目录
- 前言
- 安装
- 环境
- Debian / Ubuntu / Deepin 下安装
- Windows 下安装
- 基本使用
- 初始化项目
- 创建爬虫
- 运行爬虫
- 爬取结果
- 进阶使用
- 分布式爬虫
- anti-anti-spider
- URL Filter
- 总结
- 相关资料
前言
在本篇中,我假定您已经熟悉并安装了 Python3。 如若不然,请参考 Python 入门指南 。
关于 Scrapy
Scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 网络抓取 所设计的, 也可以应用在获取 API 所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
架构概览
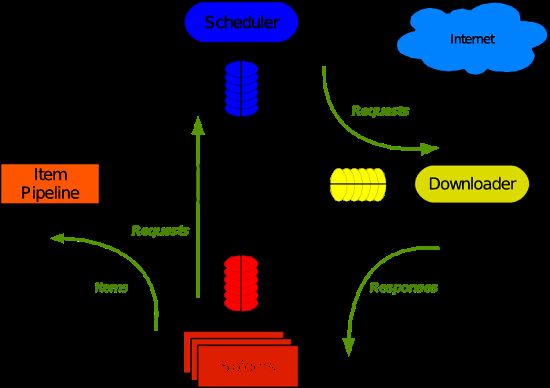
安装
环境
- Redis 3.2.5
- Python 3.5.2
-
Scrapy1.3.3 -
scrapy-redis0.6.8 -
redis-py2.10.5 -
PyMySQL0.7.10 -
SQLAlchemy1.1.6
-
Debian / Ubuntu / Deepin 下安装
安装前你可能需要把 Python3 设置为默认的 Python 解释器,或者使用 virtualenv 搭建一个 Python 的虚拟环境,篇幅有限,此处不再赘述。
安装 Redis
sudo apt-get install redis-server
安装 Scrapy
sudo apt-get install build-essential libssl-dev libffi-dev python-dev
sudo apt install python3-pip
sudo pip install scrapy scrapy-reids
安装 scrapy-redis
sudo pip install scrapy-reids
Windows 下安装
由于目前 Python 实现的一部分第三方模块在 Windows 下并没有可用的安装包,个人并不推荐以 Windows 作为开发环境。
如果你非要这么做,你可能会遇到以下异常:
- ImportError: DLL load failed: %1 不是有效的 Win32 应用程序
- 这是由于你安装了 64 位的 Python,但却意外安装了 32 位的模块
- Failed building wheel for cryptography
- 你需要升级你的 pip 并重新安装 cryptography 模块
- ERROR: 'xslt-config' is not recognized as an internal or external command,
operable program or batch file.- 你需要从 lxml 的官网下载该模块编译好的 exe 安装包,并用 easy_install 手动进行安装
- ImportError: Nomodule named win32api
- 这是个 Twisted bug ,你需要安装 pywin32 。
如果你还没有放弃,以下内容可能会帮到你:
- Windows上Python3.5安装Scrapy(lxml)
- Python爬虫进阶三之Scrapy框架安装配置
- Microsoft Visual C++ Compiler for Python 2.7
- easy_install lxml on Python 2.7 on Windows
基本使用
初始化项目
- 命令行下初始化 Scrapy 项目
scrapy startproject spider_ebay
- 执行后将会生成以下目录结构
└── spider_ebay
├── spider_ebay
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
创建爬虫
- 创建文件
spider_ebay/spider_ebay/spiders/example.py - 代码如下:
from scrapy.spiders import Spider
class ExampleSpider(Spider):
name = 'example'
start_urls = ['http://www.ebay.com/sch/allcategories/all-categories']
def parse(self, response):
datas = response.xpath("//div[@class='gcma']/ul/li/a[@class='ch']")
for data in datas:
try:
yield {
'name': data.xpath("text()").extract_first(),
'link': data.xpath("@href").extract_first()
}
# or
# yield self.make_requests_from_url(data.xpath("@href").extract_first())
except:
pass
该例爬取了 eBay 商品分类页面下的子分类页的 url 信息
ExampleSpider继承自Spider,定义了name、start_urls属性与parse方法。
程序通过name来调用爬虫,爬虫运行时会先从strart_urls中提取 url 构造request,获取到对应的response时,
利用parse方法解析response,最后将目标数据或新的request通过yield语句以生成器的形式返回。
运行爬虫
cd spider_ebay
scrapy crawl example -o items.json
爬取结果
spider_ebay/items.json
[
{"name": "Antiquities", "link": "http://www.ebay.com/sch/Antiquities/37903/i.html"},
{"name": "Architectural & Garden", "link": "http://www.ebay.com/sch/Architectural-Garden/4707/i.html"},
{"name": "Asian Antiques", "link": "http://www.ebay.com/sch/Asian-Antiques/20082/i.html"},
{"name": "Decorative Arts", "link": "http://www.ebay.com/sch/Decorative-Arts/20086/i.html"},
{"name": "Ethnographic", "link": "http://www.ebay.com/sch/Ethnographic/2207/i.html"},
{"name": "Home & Hearth", "link": "http://www.ebay.com/sch/Home-Hearth/163008/i.html"},
{"name": "Incunabula", "link": "http://www.ebay.com/sch/Incunabula/22422/i.html"},
{"name": "Linens & Textiles (Pre-1930)", "link": "http://www.ebay.com/sch/Linens-Textiles-Pre-1930/181677/i.html"},
{"name": "Manuscripts", "link": "http://www.ebay.com/sch/Manuscripts/23048/i.html"},
{"name": "Maps, Atlases & Globes", "link": "http://www.ebay.com/sch/Maps-Atlases-Globes/37958/i.html"},
{"name": "Maritime", "link": "http://www.ebay.com/sch/Maritime/37965/i.html"},
{"name": "Mercantile, Trades & Factories", "link": "http://www.ebay.com/sch/Mercantile-Trades-Factories/163091/i.html"},
{"name": "Musical Instruments (Pre-1930)", "link": "http://www.ebay.com/sch/Musical-Instruments-Pre-1930/181726/i.html"},
{"name": "Other Antiques", "link": "http://www.ebay.com/sch/Other-Antiques/12/i.html"},
{"name": "Periods & Styles", "link": "http://www.ebay.com/sch/Periods-Styles/100927/i.html"},
{"name": "Primitives", "link": "http://www.ebay.com/sch/Primitives/1217/i.html"},
{"name": "Reproduction Antiques", "link": "http://www.ebay.com/sch/Reproduction-Antiques/22608/i.html"},
{"name": "Restoration & Care", "link": "http://www.ebay.com/sch/Restoration-Care/163101/i.html"},
{"name": "Rugs & Carpets", "link": "http://www.ebay.com/sch/Rugs-Carpets/37978/i.html"},
{"name": "Science & Medicine (Pre-1930)", "link": "http://www.ebay.com/sch/Science-Medicine-Pre-1930/20094/i.html"},
{"name": "Sewing (Pre-1930)", "link": "http://www.ebay.com/sch/Sewing-Pre-1930/156323/i.html"},
{"name": "Silver", "link": "http://www.ebay.com/sch/Silver/20096/i.html"},
{"name": "Art from Dealers & Resellers", "link": "http://www.ebay.com/sch/Art-from-Dealers-Resellers/158658/i.html"},
{"name": "Direct from the Artist", "link": "http://www.ebay.com/sch/Direct-from-the-Artist/60435/i.html"},
{"name": "Baby Gear", "link": "http://www.ebay.com/sch/Baby-Gear/100223/i.html"},
{"name": "Baby Safety & Health", "link": "http://www.ebay.com/sch/Baby-Safety-Health/20433/i.html"},
{"name": "Bathing & Grooming", "link": "http://www.ebay.com/sch/Bathing-Grooming/20394/i.html"},
{"name": "Car Safety Seats", "link": "http://www.ebay.com/sch/Car-Safety-Seats/66692/i.html"},
{"name": "Carriers, Slings & Backpacks", "link": "http://www.ebay.com/sch/Carriers-Slings-Backpacks/100982/i.html"},
{"name": "Diapering", "link": "http://www.ebay.com/sch/Diapering/45455/i.html"},
{"name": "Feeding", "link": "http://www.ebay.com/sch/Feeding/20400/i.html"},
{"name": "Keepsakes & Baby Announcements", "link": "http://www.ebay.com/sch/Keepsakes-Baby-Announcements/117388/i.html"},
......
进阶使用
分布式爬虫
架构

-
MasterSpider对start_urls中的 urls 构造request,获取response -
MasterSpider将response解析,获取目标页面的 url, 利用 redis 对 url 去重并生成待爬request队列 -
SlaveSpider读取 redis 中的待爬队列,构造request -
SlaveSpider发起请求,获取目标页面的response -
Slavespider解析response,获取目标数据,写入生产数据库
关于 Redis
Redis 是目前公认的速度最快的基于内存的键值对数据库
Redis 作为临时数据的缓存区,可以充分利用内存的高速读写能力大大提高爬虫爬取效率。
关于 scrapy-redis
scrapy-redis 是为了更方便地实现 Scrapy 分布式爬取,而提供的一些以 Redis 为基础的组件。
scrapy 使用 python 自带的
collection.deque来存放待爬取的request。scrapy-redis 提供了一个解决方案,把 deque 换成 redis 数据库,能让多个 spider 读取同一个 redis 数据库里,解决了分布式的主要问题。
配置
使用 scrapy-redis 组件前需要对 Scrapy 配置做一些调整
spider_ebay/settings.py
# 过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度状态持久化
SCHEDULER_PERSIST = True
# 请求调度使用优先队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# redis 使用的端口和地址
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
增加并发
并发是指同时处理数量。其有全局限制和局部(每个网站)的限制。
Scrapy 默认的全局并发限制对同时爬取大量网站的情况并不适用。 增加多少取决于爬虫能占用多少 CPU。 一般开始可以设置为 100 。
不过最好的方式是做一些测试,获得 Scrapy 进程占取 CPU 与并发数的关系。 为了优化性能,应该选择一个能使CPU占用率在80%-90%的并发数。
增加全局并发数的一些配置:
# 默认 Item 并发数:100
CONCURRENT_ITEMS = 100
# 默认 Request 并发数:16
CONCURRENT_REQUESTS = 16
# 默认每个域名的并发数:8
CONCURRENT_REQUESTS_PER_DOMAIN = 8
# 每个IP的最大并发数:0表示忽略
CONCURRENT_REQUESTS_PER_IP = 0
缓存
scrapy默认已经自带了缓存,配置如下
# 打开缓存
HTTPCACHE_ENABLED = True
# 设置缓存过期时间(单位:秒)
#HTTPCACHE_EXPIRATION_SECS = 0
# 缓存路径(默认为:.scrapy/httpcache)
HTTPCACHE_DIR = 'httpcache'
# 忽略的状态码
HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存模式(文件缓存)
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Redis 远程连接
安装完成后,redis默认是不能被远程连接的,此时要修改配置文件/etc/redis.conf
# bind 127.0.0.1
修改后,重启redis服务器
systemctl restart redis
如果要增加redis的访问密码,修改配置文件/etc/redis.conf
requirepass passwrd
增加了密码后,启动客户端的命令变为:redis-cli -a passwrd
测试是否能远程登陆
使用 windows 的命令窗口进入 redis 安装目录,用命令进行远程连接 redis:
redis-cli -h 192.168.1.112 -p 6379

在本机上测试是否能读取 master 的 redis

在远程机器上读取是否有该数据
可以确信 redis 配置完成
MasterSpider
# coding: utf-8
from scrapy import Item, Field
from scrapy.spiders import Rule
from scrapy_redis.spiders import RedisCrawlSpider
from scrapy.linkextractors import LinkExtractor
from redis import Redis
from time import time
from urllib.parse import urlparse, parse_qs, urlencode
class MasterSpider(RedisCrawlSpider):
name = 'ebay_master'
redis_key = 'ebay:start_urls'
ebay_main_lx = LinkExtractor(allow=(r'http://www.ebay.com/sch/allcategories/all-categories', ))
ebay_category2_lx = LinkExtractor(allow=(r'http://www.ebay.com/sch/[^\s]*/\d+/i.html',
r'http://www.ebay.com/sch/[^\s]*/\d+/i.html?_ipg=\d+&_pgn=\d+',
r'http://www.ebay.com/sch/[^\s]*/\d+/i.html?_pgn=\d+&_ipg=\d+',))
rules = (
Rule(ebay_category2_lx, callback='parse_category2', follow=False),
Rule(ebay_main_lx, callback='parse_main', follow=False),
)
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
# self.allowed_domains = filter(None, domain.split(','))
super(MasterSpider, self).__init__(*args, **kwargs)
def parse_main(self, response):
pass
data = response.xpath("//div[@class='gcma']/ul/li/a[@class='ch']")
for d in data:
try:
item = LinkItem()
item['name'] = d.xpath("text()").extract_first()
item['link'] = d.xpath("@href").extract_first()
yield self.make_requests_from_url(item['link'] + r"?_fsrp=1&_pppn=r1&scp=ce2")
except:
pass
def parse_category2(self, response):
data = response.xpath("//ul[@id='ListViewInner']/li/h3[@class='lvtitle']/a[@class='vip']")
redis = Redis()
for d in data:
# item = LinkItem()
try:
self._filter_url(redis, d.xpath("@href").extract_first())
except:
pass
try:
next_page = response.xpath("//a[@class='gspr next']/@href").extract_first()
except:
pass
else:
# yield self.make_requests_from_url(next_page)
new_url = self._build_url(response.url)
redis.lpush("test:new_url", new_url)
# yield self.make_requests_from_url(new_url)
# yield Request(url, headers=self.headers, callback=self.parse2)
def _filter_url(self, redis, url, key="ebay_slave:start_urls"):
is_new_url = bool(redis.pfadd(key + "_filter", url))
if is_new_url:
redis.lpush(key, url)
def _build_url(self, url):
parse = urlparse(url)
query = parse_qs(parse.query)
base = parse.scheme + '://' + parse.netloc + parse.path
if '_ipg' not in query.keys() or '_pgn' not in query.keys() or '_skc' in query.keys():
new_url = base + "?" + urlencode({"_ipg": "200", "_pgn": "1"})
else:
new_url = base + "?" + urlencode({"_ipg": query['_ipg'][0], "_pgn": int(query['_pgn'][0]) + 1})
return new_url
class LinkItem(Item):
name = Field()
link = Field()
MasterSpider 继承来自 scrapy-redis 组件下的 RedisCrawlSpider,相比 ExampleSpider 有了以下变化:
-
redis_key- 该爬虫的
start_urls的存放容器由原先的 Python list 改至 redis list,所以此处需要redis_key存放 redis list 的 key
- 该爬虫的
-
rules-
rules是含有多个Rule对象的 tuple -
Rule对象实例化常用的三个参数:link_extractor/callback/follow-
link_extractor是一个LinkExtractor对象。 其定义了如何从爬取到的页面提取链接 -
callback是一个 callable 或 string (该spider中同名的函数将会被调用)。 从 link_extractor中每获取到链接时将会调用该函数。该回调函数接受一个response作为其第一个参数, 并返回一个包含 Item 以及(或) Request 对象(或者这两者的子类)的列表(list)。 -
follow是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果 callback 为None, follow 默认设置为 True ,否则默认为 False 。 -
process_links处理所有的链接的回调,用于处理从response提取的links,通常用于过滤(参数为link列表) -
process_request链接请求预处理(添加header或cookie等)
-
-
-
ebay_main_lx/ebay_category2_lx-
LinkExtractor对象-
allow(a regular expression (or list of)) – 必须要匹配这个正则表达式(或正则表达式列表)的URL才会被提取。如果没有给出(或为空), 它会匹配所有的链接。 -
deny排除正则表达式匹配的链接(优先级高于allow) -
allow_domains允许的域名(可以是str或list) -
deny_domains排除的域名(可以是str或list) -
restrict_xpaths: 取满足XPath选择条件的链接(可以是str或list) -
restrict_css提取满足css选择条件的链接(可以是str或list) -
tags提取指定标签下的链接,默认从a和area中提取(可以是str或list) -
attrs提取满足拥有属性的链接,默认为href(类型为list) -
unique链接是否去重(类型为boolean) -
process_value值处理函数(优先级大于allow)
-
-
-
parse_main/parse_category2- 用于解析符合对应 rule 的 url 的 response 的方法
-
_filter_url/_build_url- 一些有关 url 的工具方法
-
LinkItem- 继承自 Item 对象
- Item 对象是种简单的容器,用于保存爬取到得数据。 其提供了类似于 dict 的 API 以及用于声明可用字段的简单语法。
SlaveSpider
# coding: utf-8
from scrapy import Item, Field
from scrapy_redis.spiders import RedisSpider
class SlaveSpider(RedisSpider):
name = "ebay_slave"
redis_key = "ebay_slave:start_urls"
def parse(self, response):
item = ProductItem()
item["price"] = response.xpath("//span[contains(@id,'prcIsum')]/text()").extract_first()
item["item_id"] = response.xpath("//div[@id='descItemNumber']/text()").extract_first()
item["seller_name"] = response.xpath("//span[@class='mbg-nw']/text()").extract_first()
item["sold"] = response.xpath("//span[@class='vi-qtyS vi-bboxrev-dsplblk vi-qty-vert-algn vi-qty-pur-lnk']/a/text()").extract_first()
item["cat_1"] = response.xpath("//li[@class='bc-w'][1]/a/span/text()").extract_first()
item["cat_2"] = response.xpath("//li[@class='bc-w'][2]/a/span/text()").extract_first()
item["cat_3"] = response.xpath("//li[@class='bc-w'][3]/a/span/text()").extract_first()
item["cat_4"] = response.xpath("//li[@class='bc-w'][4]/a/span/text()").extract_first()
yield item
class ProductItem(Item):
name = Field()
price = Field()
sold = Field()
seller_name = Field()
pl_id = Field()
cat_id = Field()
cat_1 = Field()
cat_2 = Field()
cat_3 = Field()
cat_4 = Field()
item_id = Field()
SlaveSpider 继承自 RedisSpider,属性与方法相比 MasterSpider 简单了不少,少了 rules 与其他,但大致功能都比较类似
SlaveSpider 从 ebay_slave:start_urls 下读取构建好的目标页面的 request,对 response 解析出目标数据,以 ProductItem 的形式输出数据
数据存储
scrpay-redis 默认情况下会将爬取到的目标数据写入 redis
利用 Python 丰富的数据库接口支持可以通过 Pipeline 把 Item 中的数据存放在任意一种常见的数据库中
关于 SQLAlchemy
SQLAlchemy 是在Python中最有名的 ORM 框架。通过 SQLAlchemy 你可以用操作对象的方式来操作 mysql,sqlite,sqlserver,oracle 等大部分常见数据库
安装
pip install pymysql
pip install sqlalchemy
ebay_spider/settings.py
ITEM_PIPELINES = {
'ebay_spider.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
我们在 settings.py 模块中配置 ebay_spider.pipelines.ExamplePipeline 把 ExamplePipeline 配置到爬虫上,后面的数字 300 表示 pipeline 的执行顺序,数值小的先执行
scrapy_redis.pipelines.RedisPipeline 是 scrapy-redis 使用的默认的 pipeline,如果不需要 redis 保存目标数据,可以不配置
ebay_spider/pipelines.py
from scrapy.exceptions import DropItem
from sqlalchemy import create_engine
from .model.config import DBSession
from .model.transfer import Transfer
class ExamplePipeline(object):
def open_spider(self, spider):
self.session = DBSession()
self.session.execute('SET NAMES utf8;')
self.session.execute('SET CHARACTER SET utf8;')
self.session.execute('SET character_set_connection=utf8;')
def process_item(self, item, spider):
a = Transfer(
transfer_order_id = item['session_online_id'],
transfer_content = item['session_name'].encode('utf8')
)
self.session.merge(a)
self.session.commit()
return item
def close_spider(self, spider):
self.session.close()
此处定义把数据保存到 Mysql 的 ExamplePipeline,
其中,pipeline 的 open_spider 和 spider_closed 两个方法,在爬虫启动和关闭的时候调用
此 pipeline 在爬虫启动时,建立起与 Mysql 的连接。当 spider 输出 Item 时将 Item 中的数据存入 Mysql 中。在爬虫关闭的同时,关闭与数据库的连接
ebay_spider/models/config.py
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
engine = create_engine("mysql+pymysql://root:12345678@localhost/beston")
DBSession = sessionmaker(bind=engine)
这是 ExamplePipeline 中使用到的数据库连接配置。要注意的是,此处使用的是 pymysql 作为数据库驱动,而不是 MySQLdb。
ebay_spider/models/transfer.py
# coding:utf8
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class Transfer(Base):
# 表名
__tablename__ = 'bt_transfer'
__table_args__ = {
'mysql_engine': 'MyISAM',
'mysql_charset': 'utf8'
}
# 表结构
transfer_id = Column(Integer, primary_key=True)
transfer_order_id = Column(Integer)
transfer_content = Column(String(255))
以上是 Mysql ORM 模型,定义了 bt_transfer 表。也可使用 SQLAlchemy 的命令来生成此表。
anti-anti-spider
大多网站对爬虫的活动都进行了限制,anti-anti-spider 即 反反爬虫。是为了突破这些限制的一些解决方案的称呼。
以下介绍几种常用的方案
伪造 User-Agent
通过伪造 request header 中的 User-Agent 可以模仿浏览器操作,从而绕过一些网站的反爬虫机制
- 首先建立一个 User-Agent 池
user_agent.py
agents = [
"Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0 )",
"Mozilla/4.0 (compatible; MSIE 5.5; Windows 98; Win 9x 4.90)",
"Mozilla/5.0 (Windows; U; Windows XP) Gecko MultiZilla/1.6.1.0a",
"Mozilla/2.02E (Win95; U)",
"Mozilla/3.01Gold (Win95; I)",
"Mozilla/4.8 [en] (Windows NT 5.1; U)",
"Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.4) Gecko Netscape/7.1 (ax)",
"HTC_Dream Mozilla/5.0 (Linux; U; Android 1.5; en-ca; Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.2; U; de-DE) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/234.40.1 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; sdk Build/CUPCAKE) AppleWebkit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
"Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Mozilla/5.0 (Linux; U; Android 1.5; en-us; htc_bahamas Build/CRB17) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1",
"Mozilla/5.0 (Linux; U; Android 2.1-update1; de-de; HTC Desire 1.19.161.5 Build/ERE27) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17",
......
]
- 重写
UserAgentMiddleware
import random
from .user_agent import agents
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
class UserAgentmiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
agent = random.choice(agents)
request.headers["User-Agent"] = agent
UserAgentmiddleware 定义了函数 process_request(request, spider),Scrapy 每一个 request 通过中间件都会随机的从 user_agent.py 中获取一个伪造的 User-Agent 放入 request 的 header,来达到欺骗的目的。
IP proxy
反爬虫一个最常用的方法的就是限制 ip。为了避免最坏的情况,可以利用代理服务器来爬取数据,scrapy 设置代理服务器只需要在请求前设置 Request 对象的 meta 属性,添加 proxy 值即可,
可以通过中间件来实现:
class ProxyMiddleware(object):
def process_request(self, request, spider):
proxy = 'https://178.33.6.236:3128' # 代理服务器
request.meta['proxy'] = proxy
另外,也可以使用大量的 IP Proxy 建立起代理 IP 池,请求时随机调用来避免更严苛的 IP 限制机制,方法类似 User-Agent 池
URL Filter
正常业务逻辑下,爬虫不会对重复爬取同一个页面两次。所以爬虫默认都会对重复请求进行过滤,但当爬虫体量达到千万级时,默认的过滤器占用的内存将会远远超乎你的想象。
为了解决这个问题,可以通过一些算法来牺牲一点点过滤的准确性来换取更小的空间复杂度
Bloom Filter
Bloom Filter可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Hyperloglog
HyperLogLog是一个基数估计算法。其空间效率非常高,1.5K内存可以在误差不超过2%的前提下,用于超过10亿的数据集合基数估计。
这两种算法都是合适的选择,以 Hyperloglog 为例
由于 redis 已经提供了支持 hyperloglog 的数据结构,所以只需对此数据结构进行操作即可
MasterSpider 下的 _filter_url 实现了过滤 URL 的功能
def _filter_url(self, redis, url, key="ebay_slave:start_urls"):
is_new_url = bool(redis.pfadd(key + "_filter", url))
if is_new_url:
redis.lpush(key, url)
当 redis.pfadd() 执行时,一个 url 尝试插入 hyperloglog 结构中,如果 url 存在返回 0,反之返回 1。由此来判断是否要将该 url 存放至待爬队列
总结
Scrapy 是一个优秀的爬虫框架。性能上,它快速强大,多线程并发与事件驱动的设计能将爬取效率提高几个数量级;功能上,它又极易扩展,支持插件,无需改动核心代码。但如果要运用在在大型爬虫项目中,不支持分布式设计是它的一个大硬伤。幸运的是,scrapy-redis 组件解决了这个问题,并给 Scrapy 带来了更多的可能性。
相关资料
Scrapy 1.0 文档
Scrapy-Redis’s documentation
使用SQLAlchemy
布隆过滤器
HyperLogLog
Python 入门指南
scrapy_redis去重优化
基于Scrapy-Redis的分布式以及cookies池