几个题目
先看几个题目
1,在给定字符串金额部分加上千分符。
例:
输入:”上季度收入¥2002356987 元”;
输出:”上季度收入¥2,002,356,987 元”;
2,验证IP地址是否合法
例1:
输入:127.0.0.1
输出:true
例2:
输入:300.0.0.1
输出:false
3,取出 a标签的内容
例:
输入:
输出:
百度
淘宝
腾讯
4,用正则替换字日期格式
例:
输入:12-2019
输出:2019-12
5,js css字符串转驼峰css属性
例:
输入:background-color
min-height
输出: backgroundColor
minHeight
若这几个题目你都无压力,那说明你的你的正则已经颇不错了,不用再看下去了。
如果不是的话,那么请从这里看下去,就此掌握一个精悍的技能。
一些没卵用的概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。简单说就是:具有相同规律的字符串的公式 。
一,测试工具
学习正则的第一步应该是找一个趁手的工具,他能帮你检测你写的是否正确。
1 IDE自带工具
所有的编程工具都有正则表达式搜索功能。一般都是按下CRTL+F ,打开搜索功能,有一个带.*的按钮,选中之后表示按正则表达式搜索,然后就可以使用了。

2 在线正则工具
这里推荐一个https://regex101.com/
注意:在线正则工具往往是通过JavaScript实现,所以有一些正则功能他没有,比如前置断言,组命名等等
二,正片开始
说明:本文中为了直观,正则表达式均使用/pattern/表示,实际内容是双斜杠里面的内容:
例如: / hello/
一个简单的匹配过程
首先我们要转换的一个观念:在使用正则表达式时,我们要把一个字符串看成一个又一个的字符,这样对我们理解正则帮助很大。
比如说 有这样一个字符串:
Hello world
我们要把他视作 ‘H’ ,‘e’,’l,’l’,’o’ ,‘ ‘,’w’,’o’,’r’,’l’,’d’ 。至于为什么要这样做,看完下面的例子你就明白了。
当我们 用正则表达式/hello/ ,来匹配Hello world时,他的过程是这样的
|
|
|
|
| 第一步 |
使用表达式的第一个字符和字符串的第一个字符进行比较,匹配成功,h和H匹配成功 |
/hello/
Hello world
|
| 第一步 |
使用表达式的第二个字符和字符串的第二个字符进行比较,匹配成功,e和e匹配成功 |
/hello/
Hello world
|
| 第三步 |
使用表达式的第三个字符和字符串的第三个字符进行比较,匹配成功,l和l匹配成功 |
/hello/
Hello world
|
| 第四步 |
使用表达式的第四个字符和字符串的第四个字符进行比较,匹配成功,l和l匹配成功 |
/hello/
Hello world
|
| 第五步 |
使用表达式的第五个字符和字符串的第五个字符进行比较,匹配成功,o和o,比较成功 |
/hello/
Hello world
|
| 第六步 |
重点来了:上一次匹配结束后,完成了一次完整匹配。下一次将又从正则的开头开始,匹配剩余的字符, 这里会用h和 hello world 中间的空格来比较,h和空格匹配,匹配失败 |
/hello/
Hello world
|
| 第七步 |
依次类推,h一直没能比较成功。一直到结束。 |
/hello/
Hello world
|
总结一下就是:正则表达式是一个字符一个字符来匹配的。这句话虽然并不是特别严谨,但是对帮助我们理解正则很有用。
元字符
正则表达式
正则表达式定义了两种字符,一种叫原义字符,匹配是代表的就是本身含义,比如字母 a,仅仅代表a而没有其他含义。
另一种叫元字符,在正则中代表了特殊的含义,元字符是正则的基础。下面我们开始一一介绍。
字符组 “[ ]”
字符组用方括号[]表示,匹配括号内的一个任意一个字符
字符组表示符合满足括号内表达式的一个字符,这句话的重点是“一个”,

表达式: / [ad]/ 可以匹配字符串 good good study day day up 中的字母 a或者d ,但不能同时匹配ad,虽然/[ad]/ 可以匹配了字符串 ad,但实际上这是两次匹配,一次匹配了a一次匹配了d,总共两次匹配。
字符组的好搭档,连字符 “-”
如果我们希望上面的表达式/[ad]/不仅是匹配a或者d,而是匹配a到z的所有字母。
我们当然可以改写成 /[abcdefghijklmnopqrstuvwxyz]/ ,但这未免太啰嗦,使用连字符“-”可以表示两个字符的区间所有字符
| 元字符 |
说明 |
| [a-z] |
匹配字母a到z |
| [0-9] |
匹配数字字符0到9 |
| [0-9a-z] |
匹配0到9以及a-z |
那如果我随手写了一个[0-z]会匹配什么呢,你会发现他不仅能匹配a-z0-9,还匹配一些其他符号, 等号=,分号;,冒号: 等等…
你是不是发现了什么?没错就是ASCII码,[0-z]匹配字符0到z所有ASCII码中的字符
好搭档的另外一层意思是 只有连字符“-”处于“[]”中时,并且两头都有字符时,他才表示连字符,否则他就是一个普通减号字符“-”:
比如:
/a-z/ 只能匹配a或者减号-或者z
/[a-]/ 只能匹配a或者减号-
排除 “^”
在字符组的开始位置加上^可以表示排除某些字符
例如:[^abcd] 匹配 除abcd四个字母以外的任何字符 [^a-z]代表不在a到z中的一个字母
[^a-z]代表 除a到z以外的一个字符
[^0-9]代表 除0到9以外的一个字符
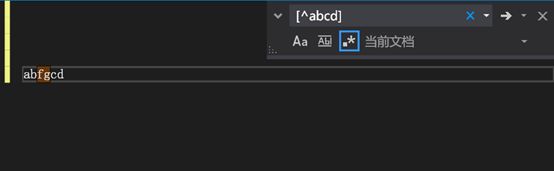
只匹配f或g
排除也有简写
例如:
大写形式 \D 是\d的反义,等同于 [^0-9]
\W 是 \w的反义,代表不在a到z中的一个字母,等同于 [^a-zA-Z0-9]
例: [^abcd] 正确的排除 ,表示a,b,c,d以外的字符。
[a^bcd] 不是正确的排除,表示 'a',或者'^',或者'b',或者'c',或者'd'。
注意:只有“^”出现在字符组'[ ]'里面,并且是第一位时是才是排除的含义,
以上的核心就是匹配单个字符, 其实这也是正则表达式匹配过程的核心:即正则表达式匹配是一个字符一个字符来进行的
缩写
或许是正则的设计者觉得[0-9]或者[0-9a-z]都很啰嗦,又定义更为简洁的元字符
| 元字符 |
|
说明 |
| \d |
等同于[0-9] |
匹配(0到9)的任何一个数字, 英文 digit |
| \w |
等同于[0-9a-zA-Z] |
匹配数字0-9,以及a-z或者大写A-Z任何一个字符 ,英文word |
空格
元字符 \s可以匹配空格,此外空格本身也可以匹配
| \s |
|
匹配空格,空格本身也可以匹配空格 ,英文 space |
匹配位置的元字符
上面几种字符或匹配字符或匹配数字或匹配符号,总之能匹配一个实际的字符,而下面几种元字符匹配的是一个位置而不是任何实际字符。
| 元字符 |
说明 |
| ^ |
匹配每一行开始 |
| $ |
匹配每一行的结束 |
| \b |
匹配单词边界 英文boundary |
开始 “^”
和排除字符 ^ 一样,只不过排除字符只能出现在字符组[]里面,而表示开始的^只能出现在表达式的开始位置
看一个小例子
将 字符串 abc使用 /^/ 替换11,可以看到替换之后变成了11abc,abc本身没有被替换。
我们把开始位置替换为11,可以看到如下结果

替换前

替换后
结束 “$”
$匹配每一行的结尾

替换前

替换后
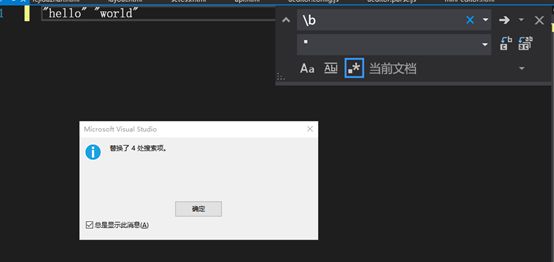
单词边界 \b
\b 匹配单词的边际位置,用下面这个小小例子来理解:
使用引号 “ 替换字符串中的单词边界位置

| 替换前 |
替换后 |
| she's |
"she"'"s" |
| hello world
|
"hello" "world" |
| 中国 top-10 大学
|
"中国" "top"-"10" "大学" |
总结:\b匹配数字或字母或者其他文字(比如汉字)连续字符的两端。
所以使用\b来匹配英文单词是不行的,会漏掉一些有连字符的单词比如 he’s这种
匹配任意字符的“.”
元字符“.”匹配任何字符,包括空格。
转义
当我们想单纯地匹配元字符本身时,就需要转义符来帮助我们完成,正则使用斜杠 “\”加在前面来转义

只有一处匹配,匹配的是d后面的一个位置,并不能匹配 world前面的$

使用转义 \$,匹配到了world前面的$

如果我们想要只是单纯的匹配“.”,就要使用转义,正则使用斜杠 “\”加在前面来转义
量词
了解上面这些元字符,其实我们已经可以做很多事情了,
比如可以用 /[1-9][0-9]/ 匹配所有10~99间的数。
可以用 /[1-9][0-9][0-9]/ 匹配100~999之间的数 。
再往上,比如找到所有大于100 的数。就有点不太好办。
这个时候就需要量词。
量词限定了它前面的一个字符或者组(组的概念后面点会讲到)的出现次数,用 {n,m}来表示, 其中n和m都是数字,n或m可以为空,但不可以同时为空。
| 量词 |
说明 |
|
| {n,m} |
匹配前面的字符最少n次,最多m次 |
|
| * |
匹配前面的字符至少0次或1次,等同于{0,1} |
|
| + |
匹配前面的字符最少1次, ,至多不限,等同于{1,} |
|
| ? |
匹配前面的字符最少n次,最多m次等同于{0, } |
|
来看看这个例子
表达式l{2,5} 匹配2到5次连续出现的l,所以他能匹配前面的hello中的ll,不能匹配world中的l
有了量词我们能匹配的东西更多了
/[1-9]\d{2,}/ 匹配 所有大于1000的数字
贪婪和懒惰?
来看一个例子:
假如我们使用正则表达式 /
会得到怎么样的结果呢?我们可以大胆的猜测以下,按照以往的知识,以下四种都能说的通(黄色为匹配结果),因为他们都满足 /
但是实际上呢?我们对这个表达式进行替换, 发现他实际上替换的是 为什么是这样呢?贪婪和懒惰可以解释以上: 贪婪或懒惰指正则表达式在完成一次匹配后的行为,是使用 量词时 衍生出来的问题。 贪婪:匹配成功后不结束,继续匹配,直到无法成功,才开始下次匹配。 懒惰:匹配成功立刻结束。 马上开始下次匹配。 正则表达式中默认是贪婪的。所以是第二种结果。 懒惰用?表示,他和表示{0,1}的量词一样都是一个问号。只有他出现在+,{n,m}等量词的后面才表示懒惰,否则他是就表示{0,1}的量词 给上面的表达式加上懒惰限定符 / 那么第三种和第四种为什么不匹配呢,因为正则默认是从左到右来匹配的,满足了左边,后续就要按左边的方式匹配。 组用一对括号“(pattern)”表示。 括号里面是一个子表达式,可以用子表达式来完成更多的限定,比如可以用量词限定组内表达式的出现次数 这里是匹配一次 组在正则表达式中是特别常用的,具体用法我们会在后面陆续讲到。 正则默认会给组分配编号,一个正则表达式最多有0-99个组,0组表示正则表达式本身。 反向引用是组衍生出来的一个用法,表示已匹配的已匹配的组的内容。 上面的表达式/(\w{3})-\1/ 。 前半部分(\w{3})-的匹配三个连续的数字和一个横线“-“ 后半部分\1 等同于再加上一个组1的表达式,也就是前面匹配成功了123,那么这里\1就必须是123。\1是前面的组(\w{3}) 的编号。 反向引用最常用的功能就找相同内容。 比如上(\s\b\w{1,}\b)\1可以查找城市字段和工作城市字段相同的用户城市 “|”表示分支符号。 表示分支符前后两侧的组有或的关系,即满足一者即可。 比如我们再注册账户时要输入邮箱,但限定只能使用163邮箱或者qq邮箱,就可以用 /\w{1,}(@163.com|@qq.com)/ 来匹配, 在使用分支时,要注意的是分支的范围,在上面的邮箱正则中分支的范围: /\w{1,}(@163.com|@qq.com)/ 比如我们使用 \b(ti|om)\b 你要匹配叫做tim或者tom的人名单词,发现他们是找不到的 \b(ti|om)\b 标出分支的前后范围我们可以看到, 他只能匹配到ti 或者 om的单词,而午饭匹配tim或者tom。分支的前后范围只限于在一个组内。这是一个易错点,要十分注意。 断言用来描述一段表达式之前或者之后的内容,但又不纳入匹配结果。 名称 表达式 使用 说明 零宽负向先行断言 (?=pattern) /主表达式(?=pattern)/ 主表达式右侧必须是(?=pattern)形式的字符串 零宽负向先行断言 (?!pattern) /主表达式(?!pattern)/ 主表达式右侧必须不是(?!pattern)形式的字符串 零宽正向后行断言 (?<=pattern) / (?<=pattern)主表达式/ 主表达式左侧必须是(? 零宽负向后行断言 (? /(? 主表达式左侧必须不是(? 总结来说就是 ,断言部分括号中的匹配部分不纳入匹配结果 还是从一个例子入手 有这样一段html代码,我们想从中抽取出来a标签的文本内容, 虽然我们可以用表达式 Html/Css(0) 而不是Html/Css(0)这样的,内容并不完美。 这个时候我们就可以用断言来构造一个这样的表达式: 后行断言+主表达式+先行断言 注意:JavaScript不支持前置断言,也就是不能断言左侧出现或没出现什么 1,不同的编程语言对正则的支持程度不同,使用时要看具体语言的支持情况 ,2, 正则有两种类型的引擎:文本导向(text-directed)的引擎和正则导向(regex-directed)的引擎。分别称作DFA和NFA引擎。 1,在给定字符串金额部分加上千分符。 分析:找到可以放千分符的位置,这些位置的特点是右面有3*n个数字,其中n大于等于1,然后再用\b限定这段数字的结尾 很容就写出来 答案:/(?=((\d{3}){1,})\b)/ 2,验证IP地址是否合法 分析:合法的ip地址都是这样的。三个0到255的数字,然后以点号’.’分割 所以完成后的的表达式就是(pattern.){3}pattern 的形式,而这个pattern就是0-255区间 写出0-255区间的表达式 表达式 合并 0-9 \d [1-9]?\d 10-99 [1-9]\d] 100-199 1\d{3} ([1-9]?|1[0-9])\d 200-249 2[0-4]\d (2[0-4]|[1-9]?|1[0-9])\d 250-255 25[0-5] (25[0-5]|2[0-4]|[1-9]?|1[0-9])\d 25[0-5]|2[0-4]\d|1\d{2}|[1-9]?\d ([1-9]?)[0-9] 分析:0开头只能是0, 1开头可以是0-99 2开头可以是0-255 所以综合下就是 ^([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-5][0-5])$ 所以完整的表达式就是 ^(([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-5][0-5]).){3}([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-5][0-5])$ 3,取出 a标签的内容 分析,三段组成:断言+主表达式+断言 答案: /(?<=())\w+(?=)/ 4,用正则替换字符串内容 例如 : 知识点:字符串替换方法 str.replace 的参数1可以是正则表达式,而参数2可以是通过$+组编号直接引用匹配到的内容 5,js css字符串转驼峰css属性 分析 找到“-”和后面的第一个字母,并且替换成大写即可 结束语:学习正则表达式并没有特别的诀窍,唯有手熟而。硬着头皮写上几十个,你会发现也没有什么。 -----------------------------------------------------------------版权申明--------------------------------------------------- 欢迎转载,转载请注明原作者出处。 联系作者 ,心得交流 微信: jimsfriend 

组

组的编号
反向引用(后向引用)


分支

零宽断言

扩展知识点
三,实战开始(片首的答案)

