本文是笔者在研究Disruptor过程中翻译的Disruptor1.0论文精选,中间穿插了一些感想和说明,均以“译注”的形式说明。
论文原地址:https://lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf
Disruptor: 用于并发线程间数据交换的有界队列的高性能替代
- Martin Thompson
- Dave Farley
- Michael Barker
- Patricia Gee
- Andrew Stewart
May-2011
1 摘要
LMAX是为了创造一个极高性能的金融交易所而成立。作为实现这一目标的工作的一部分,我们已经评估了这种系统的几种设计方法,但是随着开始测试,我们遇到了使用传统方法的一些基本限制。
许多应用程序依赖队列在不同的处理阶段之间交换数据。我们的性能测试表明,以这种方式使用队列时的延迟成本与IO操作到磁盘(基于RAID或SSD的磁盘系统)的成本大致处于相同的数量级 - 非常非常慢。如果端对端操作中有多个队列,将为总延迟增加数百微秒。显然有优化的空间。
进一步的调查和对计算机科学的关注使我们认识到,传统方法固有问题的结合(例如队列和处理节点) ,导致了多线程实现中的争用,这表明可能有更好的方法。
考虑现代CPU如何工作,我们喜欢称之为“机械同情”,使用良好的设计实践,强调关注焦点,我们提出了一种我们称之为Disruptor的数据结构和使用模式。
测试表明,使用Disruptor进行三级流水线的平均延迟比基于队列的等效方法低3个数量级。此外,Disruptor在相同配置下处理大约8倍的吞吐量。
这些性能改进代表着围绕并行编程的思考的一个改变。这种新模式是需要高吞吐量和低延迟的任何异步事件处理架构的理想基础。
在LMAX,我们已经建立了一个订单匹配引擎,实时风险管理和一个高可用的内存中事务处理系统,所有这一切都取得了巨大的成功。这些系统中的每一个都制定了新的性能标准,据我们所知,这些标准是无与伦比的。
然而,这并不是一个只有在金融业才有意义的专业解决方案。 Disruptor是一种通用的机制,它能够以最大化性能的方式解决并发编程中的复杂问题,而且实现起来也很简单。尽管有些概念看起来很不寻常,但我们的经验是,建立在这种模式上的系统要比类似的机制要简单得多。
Disruptor显著减少了写时争用,并发开销较低,并且比可当前其他方法更加缓存友好,所有这些都会导致更高的吞吐量,更低的延迟且具有较少的抖动。 在中等时钟速率的处理器上,我们已经看到每秒超过2500万条消息,延迟低于50纳秒。 与我们看到的任何其他实现相比,这种性能是一个明显的改进。 这非常接近现代处理器在内核之间交换数据的理论限制。
(译注:一句话总结,现有的队列结构限制了并发编程的效率,Disruptor用于代替队列实现高效地线程间的数据交换。)
2 概述
Disruptor是我们努力在LMAX建立世界最高性能金融交易所的结果。 早期的设计集中在从SEDA和Actors派生的架构,使用管道(pipelines)提升吞吐量。 在对各种实现进行了分析之后,很明显,在管道之间的各个阶段之间的排队是控制成本的主要因素。我们发现队列也引入了延迟和高水平的抖动。 我们花了大量精力开发具有更好性能的新队列实现。 然而,由于对生产者,消费者和他们的数据存储的设计问题的混淆,作为基本数据结构的队列变得非常有限。 Disruptor是我们的工作成果,用于构建一个能将这些问题划分清楚的并发结构。
3并发的复杂性
在本文档和计算机科学的上下文中,并发不仅意味着两个或多个任务并行发生,而且他们也在争夺资源的访问。竞争资源可能是数据库,文件,套接字甚至内存中的位置。
代码的并发执行大约是两件事,互斥和变化的可见性。互斥是关于管理某些资源的竞争更新。变化的可见性是关于控制何时使这些更改对其他线程可见。如果可以消除对竞争更新的需求,可以避免互斥的需要。如果您的算法能够保证任何给定的资源只被一个线程修改,那么就不需要相互排斥。读和写操作要求所有的更改都对其他线程可见。然而,只有争用的写操作需要相互排斥更改。
任何并发环境中,最昂贵的操作是争用的写访问。要将多个线程写入相同的资源需要复杂且昂贵的协调。通常情况下,这是通过采用某种锁定策略实现的。
3.1 锁的成本
通过操作系统内核的上下文切换实现,会暂停线程去等待锁直到释放。执行这样的上下文切换,会丢失之前保存的数据和指令。
循环5亿次64位计数操作使用时间对比:

3.2 CAS的成本
CAS(Compare And Swap)操作是特殊的机器码指令,允许以原子操作对内存中的字(word)进行有条件地设置。如x86上的"lock cmpxchg"。
对于“递增计数器实验”,每个线程可以循环读取计数器,然后尝试将其原子地设置为其新的递增值。旧的和新的值作为该指令的参数提供。如果在执行操作时,计数器的值与提供的预期值相匹配,计数器将用新值更新。另一方面,如果实际值与预期值不等,CAS操作将失败。然后由线程尝试执行更改以重试,重新读取从该值增加的计数器,依此类推,直到更改成功。
可以不断进行重读、重试,直到操作成功。与锁相比,避免了上下文切换带来的巨大开销。但是并非没有开销。处理器必须锁定指令流水线(instruction pipeline)来保证原子性,并且使用一个内存屏障(memory barrier)使变化对于其他线程可见。
最优算法是:一个线程执行所有写操作,其他线程读取结果。在多处理器环境下读取结果需要内存屏障来保证变化对运行在其他处理器上的线程可见。
3.3 内存屏障
出于性能原因,现代处理器使用乱序的指令执行和乱序的数据载入及存储(内存和执行单元间)。处理器需要保证的只是,程序逻辑结果不受乱序影响。
处理器使用内存屏障来指示内存更新排序很重要的代码段。它们是在线程之间实现硬件排序和改变可见性的手段。 编译器可以添加软件屏障,以确保编译代码的排序,这些软件内存障碍是作为处理器硬件屏障的附加而由处理器使用的。
读内存屏障通过在“内存变化无效队列”做标记,来排序CPU装载指令。写内存屏障通过在用于刷写的存储缓冲中做标记,来排序存储指令。一个完整的内存屏障只在执行它的CPU上排序装载和存储(指令)。
在JAVA中,通过volatile关键字实现读写屏障。由Java5内存模型明确定义。
3.4 缓存行
现代处理器的缓存用法对于成功的高性能操作至关重要。目前来说,处理器在处理缓存中的数据和指令非常高效,相反的,当缓存缺失(cache miss)时则非常低效。
硬件并非以字节或字长为单位处理内存。为了高效率,缓存被组织成大小为32到256字节的缓存行(cache-line),最常用的是64字节。这是高速缓存一致性协议的粒度级别。
上面的意思是:如果有两个变量在相同的缓存行中,且这两个变量是被不同线程写入,这是就会存在写入争用问题,就好像这两个变量是一个变量一样(两个线程虽然操作的是各自的变量,但会导致同一个缓存行失效)。这就是伪共享(false sharding)。从高性能上考虑,重要的是要确保争用最小化,独立但并发写入的变量不会共享相同的高速缓存行。当以可预测的方式访问主存时,CPU可以通过预测将要访问的位置进行预读取来隐藏访问主存的成本。但是如果是遍历链表或树这样的结构时,CPU就不能预测下一步的访问位置了。这将最终导致访问效率下降2个数量级。
3.5 Queue的问题
Queue通常使用链表或数组结构存储元素。使用无界队列通常都需要保证生产者生产速度小于消费者消费速度,否则将会由于耗尽内存导致灾难结果。为了避免这种结果,队列通常是有界的。保持队列有界要么使用数组,要么就是能够主动跟踪大小。
队列实现倾向于对head,tail和size变量进行写入争用。 在使用中,由于消费者和生产者之间的差异,队列通常总是接近满或接近空。 他们很少在平衡的中间地带进行生产和消费的比例均匀匹配。 总是充满或总是空的倾向导致高水平的争用和/或昂贵的缓存一致性。 问题是,即使使用诸如锁或CAS变量的不同并发对象来分离头尾机制,它们通常也占用相同的高速缓存行。
使用一个粗粒度的锁管理整个queue的put和take非常容易实现,但是也很容易成为吞吐量瓶颈。而使用更细粒度的控制就需要更复杂的并发设计。如果将并发问题从queue的语义中剔除,queue的实现无非就是单生产者-单消费者的模式。
在Java中,使用队列还有一个问题-队列是垃圾的重要来源。首先,必须分配对象并将其放置在队列中。 其次,如果支持链表,则必须分配表示列表节点的对象。 当不再引用时,需要重新声明分配给支持队列实现的所有这些对象。
(译注:简单总结,使用队列时,由于消费者生产者之间的差异,导致并发损耗;存在伪共享问题;队列元素是垃圾重要来源。)
3.6 流水线和图表
对于许多类问题,将几个处理阶段组织成(wire together)管道是有意义的。 这样的管道通常具有并行路径,被组织成图形状的拓扑(topologies)。 每个阶段之间的链接通常由队列实现,每个阶段都有自己的线程。
这种方法并不廉价 - 在每个阶段,都必须承担入队和出队的消耗。 当路径必须分叉(fork)时,目标的数量乘以这个成本,并且在这样一个分支之后必须重新加入时会产生不可避免的争用成本(译注:如一个事件既需要被记录日志,也需要被业务逻辑消费)。
如果依赖图的表达不会导致阶段之间放置队列的消耗,将是最理想的。(译注:将不同阶段通过队列组成拓扑图时,避免队列本身的消耗)
4 LMAX Disruptor的设计思想
设计Disruptor就是为了解决以上问题。之所以叫做"Disruptor",是因为在Java7中,用于支持Fork-join的"Phaser"在处理依赖图表时有相似的地方。(译注:Phaser相位枪、Disruptor裂解炮都是星际迷航中的武器,Phaser是联邦武器,Disruptor是克林贡的等价物)
4.1 内存分配
环形缓冲(Ring Buffer)的所有内存都是在启动时预分配的。环形缓冲既可以存储条目(entry)指针的数组,也可以存储代表条目的结构数组。Java语言限制了条目以对象指针的形式与环形缓冲相关联。每个条目都并非数据本身,而是一个容器。条目的预分配消除了支持垃圾回收编程语言的问题,所有的条目在Disruptor实例生存周期中都将重用并一直存在。这些条目的内存同时被分配,将有极大可能在主存中连续分配,这样就支持了缓存位置预测(cache striding,缓存跨越)。这是由John Rose提出的建议,将“值类型”引入到java语言,允许类似C语言中的元组数组那样,来保证内存的连续分配而避免指针间接寻址。
在受管理的运行时环境(如Java)中开发低延迟系统时,垃圾收集可能会有问题。 分配的内存越多,垃圾收集器的负担就越大。 垃圾收集者在对象生命周期非常短暂或有效永生(译注:而非内存泄露引起的永生)的情况下工作在最佳状态。 在环形缓冲区中预先分配条目意味着对于垃圾收集器而言,它是永生的,因此代表着很小的负担。
在重负载队列系统中进行备份,会引起处理速率的下降,导致已分配对象生存的时候更久,将会被垃圾收集器提升到老年代。这意味着两点:一不同代之间的对象复制会造成延迟抖动;二垃圾收集器回收老年代对象代价更大,而且当内存碎片空间需要压缩时,会增加“Stop the world”停顿的可能性。在大内存堆中可能会导致每GB几秒的停顿。
4.2 梳理问题
我们在所有队列实现中总结了以下问题:
a. 被交换元素如何存储
b. 如何协调生产者声明(claiming 取得)下一个用于交换(exchange)的序号
c. 在新元素可用时如何协调要通知的消费者
在使用垃圾回收的语言设计金融交易系统时,内存分配过多可能会造成问题。 所以,正如我们描述的使用支持链表的队列不是一个好办法。 如果可以预先分配用于处理阶段之间的数据交换的整个存储空间,则垃圾收集将被最小化。 此外,如果这种分配可以在统一的块中执行,则将以对现代处理器采用的缓存策略非常友好的方式来完成该数据的遍历。 满足此要求的数据结构是预先填充所有插槽的数组。 在创建环形缓冲区时,Disruptor利用抽象工厂模式预先分配条目。 当声明条目时,生产者可以将其数据复制到预先分配的结构中。
在大多数处理器上,对序列号进行余数计算的成本非常高,这决定了环中的插槽。 通过使环形缓冲器大小为2的平方,可以大大降低该成本。可以使用大小(size)减去1的位掩码来有效地执行求余(remainder)操作。(如size为8,序号为14,则序号1110 & 111 = 110即6)(译注:注意,此处原文应该有误,实际上这里应为求模操作,这部分的源码会在后续讲)
就像先前描述的,有界队列的头部和维护遭受争用。环形缓冲器的数据结构免除了这种争用和并发原语,因为这些问题被转移到了环形缓冲器关联的生产者和消费者的屏障(barrier)中。屏障逻辑如下:
大多数情况下Disruptor只使用一个生产者。通常生产者是文件读取器或网络监听器。当只有一个生产者时,当然没有序号(sequence)和条目分配的争用。
在有多个生产者的不常见情况下,多个生产者将会竞争声明(claim)环形缓冲器中下一个条目。这种(多生产者对同一个条目的)争用可以使用一个简单的CAS操作得到管理。
当生产者将关联数据复制进声明的条目中后,会通过提交这个条目的序号让此条目对消费者可见。这可以不使用CAS而使用一个简单的忙碌旋转(busy spin)直到其他生产者在各自的提交中到达该序号。生产者可以提前一个游标表示下一个可用条目的消费。生产者可以在写入环形缓冲区之前,通过跟踪消费者的序号作为简单的读取操作来避免环绕环。
消费者在读取条目前先等待环形缓冲器中的序列可用。有多种等待策略可供选择。如果CPU资源很宝贵,消费者可以做锁的条件等待生产者发送通知。这种做法会造成争用,只有在CPU资源比延迟或吞吐更重要时才会用。消费者也可以循环检查代表当前可用序列的游标。这样可以使用CPU资源交换更小的延迟,可以选择用或者不用线程退让(thread yield)。如果我们不使用锁和条件变量,我们已经打破了生产者和消费者之间的竞争依赖关系,这样做非常好。无锁的多生产者 - 多消费者队列确实存在,但是它们需要在头部,尾部,大小计数器上进行多个CAS操作。 Disruptor不能忍受这样的CAS争用。
4.3 序列(Sequencing)
序列是Disruptor中管理并发的核心概念。每个生产者和消费者在同环形缓冲器交互时,都采用严格的序列概念。当生产者要求环形中一个条目时,会要求序列中的下一个槽位。下一个可用槽位的序列可以是单生产者时的简单计数器,或者是多生产者时的使用CAS操作的原子计数器。当序列值被声明时,环形缓冲器中的这个条目就可以被那个特定的生产者写入了。当生产者完成更新条目时,它可以通过更新单独的计数器来提交更改,该计数器表示环形缓冲区上的光标,以为消费者提供可用的最新条目。环形缓冲器游标可以被生产者使用内存屏障以忙循环(busy spin)读取和写入,而无须使用以下的CAS操作:
long expectedSequence = claimedSequence – 1;
while (cursor != expectedSequence) {
// busy spin
}
cursor = claimedSequence;
消费者通过使用内存屏障来读取游标等待给定的序列可用。 一旦光标被更新,内存屏障就可以确保在缓冲区中条目的更改对于等待光标前进的消费者是可见的。
每个消费者都包含一个自己的处理环形缓冲器条目的序列。这些消费者序列允许生产者跟踪消费者,防止绕环(译注:prevent the ring from wrapping)。消费者序列还允许消费者以有序的方式在同一条目上协调工作。
在只有一个生产者的情况下,无论消费者图表的复杂程度如何,都不需要锁或CAS操作。 可以通过上述讨论的序列上的内存屏障来实现整个并发协调。
4.4 批量效应(Batching Effect)
当消费者等待环形缓冲器下一个游标序列时,可能会出现一个有趣的不太可能在队列上出现的现象。如果消费者发现环形缓冲区游标自上次检查以来已经前进了多步,则可以(译注:从落后位置)一直处理到该序号位置,而不会涉及并发机制。 这导致滞后的消费者在生产者加速向前时迅速赶上生产者的步伐,从而平衡系统。这种批处理增加了吞吐量,同时减少和平滑了延迟。基于我们的观察结果,这种效应不论负载如何将总是保持常量时间的延迟,直到存储子系统饱和,根据利特尔法则(Little's Law),轮廓是线性的。这与我们在时队列观察到的延迟的“J”曲线效应非常不同。
(译注:代码实现为BatchEventProcessor)
4.5 依赖图(Dependency Graphs)
一个队列代表了生产者和消费者之间仅一步流水线依赖。如果消费者组成了一个依赖的链条或图表结构,那么在图结构每个阶段间都需要队列。在依赖阶段的图中, 这样增加了许多次的队列固定消耗。在设计LMAX金融交易系统时,我们的分析表明,使用基于队列方法的消耗决定了处理交易的总消耗。
因为在Disruptor模式中,生产者和消费者问题是分开的,只在核心的一个环形结构中表示出一个消费者复杂依赖图就成为了可能。这导致执行的固定成本大大降低,从而提升了吞吐量同时减少了延迟。
单一一个环形缓冲器可以用来存储可以表达整个工作流复杂结构的条目。必须注意这种结构的设计,在被独立消费者写入状态时不能导致伪共享问题。
(译注:多任务流水线之间可能有依赖,如ABC为三个任务,A->B->C是基本的流程,在多线程任务中,只有完成A的线程才能执行B,再执行C。)
4.6 Disruptor类设计
Disruptor框架的核心关系类图描述如下。图中省略了一些可以简化编程模型的工具类。生产者通过ProcuderBarrier按顺序要求条目,将变化写入要求的条目,再通过ProcuderBarrier把条目提交回去,让它们可供消费。每个消费者需要做的是提供一个BatchHandler实现,用于接收新条目可用时的回调。这种编程模型很类似Actor模型的事件驱动模型。将通常合并在一起的队列实现问题分离开,将允许更大的设计自由度。一个环形缓冲器是Disruptor模式核心存在,提供了无争用的数据存储交换。并发问题也被分成生产者和消费者同环形缓冲器的交互。ProducerBarrier管理任意在环形缓冲器中声明槽位的并发问题,同时跟踪独立的消费者来阻止环绕环(prevent the ring from wrapping)。当新条目可用时,ConsumerBarrier通知消费者,消费者可以被构造成一个处理流水线的多阶段依赖图。
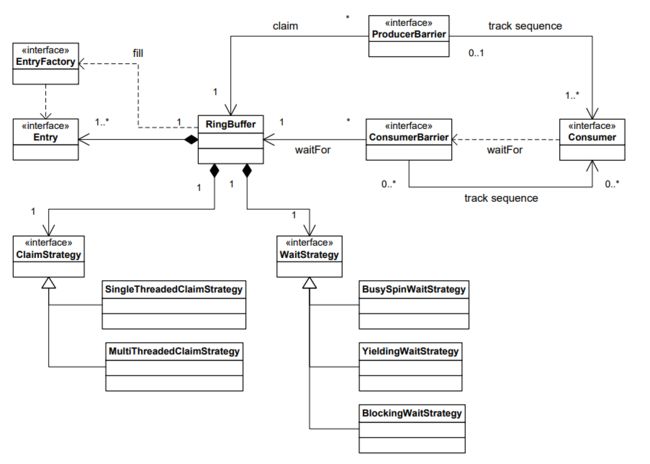
(译注:Disruptor自发布以来已有若干变化。
Entry -> Event
Consumer -> EventProcessor
ProcuderBarrier -> AbstractSequencer
Consumer -> EventProcessor
ConsumerBarrier -> SequenceBarrier)
4.7 代码样例
单生产者和单消费者模式。(译注:由于代码设计发生了较大变化,以下代码只用作理解)
// Callback handler which can be implemented by consumers
final BatchHandler batchHandler = new BatchHandler()
{
public void onAvailable(final ValueEntry entry) throws Exception
{
// process a new entry as it becomes available.
}
public void onEndOfBatch() throws Exception
{
// useful for flushing results to an IO device if necessary.
}
public void onCompletion()
{
// do any necessary clean up before shutdown
}
};
RingBuffer ringBuffer = new RingBuffer(ValueEntry.ENTRY_FACTORY, SIZE, ClaimStrategy.Option.SINGLE_THREADED, WaitStrategy.Option.YIELDING);
ConsumerBarrier consumerBarrier = ringBuffer.createConsumerBarrier();
BatchConsumer batchConsumer = new BatchConsumer(consumerBarrier, batchHandler);
ProducerBarrier producerBarrier = ringBuffer.createProducerBarrier(batchConsumer);
// Each consumer can run on a separate thread
EXECUTOR.submit(batchConsumer);
// Producers claim entries in sequence ValueEntry
entry = producerBarrier.nextEntry();
// copy data into the entry container
// make the entry available to consumers
producerBarrier.commit(entry);
5 吞吐量性能测试
作为参考,我们选择Doug Lea的出色的java.util.concurrent.ArrayBlockingQueue,基于我们的测试它在任何有界队列中具有最高性能。 测试以阻塞编程风格进行,以匹配Disruptor的编程风格。 以下详细的测试案例可在Disruptor开源项目中找到。 注意:运行测试需要能够并行执行至少4个线程的系统。
(译注:方便起见,使用P1代表第一个生产者,P2代表第二个生产者,C1代表第一个消费者,C2代表第二个消费者,以此类推)
单播:1P-1C
P1-> C1
三步流水线:1P-3C
P1 -> C1 -> C2 -> C3
多生产者: 3P-1C
P1,P2,P3 -> C1
多播(多消费者):1P-3C
P1 -> C1, C2, C3
钻石型:1P-3C
P1 -> C1, C2 -> C3
对于上述配置,与Disruptor的屏障配置相比,每个数据流弧应用了ArrayBlockingQueue。 下表显示了使用Java 1.6.0_25 64位Sun JVM,Windows 7,不带超线程的Intel Core i7 860 @ 2.8 GHz和Intel Core i7-2720QM(Ubuntu 11.04)的操作的性能结果,并充分利用3次处理5亿条消息的运行结果。 不同的JVM执行结果可能会有很大差异,下面的数字并不是我们观察到的最高结果。
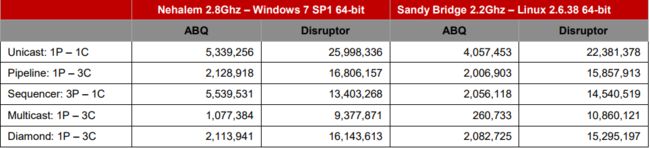
单位:操作/秒
6 延迟性能测试
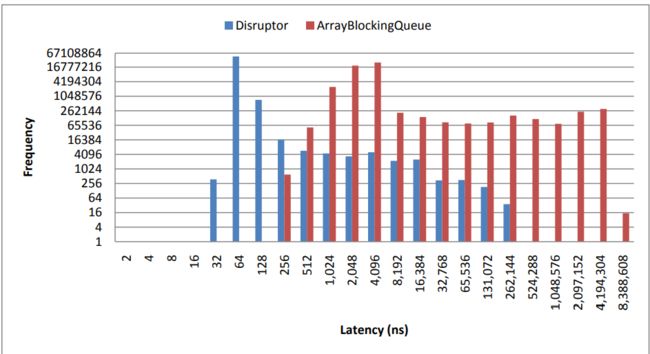
为了测量延迟,我们采用三级流水线,并以小于饱和度的速度生成事件。这是通过在注入事件之前等待1微秒,然后再注入下一个并重复5000万次来实现。要按照这个精度要求,需要使用CPU的时间戳计数器(TSC)。我们选择具有不变的TSC的CPU,因为由于省电和睡眠状态,较旧的处理器遭受频率变化的影响。英特尔Nehalem和更高级的处理器使用一个不变的TSC,可以在Ubuntu 11.04上运行的最新的Oracle JVM访问。该测试没有使用CPU绑定。
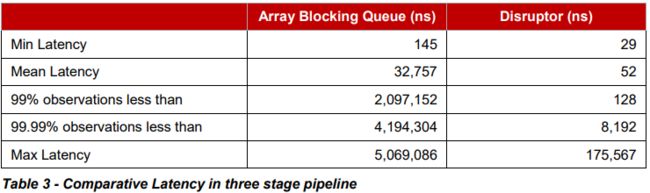
为了比较,我们再次使用ArrayBlockingQueue。我们可以使用ConcurrentLinkedQueue,这可能会给出更好的结果,但是我们希望使用有界队列实现来确保生产者不要超过消费者创造背压。以下结果是2.2Ghz Core i7-2720QM在Ubuntu 11.04上运行Java 1.6.0_25 64位。
Disruptor的平均延迟时间为52纳秒,而ArrayBlockingQueue32,757纳秒。分析显示使用锁和信令通过条件变量是ArrayBlockingQueue的延迟的主要原因。
7 结论
Disruptor是提高吞吐量,减少并发执行上下文之间的延迟并确保可预测延迟的重大进步,这在许多应用程序中是一个重要的考虑因素。我们的测试表明,它比在线程间交换数据的同类方法性能要好。我们认为这是这种数据交换的最高性能机制。通过关注跨线程数据交换中涉及的关注点的清晰分离,通过消除写入争用、最小化读取争用和确保代码与现代处理器使用的缓存工作良好,我们已经创建了一种高效的机制来在任何应用程序之间交换数据。
允许消费者在没有任何争用的情况下处理条目达到给定阈值的批处理效应,在高性能系统中引入了一个新特性。对于大多数系统,当负载和争用增加时,延迟指数增加,即典型的“J”曲线。随着Disruptor上的负载增加,延迟保持几乎平坦,直到内存子系统发生饱和。
我们相信Disruptor建立了高性能计算的新基准,并且非常适合继续利用当前处理器和计算机设计的趋势。
引用:
1 Staged Event Driven Architecture – http://www.eecs.harvard.edu/~mdw/proj/seda/
2 Actor model – http://dspace.mit.edu/handle/1721.1/6952
3 Java Memory Model - http://www.ibm.com/developerworks/library/j-jtp02244/index.html
4 Phasers -
http://gee.cs.oswego.edu/dl/jsr166/dist/jsr166ydocs/jsr166y/Phaser.html
5 Value Types - http://blogs.oracle.com/jrose/entry/tuples_in_the_vm
6 Little’s Law - http://en.wikipedia.org/wiki/Little%27s_law
7 ArrayBlockingQueue - http://download.oracle.com/javase/1.5.0/docs/api/java/util/concurrent/ArrayBlockingQueue.html
8 ConcurrentLinkedQueue -
http://download.oracle.com/javase/1.5.0/docs/api/java/util/concurrent/ConcurrentLinkedQueue.html