Hive
一、Hive概述
1). MapReducer的不足
HDFS上的文件并没有schema的概念(比如关系型数据库中的表、字段的概念)
2). Hive特点
- 由Facebook开源的,用于解决海量结构化日志的数据统计问题
- 构建在Hadoop之上的数据仓库,为超大的数据集设计的计算/扩展能力
- Hive提供的SQL查询语言:HQL;语法与TSQL一样;统一的元数据管理
- Hive数据是存放在HDFS
- 元数据信息(记录数据的数据)是存放在MySQL中
- SQL on Hadoop: Hive、Spark SQL、impala....
- 底层支持多种不同的执行引擎:MR/Tez/Spark

Hive在Hadoop生态系统中的位置.png
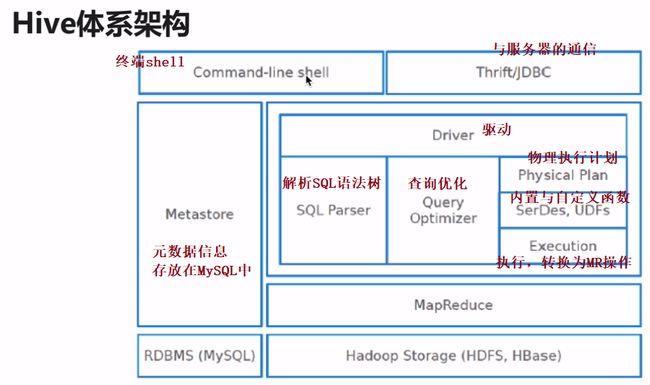
3). Hive体系架构
Hibe体系架构.png
-
client:
- shell:终端
- thrift/jdbc(server/jdbc):连接协议
- WebUI(HUE/Zeppelin):web界面写sql执行
-
metastore:元数据信息存放在MySQL数据库中
- database:name、location、owner....
- table:name、location、owner、column name/type ....
二、Hive安装部署
1.Hive部署架构

Hive部署架构.png
2.Hive与RDBMS的区别
- Hive适合离线处理,不建议使用insert和update功能
- Hive适合大数据,PB级别的数据都是小意思
3. Hive部署
- 下载
参考之前hadoop下载
- 解压到~/app
tar -zvxf hive-1.1.0-cdh5.15.1.tar.gz -C ~/app/
- 添加HIVE_HOME到系统环境变量
方便直接启动hive
> vim ~/.bash_profile
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.15.1
export PATH=$PATH:$HIVE_HOME/bin
> source ~/.bash_profile
-
$HIVE_HOME下的常见目录-
bin: 脚本文件 -
conf: 配置 -
lib: Hive依赖jar包
-
- 修改配置
$HIVE_HOME/conf/hive-env.sh
> cp hive-env.sh.template hive-env.sh
> vim hive-env.sh
HADOOP_HOME=/home/hadoop/app/hadoop-2.6.0-cdh5.15.1 # 系统变量$HADOOP_HOME的值;这一步非必需的!建议配置上
- 修改配置
$HIVE_HOME/conf/hive-site.xml
vim hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://hadoop000:3306/hadoop_hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
hadoop
javax.jdo.option.ConnectionPassword
abc123
- 拷贝MySQL驱动包到
$HIVE_HOME/lib
需要自己下载(Java开发者可以到本地Maven仓库中找)
- 前提是要准备安装一个MySQL数据库(推荐MySQL开源分支 --> MariaDB )
- https://www.jianshu.com/p/9ca6a7701586
三、hive客户端测试
1).hive客户端启动
- 先初始化数据库(首次启动hive之前执行)
否则可能会出现sql语句执行错误;
sh $HIVE_HOME/bin/schematool -dbType mysql -initSchema
如果提示Duplicate,将数据库中的hadoop_hive删除再试。
- 启动Hive
[hadoop@hadoop000 ~]$ hive
2). 测试案例
- 前期准备
jps
vim ~/data/helloworld.txt
1 zhangsan
2 wangwu
3 lisi
- hive操作
hive
create database test_db;
use test_db;
show tables;
create table helloworld(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
show tables;
select * from helloworld;
load data local inpath '/home/hadoop/data/helloworld.txt' overwrite into table helloworld;
select * from helloworld;
select count(1) from helloworld;
- mysql查看信息
show databases;
use hadoop_hive;
select * from DBS; # Hive创建的数据库信息存放位置
- hdfs 查看信息
hadoop fs -ls /user/hive/warehouse/
四、Hive语法
推荐参考官网https://cwiki.apache.org/confluence/display/Hive#space-menu-link-content
1). DDL数据库操作
-
DDL:Hive Data Definition Language
- create、delete、alter...
-
Hive数据抽象/结构
- database: HDFS一个目录
- table: HDFS一个目录
- data: 具体文件
- partition: 分区表 HDFS一个目录
- data: 具体文件
- bucket: 分桶,HDFS一个文件
- table: HDFS一个目录
- database: HDFS一个目录
官方数据库创建语法
(A|B|...)表示多选一必填;[]表示可选参数
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] # 数据库注释
[LOCATION hdfs_path] # 指定存放在hdfs的路径;默认`/user/hive/warehouse`
[WITH DBPROPERTIES (property_name=property_value, ...)]; # 自定义属性
- 创建数据库案例
# 创建数据库
CREATE DATABASE IF NOT EXISTS hive;
# 默认创建的数据库路径在hdfs上的 /user/hive/warehouse上,可以自定义;hive会自动创建该路径
CREATE DATABASE IF NOT EXISTS hive2 LOCATION '/test/location';
# 自定义数据库属性
CREATE DATABASE IF NOT EXISTS hive3 WITH DBPROPERTIES('creator'='lc');
/user/hive/warehouse是Hive默认的存储在HDFS上的路径
- 查看数据库
# 显示所有数据库
show databases;
# 切换数据库
use hive3;
# 查看数据库信息
desc database hive3;
# 查看数据库详细信息
desc database extended hive3;
# 正则查询数据库
show databases like 'hive*';
- 设置查看当前使用的数据库(让命令行自动显示,默认使用default数据库)
set hive.cli.print.current.db=true;
# 查看正在使用的数据库
SELECT current_database();
- 删除数据库(只能删除非空的数据库)
drop database hive3;
# 级联操作删除(忘记吧)
drop database hive3 cascade;
2). DDL表操作
- 表定义语言(详细请参照官网文档)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
- 创建模拟数据
/home/hadoop/data/emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
8888 HIVE PROGRAM 7839 1988-1-23 10300.00
- 创建表
# 创建表
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; # 指定分隔符
# 查看信息
desc emp;
# 查看详细信息
desc extended emp;
# 查看详细信息高级版
desc formatted emp;
# 加载数据到表中
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp;
# 查看数据
select * from emp;
# 改表名
alter table emp rename to emp2;
alter table emp2 rename to emp;
3). DML加载和导出数据
- 加载数据语法
-
LOCAL:本地系统,如果没有local那么就是指的HDFS的路径 -
OVERWRITE:是否数据覆盖,如果没有那么就是数据追加
-
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- 案例
# 加local表示从本地,默认为本机的hdfs
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp;
# 从hdfs完整路径加载【hdfs源数据会被移动到指定的其他文件夹】
LOAD DATA INPATH 'hdfs://hadoop000:8020/data/emp.txt' INTO TABLE emp;
# 写数据到本地
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/hive/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select empno,ename,sal,deptno from emp;
# 创建临时表
create table emp1 as select * from emp;
插入数据,更新数据的功能建议不要使用;因为会非常影性能
4). 查询语法
与SQL标准语法一致
select ename,empno from emp limit 3
select ename from emp where empno > 900;
select * from emp where between 800 and 1500;
5). 聚合函数
聚合: max/min/sum/count/avg
select count(1) from emp where deptno >= 10;
select max(sal),min(sal),sum(sal),avg(sal) from emp;
6). 分组函数
分组函数:
group by; 查询条件:where; 分组后过滤:having; 限制条数:limit
# 求每个部门的平均工资,出现在select中的字段,如果没有出现在聚合函数里,那么一定要实现在group by里
select depno, avg(sal) from emp group by depno;
# 求每个部门、工作岗位的平均工资
select depno, job, avg(sal) from emp group by depno,job;
# 求每个部门的平均工资大于2000的部门;对于分组函数过滤要使用having
select depno,avg(sal) sal_avg from emp group by depno having sal_avg > 2000;
7). Join操作
- 准备数据
[hadoop@hadoop000 data]$ pwd
/home/hadoop/data
[hadoop@hadoop000 data]$ vim dept.txt
10 ACCOUNTING NEW UORK
20 RESEARCH DALLAS
30 ASLES CHICAGO
40 OPERATIONS BOSTON
- 准备表
# 创建dept表
CREATE TABLE dept(
deptno int,
dname string,
loc string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
# 加载数据
LOAD DATA LOCAL INPATH '/home/hadoop/data/dept.txt' OVERWRITE INTO TABLE dept;
- 执行join:多表 emp+dept
select e.empno,e.ename,e.sal,e.deptno,d.dname from emp e join dept d on e.deptno=d.deptno;
- 执行计划:解释命令
# 简略信息
explain select e.empno,e.ename,e.sal,e.deptno,d.dname from emp e join dept d on e.deptno=d.deptno;
# 详细信息,包含抽象语法树
explain EXTENDED select e.empno,e.ename,e.sal,e.deptno,d.dname from emp e join dept d on e.deptno=d.deptno;
五、项目实战
1). Hive外部表与内部表
生产上建议使用 外部表
- 查看表的类型
# Hive
# 查看表结构
desc formatted emp;
...
Table Type MANAGED_TABLE # 内部表
...
Table Type EXTERNAL_TABLE # 外部表
...
# MySQL也可以查看信息
use hadoop_hive;
select * form TBLS;
- 外部表演示
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp;
select * from emp;
drop table emp_external;
删除内部表,HDFS上的数据被删除 并且 Meta元数据也被删除
MANAGED_TABLE:内部表
- 外部表演示
CREATE EXTERNAL TABLE emp_external(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location '/external/emp/'; # 指定hdfs的目录
LOAD DATA LOCAL INPATH '/home/hadoop/data/emp.txt' OVERWRITE INTO TABLE emp_external;
select * from emp;
drop table emp_external;
# 再执行一下创建表的操作,不用导入数据;发现数据能查到
删除EXTERNAL_TABLE,删除HDFS上的数据不被删除 但是 Meta被删除
2). Hive的分区表
- 创建分区表,自定义按照天分区
create external table track_info(
ip string,
url string,
sessionId string,
time string,
country string,
province string,
city string,
page string
) partitioned by (day string) # 假如按照天进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location '/project/trackinfo/';
desc formatted track_info;
...
FieldSchema(name:day ...) # 按照天分区
...
3). 项目的Hive实现
- 导入数据,ETL操作,将数据写入表中
# 准备原始数据
hadoop fs -mkdir -p /hive_test/resource
hadoop fs -put trackinfo_origin.log /hive_test/resource
# ETL操作
vim etl.sh
hadoop jar ~/lib/hadoop-learning-2.0-RELEASE.jar com.hahadasheng.bigdata.hadooplearning.loganalyze.v2.ETLApp /hive_test/trackinfo_origin.log /hive_test/etl
sh etl.sh
# Hive~~~~~~~~~~~~~~~~~~~~~~~~~~ 创建外部分区表
create external table track_info(
ip string,
url string,
sessionId string,
time string,
country string,
province string,
city string,
page string
) partitioned by (day string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/hive_test/trackinfo/';
# 将数据导入到Hive外部表: 注意分区字段
LOAD DATA INPATH 'hdfs://hadoop000:8020/hive_test/etl' OVERWRITE INTO TABLE track_info partition(day='2013-07-21');
# 查询测试 --> 跑MaoReduce作业
select count(*) from track_info where day='2013-07-21';
select province,count(*) as cnt from track_info where day='2013-07-21' group by province;
- 省份统计表目标表【按照天进行分区】
# Hive ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
create external table track_info_province_stat(
province string,
cnt bigint
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/hive_test/trackinfo/';
# 从track_info表中导出数据
insert overwrite table track_info_province_stat partition(day='2013-07-21')
select province,count(*) as cnt from track_info where day='2013-07-21' group by province;
# 查询
select * from track_info_province_stat where day='2013-07-21' limit 5;
统计的数据已经在Hive表track_info_province_stat而且这个表是一个分区表,后续统计报表的数据可以直接从这个表中查询也可以将hive表的数据导出到RDBMS(推荐使用
sqoop工具)
- Hive离线处理流程总结
- ETL操作:(此操作建议使用MapReduce操作;或者Spark操作;别用Hive)
- 把ETL输出的数据加载到track_info分区表里
- 各个维度统计结果的数据输出到各自维度的表里(track_info_province_stat)
- 将数据导出(optional)
如果一个框架不能落地到SQL层面,这个框架就不是一个非常适合的框架
- 补充
[hadoop@hadoop000 lib]$ jps
1509 NameNode
31766 RunJar # 正在执行的Hive进程
1959 ResourceManager
35415 Jps
1608 DataNode
35400 MRAppMaster
1802 SecondaryNameNode
2062 NodeManager
[hadoop@hadoop000 lib]$ kill -9 31766 # 可以终止进程,
- 拓展
- crontab表达式进行调度
- Azkaban调度:ETLApp==>其他的统计分析
- PySpark及调度系统