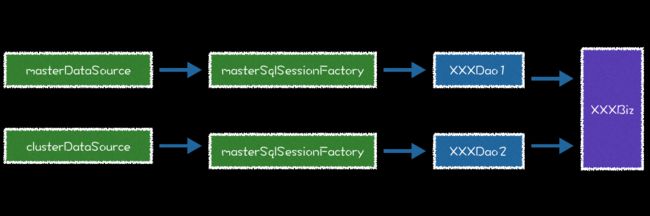
同样,如果实战中,大家遇到什么,或者建议《Spring boot 那些事》还需要一起交流的。请点击留言。
推荐书《奥黛丽·赫本》一本讲女神的故事。
欢迎扫一扫我的公众号关注 — 及时得到博客订阅哦!
— http://www.bysocket.com/ —
— https://github.com/JeffLi1993 —
