伪分布模式
设备: 一台 linux
特点: 在单机上模拟分布式环境,拥有Hadoop所有功能
配置文件:hadoop-env.sh, mapred-env.sh、yarn-env.sh、core-site.xml, hdfs-site.xml, mapred-site.xml, yarn-site.xml
一、 设置Hadoop用户
二、 Hadoop安装&配置
三 、启动HDFS & YARN
四、 测试MapReduce Job
五 、总结
一、 设置Hadoop用户
step1: 创建新的普通用户hadoop
创建hadoop用户出于保障 hdfs 的数据安全性,给不同的用户赋予不同权限
输入: su - 切换root用户
输入: useradd hadoop 添加hadoop用户
输入: passwd hadoop 输入hadoop用户的登陆密码

step2:赋予hadoop用户sudo权限
一般root用户无权修改sudoers, 先手动为root用户添加写权限
输入:chmod u+w /etc/sudoers 为root用户添加写权限
输入: vim /etc/sudoers 打开sudoers文件
输入: i 键 进入编辑模式
输入:hadoop ALL=(root) NOPASSWD:ALL 添加hadoop权限

输入: Esc 键,输入 :wq 保存并退出
在学习环境可将hadoop用户的权限设置的大一些,但实际生产环境一定要注意普通用户的权限限制
step3:切换到hadoop用户
输入: su - hadoop
二、 Hadoop安装&配置
step4:解压hadoop
hadoop下载教程:https://www.jianshu.com/p/a28e2305a48c
输入: sudo mkdir /opt/modules 创建目录,存放hadoop文件
输入: sudo chown -R hadoop:hadoop /opt/modules 将存放hadoop的目录指定为hadoop用户,避免hadoop运行过程存在的权限问题
chown 命令用来修改目录的权限
-R 递归,就是从当前目录到子目录
hadoop:hadoop 将目录和文件的owner和group都设成 hadoop
本人已将hadoop压缩包放在 /opt /software
输入: cp hadoop-2.2.0.tar.gz /opt / modules 将hadoop压缩包复制到 /opt / modules目录下

输入: tar -zxvf hadoop-2.2.0.tar.gz 解压hadop压缩包,直接用
step5:配置hadoop环境变量
输入: sudo vim /etc/profile 打开profile目录配置环境变量
输入: i 键 进入编辑模式
输入: export HADOOP_HOME = /opt /modules / hadoop-2.2.0
export PATH = $PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

输入: Esc 键,输入 :wq 保存并退出
step6:配置 hadoop-env.sh、mapred-env.sh、yarn-env.sh文件JAVA_HOME参数
输入: sudo vim hadoop-env.sh 打开 hadoop-env.sh文件

输入: i 键 进入编辑模式
输入: export JAVA_HOME = /usr / local / java / jdk.1.8.0_181
添加JAVA_HOME路径

输入: Esc 键,输入 :wq 保存并退出
(可输入 echo $JAVA_HOME 查看 JAVA_HOME 环境变量)
输入: source /etc/profile 重新执行profile 文件使其生效
配置mapred-env.sh、yarn-env.sh文件JAVA_HOME参数,同理
step7:配置 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 文件
这几个配置文件放置在 hadoop安装目录下 /hadoop-2.2.0/etc/hadoop/

若发现没有存在mapred-site.xml, 但存在mapred-site.xml.template
直接复制,重命名一个mapred-site.xml就可以
输入 : cp mapred-site.xml.template mapred-site.xml

接下来,逐个来配置这几个文件
(1) 配置 core-site.xml
配置参数 : fs.defaultFS 配置HDFS的NameNode的地址
hadoop.temp.dir 配置HDFS数据保存的目录。默认是Linux的tmp目录,由于系统启动,会清空默认的tmp目录,导致NameNode数据丢失,所以需要创建新的tmp目录
输入: sudo mkdir -p /opt /modules/hadoop-2.2.0/tmp 本人在hadoop安装目录下创建tmp目录,来存放HDFS数据,你可自行创建别处目录进行存放

输入: sudo vim core-site.xml 打开core-site.xml文件
配置core-site.xml参数信息

fs.defaultFS ,hdfs的 ip,默认端口号 8020
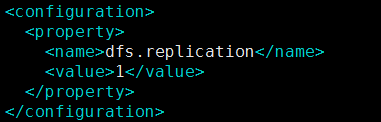
(2) 配置 hdfs-site.xml
配置参数 : dfs.replication HDFS存储时的备份数量,默认是3, 伪分布设为1
输入: sudo vim hdfs-site.xml 打开 hdfs-site.xml文件
配置 hdfs-site.xml 参数信息
(3) 配置 mapred-site.xml
配置参数 : mapredure.framework.name 配置mapredure程序运行的容器是Yarn
输入: sudo vim mapred-site.xml 打开mapred-site.xml文件
配置mapred-site.xml参数信息

(4) 配置 yarn-site.xml
配置参数 : yarn.resourcemanager.hostname 配置ResourceManager的主机地址
yarn.nodemanager.aux-services 配置NodeManager运行mapredure任务的方式
输入: sudo vim yarn-site.xml 打开yarn-site.xml文件
配置mapred-site.xml参数信息

三 、启动HDFS & YARN
step8: 格式化 HDFS
格式化是对HDFS中的DataNode进行分块,并将分块后的原始元数据存于NameNode中。
输入: bin/hdfs namenode -format 格式化NameNode

格式化成功后,可在 temp 目录中生成 dfs 目录
输入: ll temp/dfs/name/current 查看NamaNode格式化后的目录

fsimage NameNode在元数据内存满了后的持久化文件
fsimage*.md5 校验文件,校验fsimage的完整性
seen_txid hadoop的版本
vession 保存namesopaceID(NameNode的唯一ID)和 clusterID(集群ID)
输入: cat tmp/dfs/name/current/VERSION 可查看vession中内容

step8: 启动 HDFS & YARN
方法 1 同时全部启动
输入: start-all.sh 同时全部启动
启动都命令存放于 hadoop-2.2.0 / sbin / 目录下
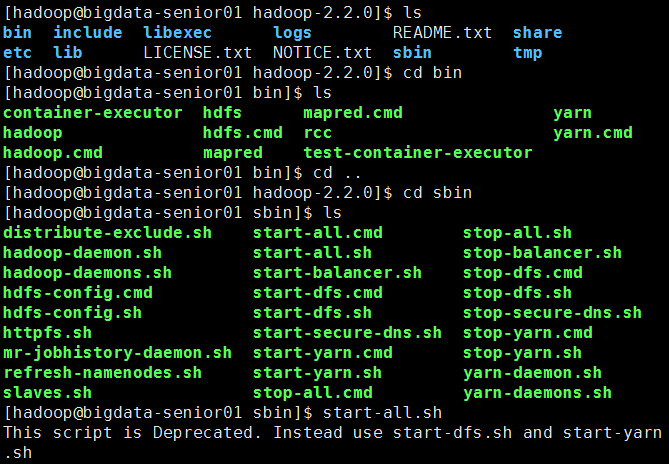
输入: jps 查看是否启动成功

方法 2 逐个启动
输入: hadoop-daemon.sh start namenode 启动NameNode
输入: hadoop-daemon.sh start datanode 启动DataNode
输入: hadoop-daemon.sh start secondarynamenode 启动SecondaryNameNode
输入: yarn-daemon.sh start resourcemanager 启动ResourceManager
输入: hadoop-daemon.sh start nodemanager 启动NodeManager
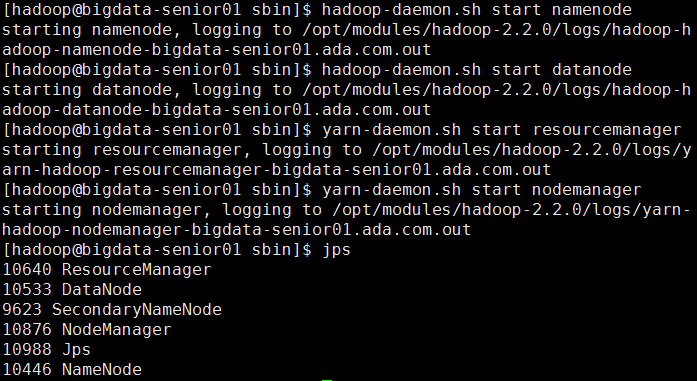
输入: jps 可查看是否启动成功
通过 http://192.168.100.10:8088/ 可以查看YARN的Web页面,YARN Web端的端口号是8088

停止 hadoop的命令,对应的使用 stop
四、 测试MapReduce Job
Hadoop 自带的 WordCount 程序 hadoop-mapreduce-examples-2.2.0.jar,存放于hadoop安装目录的 share/hadoop/mapreduce/ 路径下, 可用该程序来进行测试
Hadoop 自带的 WordCount程序,单词统计的功能,因此先创建一个文本作为输入文件
step9:创建输入文件
输入: sudo vim /opt/data/wc.input 创建wc.input文件
打开文件后, 按 i 键进入编辑模式,输入单词(it's up to you)

输入完成后,按 Esc 键退出编辑模式,按 :wq 保存并退出
输入: hdfs dfs -put /opt/data/wc.input /wordcountdemo/input 将wc.input文件上传到HDFS的/wordcountdemo/input目录下

输入: yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /wordcountdemo/input /wordcountdemo/output
运行功能的 .jar 包,wordcount是 jar包 需要运行的主类,wc.input 为输入的文本参数,输出结果保存到output目录下



Hadoop Job的运行记录中,可知输入文件有1个(Total input paths to process:1)
这个Job被赋予了一个ID号:job_1535711820644_0001
同时还可以看到map和reduce的job记录
输入: hdfs dfs -ls /wordcountdemo/output 查看输出结果目录

_SUCCESS文件 说明运行成功
part-r-00000 是输出结果文件,-r- 说明这个文件是Reduce阶段产生的结果。mapreduce程序执行中,可以没有reduce阶段,但是肯定有map阶段,如果没有reduce阶段则显示是-m-
一个reduce会产生一个 part-r-开头的文件
输入: hdfs dfs -cat /wordcountdemo/output/part - r -0000 查看输出文件的内容,结果按照键值排序而成

五 、总结
Hadoop各模块的学习理解
1、HDFS 模块
HDFS 数据存储功能,负责大数据的存储,将大文件分块后进行分布式存储,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题。HDFS是个相对独立的模块,可以为YARN提供服务和HBase等其他模块提供服务
运行的节点
NameNode, DataNode, JobTracker, TaskTracker, SecondaryNameNode
节点的区别
从分布式存储的角度,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份
从分布式应用的角度,集群中的结点由一个JobTracker 和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算
JobTracker和NameNode无须在同一台机器上
2、YARN 模块
YARN是通用的资源协同和任务调度框架,为了解决Hadoop1.x中MapReduce里NameNode负载太大和其他问题
YARN是通用框架,可运行MapReduce,还可运行Spark、Storm等其他计算框架
3、MapReduce 模块
MapReduce是并行计算框架,通过Map阶段、Reduce阶段来分布式地流式处理数据。它适用于大数据的离线处理,不适用于实时性要求很高的应用