一. Hive架构说明
- Hive是什么
- Hive是一款基于Hadoop的数据仓库软件,用于处理Hadoops上的结构化数据,使查询,分析变得简单。
- Hive是最初由FaceBook公司开发,后来又Apache软件基金会开发,成为Apache的顶级项目。
- Hive适用场景
基于Hadoop的离线数据分析(Hive, Spark On Hive , Hive On Spark) - Hive不适用场景
- Hive不适用当做关系型数据库使用
- Hive不适用OLTP场景
- Hive不支持实时查询(Hive从0.14版本开始支持事务和行级更新,但缺省是不支持的,需要一定附加的配置)
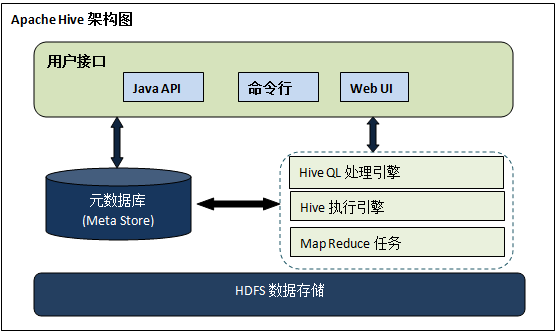
- Hive架构
- Hive是一个以表的形式来访问HDFS数据的客户端,可以使用HiveQL进行数据分析处理。HQL的执行会提交给Hadoop集群,产生一个或者多个job,以MapReduce任务来执行。
- Hive的表定义信息,数据库定义信息和表,数据库与HDFS上数据的对应关系信息数据Hive元数据,存储在metastore中。
- metastore支持三种运行模式:
- 嵌入式metastore 如:derby
- 本地metastore 如:本地MySQL
-
远程metastore 如:远程MySQL
 hive_frameword_1.png
hive_frameword_1.png
 图片1.png
图片1.png
一.MySQL的安装
yum list installed | grep mysql #检查是否已安装mysql
yum -y remove mysql-libs.x86_64 # 卸载已安装mysql
rpm -qa | grep mysql #查看mysql是否已卸载成功
yum list | grep mysql #查看yum上提供的mysql数据库下载版本
#使用过yum来安装mysql
# mysql-devel 是开发用到的库及包文件
# mysql 是mysql客户端
# mysql-server 是mysql数据库服务器
yum install -y mysql-server mysql mysql-devel
rpm -qi mysql-server #查看安装的mysql版本
# 启动过程说明:第一次启动mysql服务,mysql服务器首先进行初始化的配置,会提示非常多的信息,目的就# 是对mysql数据库进行初始化操作,当再次启动mysql服务是,就不会提示这么多信息。如果再次启动
# service mysqld restart
service mysqld start # 启动mysql服务
chkconfig --list | grep mysqld # 查看mysql服务是否开机自启动
chkconfig mysqld on #将mysql设置为开机自启动
mysqladmin -u root password '123456' #给root账号设置密码为123456
###登录数据
mysql -u root -p #登录mysql数据库
show databases; #查看所有数据库
create database hive; #创建名称为hive的数据,用于存储hive的元数据
### root用户授权,使其能从外部IP访问mysql数据库;
grant all privileges on *.* to 'root'@'%' identified by '123456';
flush privileges; #使授权立即生效
从windows环境了解mysql
删除user表下面的无用信息(只留下root用户)
二.Hive安装
- hive下载
下载地址
官网 - 拷贝hive到linux系统中
$ scp /c/Users/zt/Desktop/大数据/apache-hive-2.1.1-bin.tar.gz [email protected]:/opt/soft
cd /opt/soft/
chmod 777 *
- hive解压到指定目录
cd /opt/soft/
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C /opt/modules/
- hive环境变量设置
vi /ect/profile
exoprt HADOOP_HOME=/opt/modules/hadoop-2.5.5
export HIVE_HOME=/opt/modules/apache-hive-2.1.1-bin #hive安装目录
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:
source /ect/profile #使环境变量立即生效
- 创建临时目录
cd /opt/modules/apache-hive-2.1.1-bin
mkdir tmp #临时文件目录
mkdir log #日志文件目录
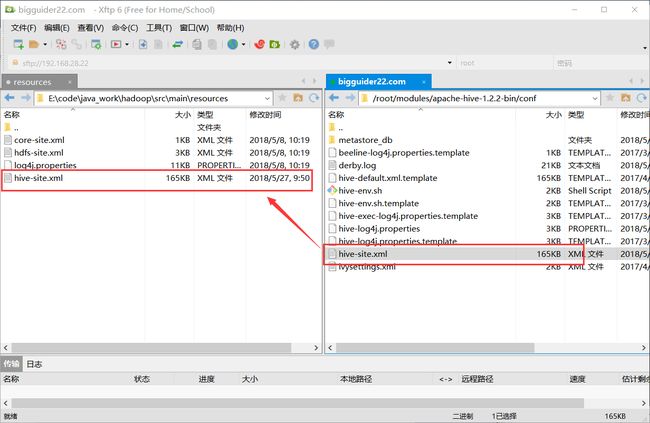
- 修改配置文件
cd /opt/modules/apache-hive-2.1.1-bin/conf/
cp cp hive-default.xml.template hive-site.xml #复制模板文件
cp hive-env.sh.template hive-env.sh
cp hive-log4j.properties.template hive-log4j.properties #复制日志模板
# 修改 hive-env.sh 文件(添加)
vi hive-env.sh
export HADOOP_HOME=hadoop安装路径
export HIVE_CONF_DIR=hive安装路径/conf
vi hive-site.xml
# hive.metastore.warehouse.dir的默认值为/user/hive/warehouse,保持不变
# 更换存储元数据的数据库:
# javax.jdo.option.ConnectionURL // 数据库URL
# javax.jdo.option.ConnectionDriverName // JDBC 驱动名称
# javax.jdo.option.ConnectionUserName // 数据库用户名
# javax.jdo.option.ConnectionPassword // 数据库密码
javax.jdo.option.ConnectionURL
jdbc:mysql://bigdata02:3306/hive?createDatabaseIfNotExist=true
JDBC connect string for a JDBC metastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
Driver class name for a JDBC metastore
javax.jdo.option.ConnectionUserName
root
username to use against metastore database
javax.jdo.option.ConnectionPassword
123456
password to use against metastore database
hive.cli.print.header
true
Whether to print the names of the columns in query output.
hive.cli.print.current.db
true
Whether to include the current database in the Hive prompt.
# 把所有 ${system:java.io.tmpdir} 改成 /opt/hive211/tmp //上步骤中创建的tmp目录
# 把所有 ${system:user.name} 改成 ${user.name}
#修改日志文件
vim hive-log4j.properties
hive.log.dir=/root/modules/apache-hive-1.2.2-bin/log
- 在hdfs创建目录
hdfs dfs -mkdir /tmp //hive的默认临时文件目录
hdfs dfs -mkdir -p /user/hive/warehouse //hive的warehouse默认目录
hadoop fs -chmod g+w /tmp //为tmp目录授权
hadoop fs -chmod g+w /user/hive/warehouse //为目录授权
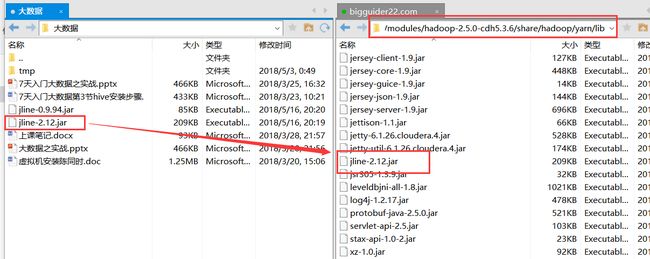
- 上传mysql驱动包
我们配置了hive的元数据库为mysql,hive连接mysql,需要mysql的jdbc驱动包 ,所以,需要将驱动包上传到$HIVE_HOME/lib 目录下 - 初始化hive元数据库
cd /opt/modules/apache-hive-2.1.1-bin/bin
schematool -dbType mysql -initSchema [--verbose]
如果初始化失败
- 检查hive是否安装成功
hive #如果进入hive命令模式自己是成功
三.Hive基本使用
- hive中的表的概念与关系型数据库中表的概念非常类似。
- hive中的每一张表都和HDFS上/user/hive/warehouse(默认,在¥{HIVE_HOME}/conf/hive-site.xml中设置)中的一个目录相关联。
- 例如:在hive默认数据库中创建的表t_customer对应的目录为/user/hive/warehouse/t_customer,t_customer表中的所有数据都会保存在这个目录中。
3.1Hive-database相关操作
# 4.1 创建数据库
# CREATE DATABASE|SCHEMA [IF NOT EXISTS] <数据库名称> [LOCATION '本地路径'] #创建数据库
create database if not exists hive_db; #创建数据库hive_db,查看HDFS上的warehouse目录
# 4.2 删除数据
# DROP DATABASE|SCHEMA [IF EXISTS] <数据库名称> [RESTRICT|CASCADE] #删除数据库
# 4.3 查看数据
show databases;
# 4.4 切换数据库
use hive_db;
3.2表的相关操作
# 4.5 表的创建
# 第一种方式
# create table if not exists 表名 (
# id int,name string)
# row format delimited fields terminated by '\t' //设置分割符
# lines terminated by '\n' //设置换行符
# stored as textfile; //设置存储格式,默认textfile
# 第二种方式
# create table 表名 as select * from 表名;//根据另一种表的查询结果创表,用于查询结果的保存
#第三种方式
# create table 表名 like 表名;//根据一张表的结构创建另一种表
CREATE TABLE IF NOT EXISTS t_customer ( id int, name String,age Int, address String)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
# 4.6 查看表结构
desc t_customer;
desc formatted t_customer;
desc extended t_customer;
# 4.7 删除表
drop table if exists t_customer ;
# 清空表的内容,保留表的结构
truncate table student;
# 显示所有表
show tables [in 库名];
alter table student rename to ss; #表的重命名
alter table ss add columns (age int); #表添加字段
alter table ss change age point string;#修改字段名及类型
alter table ss replace columns(point string);
select * from student where num < 4;
select * from student limit 2;
select * from student where num between 1 and 6;
select * from student where name is not null;
select * from student where name is null;
select distinct name from student;
3.3Hive--数据的导入导出
# 4.3.1 导入数据
# LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
# LOAD DATA:加载数据到Hive的命令关键字
# LOCAL:包含加载本地文件中的数据到Hive中,
# 不包含从HDFS上加载数据Hive中,具体路径有Hadoop配置文件中的fs.default.name属性决定
# INPATH 'filepath': 使用LOCAL,路径为:file:///user/hive/example
# 不适用LOCAL,路径为:hdfs://namenode:9000/user/hive/example
# OVERWRITE: 如果使用了OVERWRITE,那么覆盖表中已有数据;
# 如果没有使用OVERWRITE,那么追加表中已有数据;
# INTO TABLE tablename:tablename是Hive中的表名
## 4.3.2 导入数据
# 导入本地数据(数据文件编码需要UTF-8编码,否则出现中文乱码)
LOAD DATA LOCAL INPATH '/hadoop/data/customer.txt' OVERWRITE INTO TABLE T_CUSTOMER;
# 导入HDFS数据(此方法会删除testdata目录下的customer.txt文件。如何避免?使用外部表)
# 上传数据到HDFS
hdfs dfs -put /hadoop/data/customer.txt /testdata
LOAD DATA INPATH '/testdata/customer.txt' INTO TABLE T_CUSTOMER;
# 其他导入方法(使用查询导入数据,java API插入数据,import命令数据导入等)
#将另外一张表的数据导入到一张表中
insert into table 表名 select * from 表名
#导入数据
import table 表名 to 'hdfs_path'
# 将查询的结果导出到指定目录
insert overwrite [local] directory '路径' [row format delimited fields terminated by '\t'] select sql;
# dfs -get hdfs_path local_path
# export table 表名 from 'hdfs_path'
3.4Hive数据查询
select * from student;
3.5Hive函数相关
#查看函数
show functions;
#描述函数
desc functions 函数;
3.6Hive内部表外部表分区表
内部表:前面创建的t_customer表成为内部表,其数据存储于warehouse中,未被external修饰的表,由hive管理,删除内部表会直接删除元数据(metadata)及存储数据
外部表:如果数据已经存在于HDFS上面,此时可以创建一个外部表来查询或描述这类数据。之所以称为外部表,是因为其数据不存在warehouse中,而存在于location声明的目录中,被external修饰的表,由HDFS管理,删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除。
分区表:在系统下建立文件夹,把分类数据放到同文件夹下面,加快查询速度。
-
内部表和外部表的区别
- Hive对其的生命周期管理方面不同
- 如果drop一个内部表,表中的数据、元数据会一起删除
- 如果drop一个外部表,表的元数据会删除,但是其中的数据不会被删除。
- 外部表可以避免数据的误删除。
# 1. 创建外部表
# 上传数据customer.txt到HDFS /testdata目录
CREATE EXTERNAL TABLE t_customer_external ( id int, name String,age Int, address String)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
LOCATION '/testdata';
# 注意:LOCATION '/testdata'子句位置在最后;LOCATION 对应的值是个目录
# 2. 查询外部表
select * from t_customer_external
# 3. 删除外部表
drop table t_customer_external //验证内部表和外部表的删除操作,结果的不同之处
# 4.创建分区表
create table student(
num int,
name string)
partitioned by (age int,point int)
row format delimited fields terminated by '\t';
# 导入数据
load data local inpath '本地路径' into table student partition (age='18',point='70');
3.7Hive常用shell命令
#帮助
hive -help
#指定默认连接的数据库
hive --database hive_db;
#在liunx命令行执行sql或者HQL语句
hive -e 'show databases';
#在linux命令行执行sql文件
hive -f /opt/datas/hive.sql
#是当前shell配置临时生效
hive --hiveconf hive.cli.print.current.db=false
#进入hive默认
# 查看当前参数的设置的值
set hive.cli.print.current.db;
set -v #查看所有配置
#查看本地目录信息
!ls /;
# 查看HDFS目录信息
dfs -ls /; #能执行dfs相关命令,并且速度比hdfs直接读取快(少了读取配置步骤)
3.8Hive分析函数
官网地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
- 过滤条件:where /limit/distinct/between and/null/is not null/case when then
- 聚合函数:count/sum/avg/max/min/group by/having by
- join: left join/right join/inner join/full join
测试数据准备
create table if not exists student(
id int,
name string,
birthaday string,
result int,
bonuspoint int,
grade int)
row format delimited fields terminated by '\t'
lines terminated by '\n'
stored as textfile;
vim student.txt
1 张三 1990-11-1 88 12 1
2 李四 1991-02-1 56 34 2
3 王五 1990-03-4 79 57 3
4 随其 1899-10-4 45 88 2
5 轻轻 1899-11-3 99 33 3
6 走吗 1997-12-4 65 55 3
7 梦革 1994-11-3 78 56 1
8 肚饿 1999-11-2 98 49 1
9 非配 1879-07-2 22 55 2
hive>load data local inpath "/root/datas/hive_db/student_new.txt" overwrite into table student;
select * from student;
select * from student order by result desc;
#分区
select id,name,grade,result,max(result) over(
partition by grade
order by result desc
) as max_result
from student;
#未分区
select id,name,grade,result,
max(result) over(
order by result desc
) as max_ac
from student;
#行号
select id,name,grade,result,
row_number() over(
partition by grade
order by result desc
) as row_n
from student;
select id,name,grade,result,top from (
select id,name,grade,result,
row_number() over(
partition by grade
order by result desc
) as top
from student) result_t_top
where top <3;
select * from student where result> 50;
select * from student order by result limit 3;
select id,name,grade,result,
case when id>'5' then 100
else name end c_name
from student;
#count()总数
select count(1) from student;
#avg平均值
select avg(result) avg_result from student;
select grade,avg(result) avg_result from student
group by grade;
select grade,avg(result) avg_result from student
group by grade having avg_result>80;
#left join/right join/inner join/full join
select * from A left join B on A.id=B.id;
select * from A right join B on A.id=B.id;
select * from A inner join B on A.id=B.id;
select * from A full join B on A.id=B.id;
#全局排序
select * from student order by result;
#设置当前reduce个数
set mapreduce.job.reduces=3;
select * from student sort by result;
##局部排序
insert overwrite local directory '/root/datas/hive_db/out_data_sort'
row format delimited fields terminated by '\t'
select * from student sort by result;
##distribute by 分区
insert overwrite local directory '/root/datas/hive_db/out_data_distribute'
row format delimited fields terminated by '\t'
select * from student distribute by grade sort by result;
##cluster by 分区排序
insert overwrite local directory '/root/datas/hive_db/out_data_cluster'
row format delimited fields terminated by '\t'
select * from student cluster by result;
修改配置文件
vim hive-site.xml
hive.exec.reducers.bytes.per.reducer
256000000
size per reducer.The default is 256Mb, i.e if the input size is 1G, it will use 4 reducers.
hive.exec.reducers.max
1009
max number of reducers will be used. If the one specified in the configuration parameter mapred.reduce.tasks is
negative, Hive will use this one as the max number of reducers when automatically determine number of reducers.
mapreduce.job.reduces
3
hive.fetch.task.conversion
more
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
3.9自定义函数UDF
1.配置环境
pom.xml添加依赖
org.apache.hive
hive-exec
1.2.2
org.apache.hive
hive-jdbc
1.2.2
2.编写代码
package com.guider.hadoop.udf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.IntWritable;
public class HiveUdf extends UDF {
public String evaluate(IntWritable result){
String tmpresult = "";
if (result != null){
if (result.get() >= 0 && result.get() < 80){
tmpresult="不及格";
} else if (result.get() < 90){
tmpresult = "良";
} else {
tmpresult = "优秀";
}
}else {
tmpresult = "成绩为空,请核实";
}
return tmpresult;
}
}
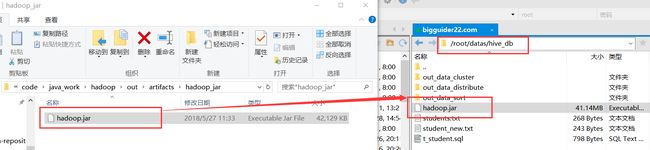
3.导出jar包并置入本地环境
4.关联jar包,并创建临时函数
#add jar jar包路径
hive>add jar /root/datas/hive_db/hadoop.jar;
#create temporary function 函数名 as '包名.类名'
hive>create temporary function my_udf as 'com.guider.hadoop.udf.HiveUdf';
#HDFS
#create temporary function 函数名 as '包名.类名' using jar 'hdfs://bigguider22.com:8020/udf.jar'
#永久生效
#将hive的jar添加到hive环境变量中,编辑hive的源码。
#执行
hive (hive_db)> select id,name,grade,my_udf(result) my_udf from student;
OK
id name grade my_udf
1 张三 1 良
2 李四 2 不及格
3 王五 3 不及格
4 随其 2 不及格
5 轻轻 3 优秀
6 走吗 3 不及格
7 梦革 1 不及格
8 肚饿 1 优秀
9 非配 2 不及格
5.出现的异常
原因:jar的java版本与hive的java版本不匹配
java.lang.UnsupportedClassVersionError: com/guider/hadoop/udf/HiveUdf : Unsupported major.minor version 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at java.lang.ClassLoader.loadClass(ClassLoader.java:412)
at java.lang.ClassLoader.loadClass(ClassLoader.java:412)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:270)
at org.apache.hadoop.hive.ql.exec.FunctionTask.getUdfClass(FunctionTask.java:309)
at org.apache.hadoop.hive.ql.exec.FunctionTask.createTemporaryFunction(FunctionTask.java:165)
at org.apache.hadoop.hive.ql.exec.FunctionTask.execute(FunctionTask.java:72)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:160)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:88)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1676)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1435)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1218)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1082)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1072)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:213)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:165)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:376)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:736)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:681)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.FunctionTask. com/guider/hadoop/udf/HiveUdf : Unsupported major.minor version 52.0
3.10虚拟列
此列并未在表中正式存在,其用意是为将Hive中的表进行分区(partition),对每日增长的海量数据存储有用。
# INPUT__FILE__NAME 这行数据属于哪个文件
select *,input__file__name from student;
# BLOCK__OFFSET__INSIDE__FILE块的偏移量
select *,block__offset__inside__file from student;
3.11 HiveServer2
HiveServer是一种可选服务,允许远程客户端可以使用各种编程语言向Hive提交并检测结果。
#启动方式
bin/hiveserver2
bin/hive --service hiveserver2
bin/hiveserver2 --hiveconf hive.server2.thrift.port="10000"
#连接
beeline
!connect jdbc:hive2://bigguider22.com:10000
bin/beeline -u jdbc:hive2://bigguider22.com:10000 -n root -p 123456
*远程客户端
官网:https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-JDBC
package com.guider.hadoop.hive_db;
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
//1.2.0后不需要添加,用户定义驱动名称
//private static String driverName = "org.apache.hive.jdbc.HiveDriver";
/**
* @param args
* @throws SQLException
*/
public static void main(String[] args) throws SQLException {
// try {
// Class.forName(driverName);
// } catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
// e.printStackTrace();
// System.exit(1);
// }
//replace "hive" here with the name of the user the queries should run as
Connection con = DriverManager.getConnection("jdbc:hive2://bigguider22.com:10000/hive_db", "root", "123456");
//创建一条语句
Statement stmt = con.createStatement();
//定义表名称
//String tableName = "testHiveDriverTable";
//实例化
//stmt.execute("drop table if exists " + tableName);
//stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "select * from student"; //不能使用分号
System.out.println("Running: " + sql);
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1)+"\t"+res.getString(2));
}
}
}
3.12正则处理
正则匹配:用于解决字段中包含分隔符等特殊符号。
官方案例:https://cwiki.apache.org/confluence/display/Hive/GettingStarted#GettingStarted-ApacheWeblogData
测试:
vim log.txt
"10.0.0.2" "31/Aug/2015:00:04:37 +0800" "303" "http://www.cniao5.com/user.php?act=mycourse" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36" "learn.cniao5.com"
create table t_apache_log(
remote_addr string,
time_local string,
status string,
http_referer string,
http_user_agent string,
host string)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
"input.regex"="(\"[^ ]*\") (\"[^}]*\") (\"[0-9]*\") (\"[^ ]*\") (\"[^}]*\") (\"[^ ]*\")"
)
stored as textfile;
load data local inpath '/root/datas/hive_db/log.txt' into table t_apache_log;
select * from t_apache_log;
#时间处理:应用场景:网站停留时间统计
select unix_timestamp("2017-12-31 00:00:00");
select from_unixtime(1486543750);
select unix_timestamp('201712331 00:00:00','yyyyMMdd HH:mm:ss');
add jar /root/datas/hive_db/hadoop.jar;
create temporary function change_time as 'com.guider.hadoop.udf.HiveTimeChangeUdf';
select time_local,change_time(time_local) from t_apache_log;
time_local _c1
"31/Aug/2015:00:04:37 +0800" 2015-08-31 00:04:37
3.13优化处理
- 表拆分:大表拆分小表,分区表(优化搜索),外部表(数据安全),临时表(处理简单化)
- MR优化:map和reduce个数
一个分片就是一个块,一个块对应一个maptask,Hadoop源码中的公式min(max_split_size,max(min_split_size,block_size)),决定了map的个数- min_split_size默认值0(最小分片大小)
- block_size,block_size默认是128
- max_split_size默认值256(最大分片大小)
一般在实际的生产环境中HDFS一旦format格式化之后,block_size大小不会去修改的通过修改max_split_size和min_split_size来影响map的个数
- 并行执行
针对有些互相没有依赖关系的独立的job,可以选择并发的执行job
#一般在工作中会选择去开启该功能
set hive.exec.parallel
#根据实际的集群的状况和服务器的性能合理的设置线程数目
set hive.exec.parallel.thread.number
- JVM重用
# MR默认jvm运行,开启JVM开启多个任务
# 开启数目需测试
set mapreduce.job.jvm.numtasks
- 推测执行:
# 当某个任务出现迟迟不结束的情况,开启推测执行会开启一个一模一样的任务,其一完成关闭另一个。
# 分为map端的推测和reduce端的推测,过多的消耗资源,可能会出现重复写入的情况
set mapreduce.map.speculative
set mapreduce.reduce.speculative
- hive本地模式
# 开启限制
# 数据大小不能超过128MB
# map不能超过4个
# reduce的个数不能超过1个
set hive.exec.mode.local.auto
sqoop安装配置
下载地址:http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.5-cdh5.3.6.tar.gz
tar -zxvf software/sqoop-1.4.5-cdh5.3.6.tar.gz -C modules/
cd sqoop-1.4.5-cdh5.3.6/conf/
cp sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
export HADOOP_COMMON_HOME=/root/modules/hadoop-2.5.0-cdh5.3.6
export HADOOP_MAPRED_HOME=/root/modules/hadoop-2.5.0-cdh5.3.6
export HIVE_HOME=/root/modules/apache-hive-1.2.2-bin

sqoop简介
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如Hbase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。因此,可以说Sqoop就是一个桥梁,连接了关系型数据库与Hadoop。qoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。
sqoop使用
1. 数据准备
mysql -u root -p123456
create database sqoop_db;
use db_sqoop;
create table db_mysql(
id int primary key not null,
name varchar(20) not null);
insert into db_mysql value('0','0');
insert into db_mysql value('1','1');
insert into db_mysql value('2','2');
insert into db_mysql value('3','3');
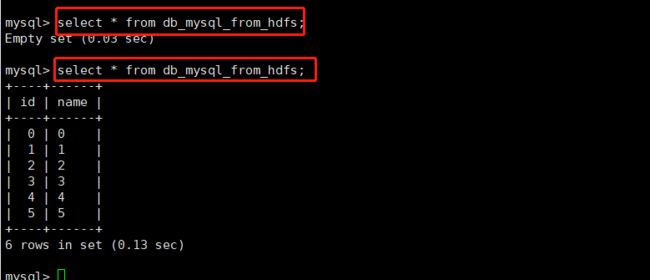
create table db_mysql_from_hdfs (
id int primary key not null,
name varchar(20) not null);
2. mysql -> hdfs
bin/sqoop import \
--connect jdbc:mysql://bigguider22.com:3306/sqoop_db --username root --password 123456 \
--direct \
--table db_mysql \
--target-dir /user/root/db_sqoop \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by '\t'
mysql> insert into db_mysql value('4','4');
bin/sqoop import \
--connect jdbc:mysql://bigguider22.com:3306/sqoop_db --username root --password 123456 \
--direct \
--table db_mysql \
--target-dir /user/root/db_sqoop \
--num-mappers 1 \
--fields-terminated-by '\t' \
--check-column id \
--incremental append \
--last-value 3
mysql> insert into db_mysql value('5','5');
bin/sqoop job --help
bin/sqoop job --list
bin/sqoop job \
--create addnum_job \
-- import \
--connect jdbc:mysql://bigguider22.com:3306/sqoop_db --username root --password 123456 \
--direct \
--table db_mysql \
--target-dir /user/root/db_sqoop \
--num-mappers 1 \
--fields-terminated-by '\t' \
--check-column id \
--incremental append \
--last-value 4
bin/sqoop job --list
bin/sqoop job --show addnum_job
bin/sqoop job --exec addnum_job
bin/sqoop job --delete addnum_job

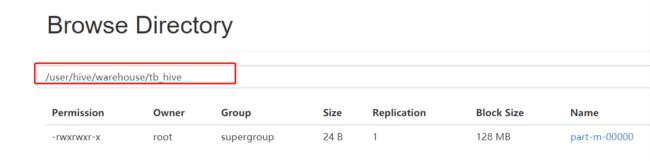
3. mysql -> hive == mysql -> hdfs +文件转移到表的对应目录
bin/sqoop import \
--connect jdbc:mysql://bigguider22.com:3306/sqoop_db --username root --password 123456 \
--direct \
--table db_mysql \
--hive-import \
--hive-table tb_hive \
--num-mappers 1 \
--fields-terminated-by '\t'
4. hdfs -> mysql
bin/sqoop export \
--connect jdbc:mysql://bigguider22.com:3306/sqoop_db --username root --password 123456 \
--direct \
--table db_mysql_from_hdfs \
--export-dir /user/root/db_sqoop \
--num-mappers 1 \
--fields-terminated-by '\t'
Hive压缩配置
- 压缩目的:
减少磁盘IO与网络IO -
压缩配置:
 image.png
image.png
tar -zxvf /root/software/2.5.0-native-snappy.tar.gz -C /root/modules/hadoop-2.5.0-cdh5.3.6/lib/native
hadoop checknative
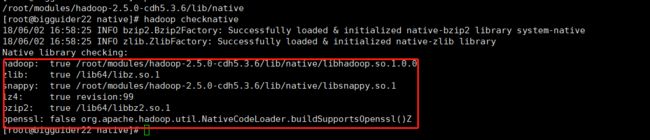
- Snappy文件获取方式(待完善)
- 参考hadoop源码下的BUILDING.txt进行编译
- 下载snappy库文件
官方网站:http://google.github.io/snappy/ - 安装linux下的snappy,将相关jar包放到lib文件夹下
- 编译
-
压缩总结(压缩方式是否支持可分割性)
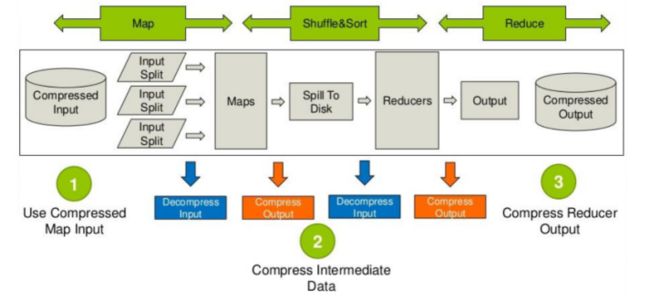 image.png
image.png
- 压缩格式:bzip2,gzip,lzo,snappy
- 压缩比:bzip2 > gizp > lzo
- 压缩速度:bzip2 < gzip < lzo
-
不同压缩方式对应不同类
 image.png
image.png
- Zlib -> org.apache.hadoop.io.compress.DefaultCodec
- Gzip -> org.apache.hadoop.io.compress.GzipCodec
- Bzip2 -> org.apache.hadoop.io.compress.BZip2Codec
- Lzo -> com.hadoop.compression.lzo.LzoCodec
- Lz4 -> org.apache.hadoop.io.compress.Lz4Codec
- Snappy -> org.apache.hadoop.io.compress.SnappyCodec
- 压缩方案
- MapReduce配置map端压缩:
mapreduce.map.output.compress=true
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
- MapReduce配置Reduce端压缩:
mapreduce.output.fileputputformat.compress=true
mapreduce.output.fileputputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec
- Hive配置压缩:
hive.exec.compress.intermediate=true
mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
mapred.output.compression.type=BLOCK
- 任务中间压缩:
hive.exec.compress.intermediate=true
hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec
hive.intermediate.compression.type=BLOCK
- 例子
yarn jar /root/modules/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount \
/user/root/mapreduce/input/wordcount.txt \
/user/root/mapreduce/output3
yarn jar /root/modules/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount \
-D mapreduce.map.output.compress=true \
-D mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec \
/user/root/mapreduce/input/wordcount.txt \
/user/root/mapreduce/output4
yarn jar /root/modules/hadoop-2.5.0-cdh5.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0-cdh5.3.6.jar wordcount \
-Dmapreduce.map.output.compress=true \
-Dmapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec \
/user/root/mapreduce/input/wordcount.txt \
/user/root/mapreduce/output5
数据倾斜
- 数据倾斜原因:
- key分布不均匀
- map端数据倾斜,输入文件太多且大小不一
- reduce端数据倾斜,分区器问题
- 业务本身的特征
- 建表时考虑不周
- 某些SQL语句本身就有数据倾斜
- 造成数据倾斜的操作:
- join,group by,count distinct
- 数据倾斜的现象:
- 任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成;查看未完成的子任务,可以看到本地读写数据量积累非常大,通常超过10GB可以认定为发生数据倾斜。
- 单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
- 如何解决数据倾斜:
- 调节hive配置
#map端部分聚合,相当于Combiner
set hive.map.aggr=true
#数据倾斜时负载均衡,当选项设定为true,生成的查询计划会有两个MRJob。第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
set hive.groupby.skewindata=true
- sql语句优化:大小表进行连接时,使用map join让小表先进内存,在map端完成reduce。
大表连接大表时,如果是空值造成数据倾斜,那么把空值变成一个字符串加上随机数,把这部分倾斜的数据分发到不同的reduce上。
如果count distinct有大量相同特殊值 (如空值) 空值可以不用处理,直接最后count结果加1即可。或者空值单独拿出来处理,最后再union回去。
不同数据类型关联 默认的hash操作会按其中一种类型的值进行分配,导致别一种类型全部分发到同一个reduce中。把两个关联的类型转换成相同类型。
select * from log a where a.user_id is null;
select * from users a left outer join logs b on a.usr_id = cast(b.user_id as string);
- 参考:http://www.xuebuyuan.com/2129584.html
- 在 key 上面做文章,在 map 阶段将造成倾斜的key 先分成多组,例如 aaa 这个 key,map 时随机在 aaa 后面加上 1,2,3,4 这四个数字之一,把 key 先分成四组,先进行一次运算,之后再恢复 key 进行最终运算。
- 能先进行 group 操作的时候先进行 group 操作,把 key 先进行一次 reduce,之后再进行 count 或者 distinct count 操作。
- join 操作中,使用 map join 在 map 端就先进行 join ,免得到reduce 时卡住。