Attention机制源于对Seq2Seq模型的几个问题优化。Seq2Seq是基于Encoder-Decoder架构思想实现。Encoder和Decoder部分都是采用RNN网络模型。Seq2Seq模型存在的几个问题是:
1. 基于序列化的RNN网络, 无法做到并行计算, 模型的运行效率比较差。
- 输入X的信息转换为固定长度的context vector Z,当输入句子长度很长,固定长度的context vector很难表达所有X的信息,模型的性能急剧下降。而且对于每个词都赋予相同的权重,这样做是不合理的。
并行化方面优化:FaceBook提出CNN Seq2Seq模型,采用堆叠的CNN来替代RNN构建Encoder和Decoder。因为CNN可以实现并行,从而提升模型的运行效率。
固定长度的隐藏向量Z问题:解决的方法就是本文的主题Attention机制。 模型计算时,对不同输入端的数据采用不同的权重, 让模型可以关注关键而重点的信息,从而得到更加准确的结果。
一、Attention经典架构

1.Encoder hidden状态计算:
Encoder hidden状态:ht = RNN(Xt, ht-1), 前一个状态隐藏变量ht-1, 输入Xt, 通过RNN 计算单元得到ht.
2. Attention部分:计算Decoder Si 对应的context vector Ci
计算Decoder hidden state位置 i 与Encoder端所有hidden state加权平均值, 得到context vector Ci.
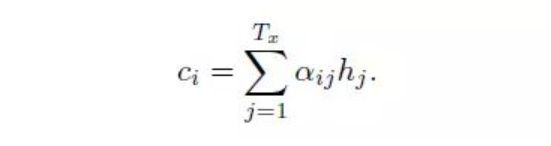
aij表示Decoder 位置i和Encoder 位置j 对应的权重值,表示源端第j个词对目标端第i个词的影响程度,计算方式类似softmax。
eij表示Decoder hidden states si-1 和Encoder hidden states hj 对应的分数值。

score分数计算方法有多种:包括dot乘,矩阵乘法,concat连接。ht是Encoder端hidden states, hs是Decoder端的hidden state.

3. Decoder hidden state计算
与输入端类似, St = RNN(Yt-1^, St-1, Ci), Decoder端前一个状态隐藏变量St-1, Decoder端输入Yt-1^, Context向量Ci通过RNN计算单元得到St.
4. Decoder端输出结果
计算方式如下,
二、Attention的类型

2.1 按权值计算范围来分
Soft Attention和Hard Attention
softAttention 是应用最广泛的一种方式, 计算Attention的权值aij, 每个Decoder hidden state Si 会用到所有Encoder端的hi向量。而且SoftAttetion部分能参与模型梯度反向传播中。
而Hard Attention是随机选取Encoder端的隐状态hi来参与aij的计算,而不是整个encoder的隐状态。为了实现梯度的反向传播,需要采样方法来估计一个梯度进行统一更新。
Local Attention和Global Attention
Global Attention 和soft Attetion类似,都是会用到所以Encoder端的隐状态。
****Local Attention(结构如下图)首先会为decoder端当前的词,预测一个source端对齐位置(aligned position)pt,然后基于pt选择一个窗口,用于计算context向量ct。****
Self Attention
Self Attention不同在于:不是通过Encoder端和Decoder端的隐变量(hidden state)计算Attention的,而是先分别在Encoder端、Decoder端计算内部词与词之间的相关关系,再将Encoder端的信息传递到Decoder端进行计算, 得到Encoder端和Decoder端词之间得依赖关系。
2.2 按Attention得组合方式
以下几种Attention都比较复杂, 本文只做简单介绍,后续针对每个再做详细介绍。
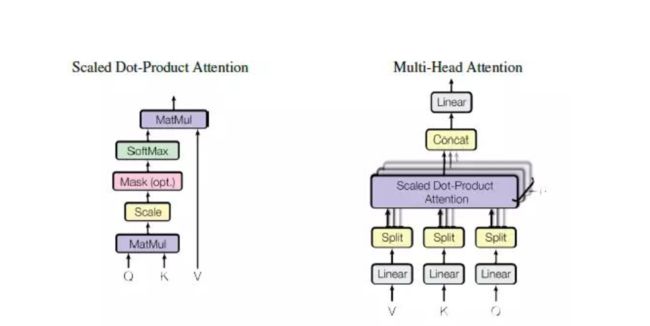
Multi-Head Attention
来自google的大作《Attention is all you need》,如下图所示,将多个Scaled Dot-product Attetion作为block组合起来使用。
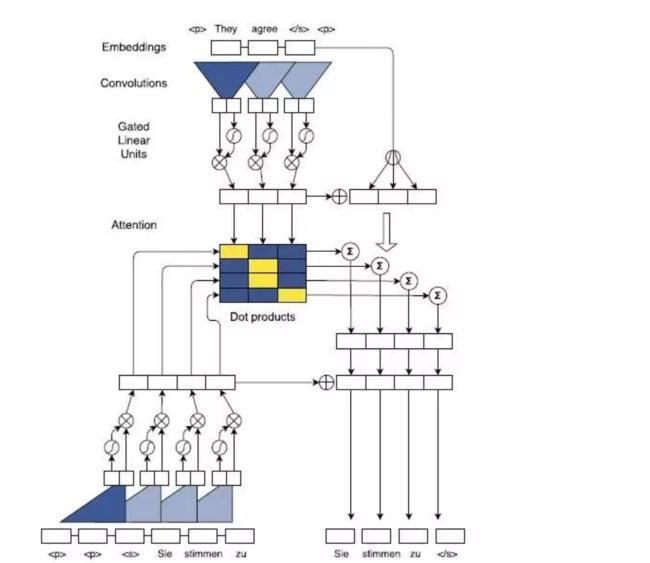
Multi-Step Attention
来自FaceBook的另一大作《Convolutional Sequence to Sequence Learning》,用CNN替代RNN作为Seq2Seq Encoder和Decoder的架构实现。
Hierarchical Attention
也就是多层Attention,比如文档的分类。 先通过第一层Attention参与词级别的向量组合成句子级别的向量。再通过第二层Attention, 参与句子向量级别的计算出文档的向量。
其他类型
未完待补充....
【参考文献】
深度学习中Attention Mechanism详细介绍:原理、分类及应用https://zhuanlan.zhihu.com/p/31547842
Attention用于NLP的一些小结 https://zhuanlan.zhihu.com/p/35739040