内容概括: 这次笔记记录Zookeeper的安装配置(在分布式环境中主要是完成对hadoop 的name node 和 Hbase ),Hbase的使用配置。当这些配置完成再使用eclipse创建一个demo来操作Hbase。
对于hadoop hdfs的配置和jdk请参考前面的笔记。这里还是基于前面的伪分布式hdfs来配置Hbase。
一 Zookeeper的安装:
Zookeeper 属于管理集群的工具,这里参考IBM里面的一篇文章简单列出Zookeeper的几个主要功能:
- 统一命名服务(Name Service)
- 配置管理(Configuration Management)
- 集群管理(Group Membership)
- 共享锁(Locks)
- 队列管理
这里只是描述单机模式,只是用来替换Hbase内置的Zookeeper而已,所以并没有什么作用只是用作了解,至于上面所提到的功能和分布式模式将在后面学习hadoop 高可用分布式时介绍。
配置和启动Zookeeper:
#Zookeeper默认情况下就是单机模式,只需要把配置文件的名称改为正式使用的配置文件名称就可以启动。
#下载Zookeeper,地址:http://www.apache.org/dyn/closer.cgi/zookeeper/
#我下载的是zookeeper-3.4.8.tar.gz并上传到安装hadoop的同一个目录中(/usr/local/)。
$ cd /usr/local/
$ ls
bin games include lib64 sbin src
etc hadoop lib libexec share zookeeper-3.4.8.tar.gz
#解压Zookeeper到当前目录,因为当前用户是hadoop没有对/usr/local有操作权限所以需要使用sudo获得管理员权限
$ sudo tar -zxf zookeeper-3.4.8.tar.gz -C .
#重命名zookeeper-3.4.8 为zookeeper
$ sudo mv zookeeper-3.4.8 zookeeper
$ls
bin games include lib64 sbin src
etc hadoop lib libexec share zookeeper zookeeper-3.4.8.tar.gz
#为了能使用hadoop用户对Zookeeper进行配置和启动停止等操作需要确定zookeeper目录的权限,把zookeeper的所有者和用户组都改成hadoop,这里-R表示修改这个目录所包含的所有文件,这里我删除了压缩包所以下面没有展示出来。
$ sudo chown -R hadoop:hadoop zookeeper
$ ll
drwxr-xr-x. 2 root root 27 3月 24 11:04 bin
drwxr-xr-x. 2 root root 6 8月 12 2015 etc
drwxr-xr-x. 2 root root 6 8月 12 2015 games
drwxr-xr-x. 13 hadoop hadoop 4096 6月 19 16:15 hadoop
drwxr-xr-x. 3 root root 17 3月 24 11:04 include
drwxr-xr-x. 3 root root 25 3月 24 11:04 lib
drwxr-xr-x. 2 root root 6 8月 12 2015 lib64
drwxr-xr-x. 2 root root 6 8月 12 2015 libexec
drwxr-xr-x. 2 root root 6 8月 12 2015 sbin
drwxr-xr-x. 7 root root 72 3月 24 11:04 share
drwxr-xr-x. 2 root root 6 8月 12 2015 src
drwxr-xr-x. 10 hadoop hadoop 4096 8月 2 01:46 zookeeper
#修改配置文件的名称为Zookeeper需要的配置文件名称
$ cd zookeeper
$ mv conf/zoo_sample.cfg conf/zoo.cfg
#启动
$ ./bin/zkServer.sh start
#查看是否启动成,出现QuorumPeerMain表示启动成功。
$jps
3049 Jps
2315 QuorumPeerMain
#也可以使用Client的shell脚本测试是否可以连接Zookeeper。
$ ./bin/zkCli.sh -server 127.0.0.1:2181
Connecting to 127.0.0.1:2181
2016-08-02 06:47:40,409 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.8--1, built on 02/06/2016 03:18 GMT
2016-08-02 06:47:40,412 [myid:] - INFO [main:Environment@100] - Client environment:host.name=master
2016-08-02 06:47:40,412 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_71
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.71-2.b15.el7_2.x86_64/jre
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/usr/local/zookeeper/bin/../build/classes:/usr/local/zookeeper/bin/../build/lib/*.jar:/usr/local/zookeeper/bin/../lib/slf4j-log4j12-1.6.1.jar:/usr/local/zookeeper/bin/../lib/slf4j-api-1.6.1.jar:/usr/local/zookeeper/bin/../lib/netty-3.7.0.Final.jar:/usr/local/zookeeper/bin/../lib/log4j-1.2.16.jar:/usr/local/zookeeper/bin/../lib/jline-0.9.94.jar:/usr/local/zookeeper/bin/../zookeeper-3.4.8.jar:/usr/local/zookeeper/bin/../src/java/lib/*.jar:/usr/local/zookeeper/bin/../conf:.:/usr/lib/jvm/java-1.8.0-openjdk/lib/dt.jar:/usr/lib/jvm/java-1.8.0-openjdk/lib/tools.jar
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=
2016-08-02 06:47:40,414 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2016-08-02 06:47:40,415 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2016-08-02 06:47:40,415 [myid:] - INFO [main:Environment@100] - Client environment:os.version=3.10.0-327.el7.x86_64
2016-08-02 06:47:40,415 [myid:] - INFO [main:Environment@100] - Client environment:user.name=hadoop
2016-08-02 06:47:40,415 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/hadoop
2016-08-02 06:47:40,415 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/usr/local/zookeeper
2016-08-02 06:47:40,416 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=127.0.0.1:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@531d72ca
Welcome to ZooKeeper!
2016-08-02 06:47:40,437 [myid:] - INFO [main-SendThread(127.0.0.1:2181):ClientCnxn$SendThread@1032] - Opening socket connection to server 127.0.0.1/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
2016-08-02 06:47:40,527 [myid:] - INFO [main-SendThread(127.0.0.1:2181):ClientCnxn$SendThread@876] - Socket connection established to 127.0.0.1/127.0.0.1:2181, initiating session
[zk: 127.0.0.1:2181(CONNECTING) 0] 2016-08-02 06:47:40,614 [myid:] - INFO [main-SendThread(127.0.0.1:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server 127.0.0.1/127.0.0.1:2181, sessionid = 0x1564a6ef9ba0000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
#显示到这里会停止,此时只需要在敲一次enter建就会出现下面命令行:
[zk: 127.0.0.1:2181(CONNECTED) 0]
#然后输入 -h就会出现相关Zookeeper的命令说明:
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
停止Zookeeper:
$ ./bin/zdServer.sh stop
二 Hbase安装配置:
#下载Hbase并上传到安装hadoop的同一个目录中(/usr/local/)。
$ cd /usr/local/
bin games hbase-1.2.2-bin.tar.gz lib libexec share zookeeper
etc hadoop include lib64 sbin src
#解压hbase
$ sudo tar -zxvf hbase-1.2.2-bin.tar.gz
#重命名为hbase
$ sudo mv hbase-1.2.2 hbase
$ ls
bin games hbase include lib64 sbin src
etc hadoop hbase-1.2.2-bin.tar.gz lib libexec share zookeeper
#hbase目录权限修改
$ sudo chown -R hadoop:hadoop hbase
$ ll
drwxr-xr-x. 2 root root 27 3月 24 11:04 bin
drwxr-xr-x. 2 root root 6 8月 12 2015 etc
drwxr-xr-x. 2 root root 6 8月 12 2015 games
drwxr-xr-x. 13 hadoop hadoop 4096 6月 19 16:15 hadoop
drwxr-xr-x. 7 hadoop hadoop 4096 8月 2 18:06 hbase
-rwxr-xr-x. 1 hadoop hadoop 108478494 8月 2 17:59 hbase-1.2.2-bin.tar.gz
drwxr-xr-x. 3 root root 17 3月 24 11:04 include
drwxr-xr-x. 3 root root 25 3月 24 11:04 lib
drwxr-xr-x. 2 root root 6 8月 12 2015 lib64
drwxr-xr-x. 2 root root 6 8月 12 2015 libexec
drwxr-xr-x. 2 root root 6 8月 12 2015 sbin
drwxr-xr-x. 7 root root 72 3月 24 11:04 share
drwxr-xr-x. 2 root root 6 8月 12 2015 src
drwxr-xr-x. 10 hadoop hadoop 4096 8月 2 01:46 zookeeper
#配置环境变量
#1修改hbase环境配置文件hbase-env.sh中JAVA_HOME的配置,修改为hadoop-env.sh中的一致
$ cd /usr/local/hbase/
$ vi conf/hbase-env.sh
#我这里修改为:export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
#2修改HBASE_MANAGES_ZK配置为:export HBASE_MANAGES_ZK=false ,使其不适用内置Zookeeper。
#3添加hbase环境变量到系统配置文件中
$ vi ~/.bashrc
#添加如下变量
export HBASE_HOME=/usr/local/hbase
#在PATH后面添加(:$HBASE_HOME/bin)
#使其生效
$ source ~/.bashrc
修改hbase-site.xml:
hbase.rootdir
hdfs://172.16.94.128:9000/hbase
区域服务器使用存储HBase数据库数据的目录
hbase.cluster.distributed
true
指定HBase运行的模式:false: 单机模式或者伪分布式模式 true: 全分布模式
hbase.zookeeper.quorum
172.16.94.128
ZooKeeper集群服务器的位置,这里因为是单机所以就只有一个
验证和启动:
#验证hbase是否安装成功
$ hbase version
HBase 1.2.2
Source code repository git://asf-dev/home/busbey/projects/hbase revision=3f671c1ead70d249ea4598f1bbcc5151322b3a13
Compiled by busbey on Fri Jul 1 08:28:55 CDT 2016
From source with checksum 7ac43c3d2f62f134b2a6aa1a05ad66ac
由于linux对文件打开的个数和线程个数有限制,但是hbase可能会在某些情况下会打开超过linux限制的文件或者线程数量多就会出现异常,所以要把这个限制修改为更大。
linux limit修改
#查看linux limit相关配置
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7227
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
#这里我们需要调整两个属性:open files 和 max user processes
#为了使其永久生效需要修改配置文件并重启
$ sudo vi /etc/security/limits.conf
#修改/etc/security/limits.conf 添加如下内容:
* - nofile 65535
* - nproc 65000
#说明 *表示所有用户 -表示soft/hard都要配置 nofile表示打开文件个数 nproc 表示线程个数
#修改线程配置必须也要修改这个文件/etc/security/limits.d/20-nproc.conf,不然除了root用户其他用户的max user processes还是原始的值。修改内容如下:
#把 * soft nproc 4096 改为 * soft nproc 65000
#重启
$ sudo reboot
#重新登录并查看修改成功没有
$ ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7227
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 65000
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
#这里open files 和 max user processes 都已经设置成功
启动hbase:
启动hbase之前请先保证hadoop中hdfs MapReduce YARN HistoryServer Zookeeper 等启动成功,这些的配置和启动请参考之前的笔记。这里启动出现了一些警告这里有个链接是对这个警告的一些说明,这里先不管这些警告,如果不想出现这些警告可以使用jdk7。
$ cd /usr/local/hbase
$ ./bin/start-hbase.sh
starting master, logging to /usr/local/hbase/logs/hbase-hadoop-master-master.out
OpenJDK 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
starting regionserver, logging to /usr/local/hbase/logs/hbase-hadoop-1-regionserver-master.out
#查看是否启动成功
$ jps
3536 JobHistoryServer
3233 NodeManager
2563 NameNode
3059 ResourceManager
2868 SecondaryNameNode
3636 QuorumPeerMain
3943 HRegionServer
4135 Jps
2668 DataNode
3821 HMaster
#单机模式下出现HMaster 和 HRegionServer 表示已经启动。
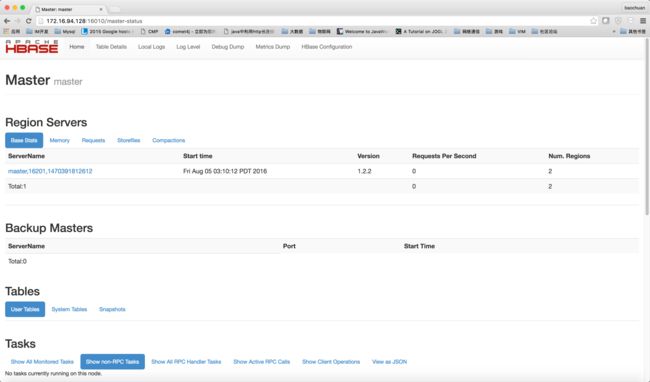
通过浏览器观察hbase的状态,在浏览器中输入http://172.16.94.128:16010/ 则会出现以下内容:
以下shell操作和demo都是来网上的一个demo
三 Hbase shell操作
这里有一些关于hbase shell命令的说明的网站,英文教程里面的说明 ,个人觉得介绍得最详细的中文版,个人觉得比较详细的英文版
#进入hbase shell控制台
$ hbase shell
2016-08-06 07:47:59,323 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.2, r3f671c1ead70d249ea4598f1bbcc5151322b3a13, Fri Jul 1 08:28:55 CDT 2016
hbase(main):001:0>
#这里我根据demo来自己操作一遍,关于命令说明请参考我列出的几个链接
hbase(main):001:0> create 'test','cf'
0 row(s) in 2.4900 seconds
=> Hbase::Table - test
hbase(main):003:0> put 'test' , 'row1', 'cf:a' , 'value1'
0 row(s) in 0.2130 seconds
hbase(main):004:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1470497082748, value=value1
1 row(s) in 0.0420 seconds
四 Hbase demo
这里我们通过java代码来完成上面shell类似的功能,在eclipse 远程连接hbase时需要在本地host文件中添加(172.16.94.128 master), 服务器名和ip的映射(master是我虚拟机的名称)。下面是我在一个翻译官方文档的博客里面复制的,这里笔记采用了最简单粗暴的方式,有更好的方式可能会在后面给hbase 添加权限控制的部分再展示:
 Paste_Image.png
Paste_Image.png
maven pom:
org.apache.hbase
hbase-client
1.2.2
org.apache.hbase
hbase-common
1.2.2
org.apache.hbase
hbase-server
1.2.2
代码:
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseClient {
// 声明静态配置,配置zookeeper
static Configuration configuration = null;
static Connection connection = null;
static {
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.quorum", "172.16.94.128");
try {
connection = ConnectionFactory.createConnection(configuration);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 创建表
*
* @param tableName
*/
public static void createTable(String tableStr, String[] familyNames) {
System.out.println("start create table ......");
try {
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf(tableStr);
if (admin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println(tableName + " is exist,detele....");
}
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
// 添加表列信息
if (familyNames != null && familyNames.length > 0) {
for (String familyName : familyNames) {
tableDescriptor.addFamily(new HColumnDescriptor(familyName));
}
}
admin.createTable(tableDescriptor);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("end create table ......");
}
/**
* 添加行列数据数据
*
* @param tableName
* @throws Exception
*/
public static void insertData(String tableName, String rowId, String familyName,String qualifier, String value) throws Exception {
System.out.println("start insert data ......");
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put(rowId.getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
put.addColumn(familyName.getBytes(), qualifier.getBytes(), value.getBytes());// 本行数据的第一列
try {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("end insert data ......");
}
/**
* 删除行
*
* @param tablename
* @param rowkey
*/
public static void deleteRow(String tablename, String rowkey) {
try {
Table table = connection.getTable(TableName.valueOf(tablename));
Delete d1 = new Delete(rowkey.getBytes());
table.delete(d1);//d1.addColumn(family, qualifier);d1.addFamily(family);
System.out.println("删除行成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 查询所有数据
*
* @param tableName
* @throws Exception
*/
public static void queryAll(String tableName) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
try {
ResultScanner rs = table.getScanner(new Scan());
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell keyValue : r.rawCells()) {
System.out.println("列:" + new String(CellUtil.cloneFamily(keyValue))+":"+new String(CellUtil.cloneQualifier(keyValue)) + "====值:" + new String(CellUtil.cloneValue(keyValue)));
}
}
rs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 根据rowId查询
*
* @param tableName
* @throws Exception
*/
public static void queryByRowId(String tableName, String rowId) throws Exception {
Table table = connection.getTable(TableName.valueOf(tableName));
try {
Get scan = new Get(rowId.getBytes());// 根据rowkey查询
Result r = table.get(scan);
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell keyValue : r.rawCells()) {
System.out.println("列:" + new String(CellUtil.cloneFamily(keyValue))+":"+new String(CellUtil.cloneQualifier(keyValue)) + "====值:" + new String(CellUtil.cloneValue(keyValue)));
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 根据列条件查询
*
* @param tableName
*/
public static void queryByCondition(String tableName, String familyName,String qualifier,String value) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
Filter filter = new SingleColumnValueFilter(Bytes.toBytes(familyName), Bytes.toBytes(qualifier), CompareOp.EQUAL, Bytes.toBytes(value)); // 当列familyName的值为value时进行查询
Scan s = new Scan();
s.setFilter(filter);
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell keyValue : r.rawCells()) {
System.out.println("列:" + new String(CellUtil.cloneFamily(keyValue))+":"+new String(CellUtil.cloneQualifier(keyValue)) + "====值:" + new String(CellUtil.cloneValue(keyValue)));
}
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 多条件查询
*
* @param tableName
*/
public static void queryByConditions(String tableName, String[] familyNames, String[] qualifiers,String[] values) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));
List filters = new ArrayList();
if (familyNames != null && familyNames.length > 0) {
int i = 0;
for (String familyName : familyNames) {
Filter filter = new SingleColumnValueFilter(Bytes.toBytes(familyName), Bytes.toBytes(qualifiers[i]), CompareOp.EQUAL, Bytes.toBytes(values[i]));
filters.add(filter);
i++;
}
}
FilterList filterList = new FilterList(filters);
Scan scan = new Scan();
scan.setFilter(filterList);
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell keyValue : r.rawCells()) {
System.out.println("列:" + new String(CellUtil.cloneFamily(keyValue))+":"+new String(CellUtil.cloneQualifier(keyValue)) + "====值:" + new String(CellUtil.cloneValue(keyValue)));
}
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 删除表
*
* @param tableName
*/
public static void dropTable(String tableStr) {
try {
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf(tableStr);
admin.disableTable(tableName);
admin.deleteTable(tableName);
admin.close();
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//创建表
createTable("t_table", new String[]{"f1","f2","f3"});
//添加数据
insertData("t_table", "row-0001", "f1","a", "fffaaa");
insertData("t_table", "row-0001", "f2", "b","fffbbb");
insertData("t_table", "row-0001", "f3", "c","fffccc");
insertData("t_table", "row-0002", "f1", "a","eeeeee");
//查询全部数据
queryAll("t_table");
//根据rowid查询数据
queryByRowId("t_table", "row-0001");
//列条件查询
queryByCondition("t_table", "f1","a", "eeeeee");
//多条件查询
queryByConditions("t_table", new String[]{"f1","f3"},new String[]{"a","c"}, new String[]{"fffaaa","fffccc"});
//删除记录
deleteRow("t_table", "row-0001");
//删除表
dropTable("t_table");
}
}
在eclipse中执行结果(直接使用 run as ->java application):
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
start create table ......
end create table ......
start insert data ......
end insert data ......
start insert data ......
end insert data ......
start insert data ......
end insert data ......
start insert data ......
end insert data ......
获得到rowkey:row-0001
列:f1:a====值:fffaaa
列:f2:b====值:fffbbb
列:f3:c====值:fffccc
获得到rowkey:row-0002
列:f1:a====值:eeeeee
获得到rowkey:row-0001
列:f1:a====值:fffaaa
列:f2:b====值:fffbbb
列:f3:c====值:fffccc
获得到rowkey:row-0002
列:f1:a====值:eeeeee
获得到rowkey:row-0001
列:f1:a====值:fffaaa
列:f2:b====值:fffbbb
列:f3:c====值:fffccc
删除行成功!
结束语:因为是初学很多问题没有弄太懂,所以笔记也笔记混乱,所以给你带来困惑请包涵并指出问题,帮助我更快的提高,谢谢。