前言
在microbiome analysis中,有着大量的A,诸如PCA,PCoA,RDA,CCA,ICA之类的,网上介绍每一种的文章都十分的多,但是将它们放在一起比较并且讲得比较明白的文章却比较少,而且其中哪一些区别有一些比较显著性的差异,甚至有一些在了解的人看来比较愚蠢的回答,例如MDS的解释成分是多少之类的?
那么在这里着重和大家一起来介绍一下。先是各个的介绍,然后才是进行比较,以及提及一些重点,在每个的介绍中也会提到这些差异点。
共同点
大部分的A都围绕着一个点,也就是降维。
如何降维?
如何用数学原理保证降维后的信息基本不变?
如何与降维前的数据关联起来?
PCA(Principal Component Analysis)主成分分析
PCA大概是其中最为常见的一种,由于其较为简单的原理以及与降维前的数据关联性比较好,所以应用的范围也是十分的广泛,但是由于其过于简单的假设,也导致了在许多实际应用中的降维效果受到了限制。
拓展:什么是降维?
简单直白的说,就是减少描述性的变量(特征)。例如,你要描述一个物体的形状,你可以用它的长宽高去描述,也就是三个变量(互相之前理所应当的是相互独立的)。但是你也可以用一个正方体去描述,也就是变成了一个变量(丢掉了长度的信息),但是你也已经描述了长宽高相等的一个形状信息。
所以很自然的可以得到一个结论,降维是很有可能会丢失信息的,降维后描述的信息在大多数的时候是少于等于之前的信息的。(等于的情况比较少见,可能只有在一些比较少的特殊的情况中,才有机会。例如之前的例子,由于其实正方体,可能我只需要两个信息,例如长宽高相等,长等于多少,也就是2个描述性变量即可以描述之前3个描述性变量的信息。)
根本原则:使降维后的值尽可能分散(方差最大)。
PCA中降维的手段是通过变换基向量的方法实现的。基向量即n维空间中相互垂直的向量的集合。(二维空间中可以说xy轴为基向量,也可以说y=x和y=-x为基向量。)
假设我们用一个n-1维的基向量去表示一个n维数据,也就是实现了降维了。而这个过程也可以称之为投影(如同三维世界的人,投影到墙上(二维世界)的影子一样)由于N维到N-1维仍然有很多个基向量,不可能保证每个基向量方向的方差都最大(否则都是同一个方向),所以我们需要保证每个基向量的线性独立,这个可以用协方差为0保证。
综上所述,我们就可以用一句话来描述PCA所做的事情。
将N维的数据投影到K维的空间中,K维空间的基向量相互独立,且其中存在降维后方差最大的基向量。
从大的原则上我们已经把PCA讲完,细节上的数学实现,我们这里不加赘述,可以查看一下参考中的文章PCA的数学原理,大体上都是线性代数里的各种矩阵的运算。
最好能够理解数学中的原理,才能够与其他的A进行比较。以下挑出一些比较重要的特点的本质描述(与数学较为密切)。
PCA的特点
- 若原始数据为,行为特征,列为样本。
 原始数据矩阵
原始数据矩阵 -
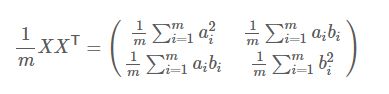 数据矩阵的对角化矩阵
数据矩阵的对角化矩阵 由于上述的特性,可以成功的将一个数据矩阵的方差和协方差相互联系起来。
PCA的特征值:投影后的各维度的方差大小。(肯定都为正)
PCA的特征向量:使原来的数据矩阵进行投影的,一个每一行为一个基向量的变换矩阵。每一行对应一个将原来的特征线性组合的系数,同时也对应一个特征值(方差大小)。
PCA的百分比(解释程度):即用特征值/特征值之和。
PCoA(Principal coordinates analysis)
PCoA也是一个十分有趣的东西,由于其名字与PCA的类似性,导致也有很多人混淆。而且它还有一个别名即,CMDS(Classical multidimensional scaling),注意,不是MDS(MDS分两种,Metric和Non-Metric,PCoA算是Metric里面的一个子类)。这里简单的介绍一下,希望不再混淆。
在CMDS中,大多数时候使用欧几里得距离,并且由于欧几里得距离进行推导出下列过程。
根本原则:接收样本与样本间得到距离矩阵,在保证欧几里得距离变化最小的情况下投影到N-1维的空间中。
-
对原始的距离矩阵进行双中心化(double centering),一方面假设投影后的矩阵的样本之间的欧几里得距离,是一个中心化的矩阵,用这样的一个中心化操作来保证与原始的距离保持差异最小(此处损失函数的的定义)。由于投影后的坐标矩阵的几何距离矩阵为中心化了,所以会有。即
代入投影后每一行的和为0的限制条件,从而经过一系列推导,详情可见参考3,从而将一个假设为欧几里得距离的原始距离矩阵与B关联起来。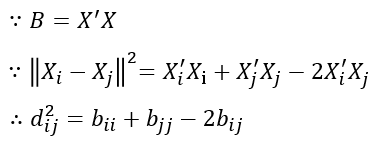

- 得到投影后矩阵的对角化矩阵B,接下来就是算特征值和特征向量了。

PCoA的特点
- 一般使用的为欧几里得距离,但你也可以输入别的距离矩阵。但中心化过程是适用于欧几里得距离的,所以可能使得特征值出现负数。
- 特征值:为B中的对角线上的值
- 特征向量:为Q’矩阵中的每一行
- Q向量中的特征向量则为构成投影后新的空间的基向量。
- PCoA的解释程度(百分比):同样的由特征值/特征值之和。(贡献的解释,理解为在该轴上数据的分散程度)(如果出现负数特征值,其特征值之和需要转化为所有特征值绝对值之和。)
- 特征值,需要注意的是,其与PCA的意义不大相同。假设的前提中是距离矩阵为欧几里得距离,但是大部分情况下并不是。但由于CMDS使用的就是欧几里得距离的假设从而得到的推导(B与D的关系),所以在特征值分解B的过程中,可能会由于D本身的问题,得到一系列的负数的特征值。
- 当应用非欧氏矩阵或者更一般的非相似性矩阵(dissimilarity matrix)时,特征值向量eigvals中会出现负值。需要注意的是,当eigen vals中负值较大的情况下计算出来的低维几何表示就没有意义了。
- 对于应用面更广的Metric multidimensional scaling,是需要指定投影后空间的维度的,通过权衡计算后的Strees(损失函数),2.5%为非常好,需要增加投影后空间的维度重新进行优化计算,直到得到更满意的Strees值。
A principal coordinate analysis of the distance matrices produced by these coefficients may generate negative eigenvalues; these eigenvalues indicate the non-Euclidean nature of the distance matrix (Gower 1982). They measure the amount of variance that needs to be added to the distance matrix to obtain a full Euclidean representation
--from Ordination written by Lengendre & Birks 2012
Metric MDS
大致上和PCoA的一个原则是一样的,但是由于是应用于非欧式距离矩阵的,所以不满足Classical MDS中的假设,所以只能通过解决一个最优化问题去求解。

即通过求解一个叫Strees的偏离度来求解投影后的点的坐标。
一般来说,Metric MDS会要求使用者输入降维后所需要的维度,例如sklearn中的MDS。
为了最优化这个Stress要比较多而且繁复的高数内容,这里不加讲解。有兴趣的可以看
MDS的数值优化方法
CA(Correspondence analysis)对应分析
也叫RA(reciprocal averaging)由于CA、PCA、PCoA都属于利用eigenvalues的ordination方法,所以也就放在一起讲,像MDS的另外一种NMDS,也就放在后面再来加以描述。
CA是一种类似于PCA的方法,但是其更多的用于类型变量的数据而不是连续变量的数据,本质上是为了从整体上探索两组变量之间的关系。即在两组变量中,寻找若干个具有代表性的变量的线性组合,用这些线性组合的相关关系来表示两组变量间的相关关系。
直白的说,就是将行的编号以及列的编号在一个二维坐标轴中做出相应的点,可以看到行编号以及列编号对应的距离关系来看行之间,列之间,行与列之间的关系,距离越近,关系越密切,同时根据特征值,来判断某个点对整个数据的贡献情况。
基本步骤:
- 随机一个样本的排序值(只要有大小关系的一系列值)
- 对每个特征的每个样本进行加权平均,得到一个各特征的排序值
- 再用各特征的排序值,对每个样本进行加权平均值求样本的排序值
- 对样本的排序值进行标准化
- 回到第二步重复进行迭代,直到结果变化很小
- 求第二个投影轴,方法差不多,仅仅需要保证与第一个投影轴正交
其中各样本的排序值即在投影上的坐标,各特征也有一个排序值,所以在投影上也有坐标。
缺点:
就是CA/RA的第二排序轴在许多情况下是第一轴的二次变形,即所谓的“弓形效应”(Arch effect)或者“马蹄形效应”(horse—shoe effect)
DCA(Detrended Correspondence Analysis)
由于是为了去除CA第二轴产生的弓形效应的影响,所以其大体和CA是一致的。
仅仅在求第二轴的坐标值时,采用一个将第一轴分成一系列区间,在每个区间内将平均数定为零,从而消除了弓形效应。
弓形效应如下图的X的点的形状。
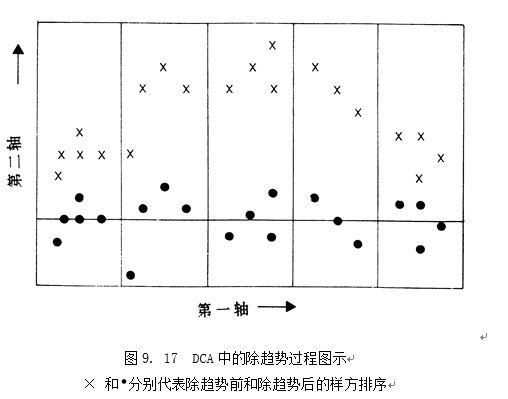
即在求第二轴时,不需要进行正交化,取而代之的是除趋势。即将第一轴分成数个区间,在每一区间内对第二轴的排序值分别进行中心化。用经过除趋势处理的样本的排序值,再进行加权平均求新的特征排序值。后跟第一轴的求法一样,不断的迭代。
CCA (canonical correspondence analusis)典范对应分析
Canonical也是一个十分常见的修饰词,也存在CPCA,CCA。其中CPCA即PCA与多元回归的一个结合,即在PCA分析中的每一步都与环境变量进行多元回归,再将回归得到的系数结合到下一步的计算中。(这句话也是十分奇怪。。。但是由于CPCA的内容十分少,无法考证。)
而CCA则是把CA/RA和多元回归结合起来,每一步计算结果都与环境因子进行回归。即在每次得到样本的排序值时,将其余样本对应的解释变量的表格进行多元线性回归。
基本步骤为:
- 随机一个样本的排序值(只要有大小关系的一系列值)
- 对每个特征的每个样本进行加权平均,得到一个各特征的排序值
- 再用各特征的排序值,对每个样本进行加权平均值求样本的排序值(以上等同于CA)
- 用排序值作为Y去进行多元线性回归,得到一个回归系数。
- 用回归后的系数和方程求得新的样本的排序值
- 对样本的排序值进行标准化
- 回到第二步,重复以上过程,直至得到稳定值为止
得到的图大概就是类似于CA的结果。
类似于envfit(vegan)
RDA (Redundancy Analysis)
RDA在现在的生信分析中也不是十分的多见。也许是由于其可以算的上是一种特别的PCA(constrained Version),所以其原理上也十分的类似。这里也简单的介绍一下。
RDA主要做的事情是在响应变量中提取出一些能被解释变量解释的变量,(can be explained == linear relationships with)
RDA之所以被认为是constrained version of PCA,是因为投影的坐标轴,一方面是由响应变量线性组合而成,但又必须是解释变量的线性组合(通过多重线性回归来拟合)。
RDA的基本步骤
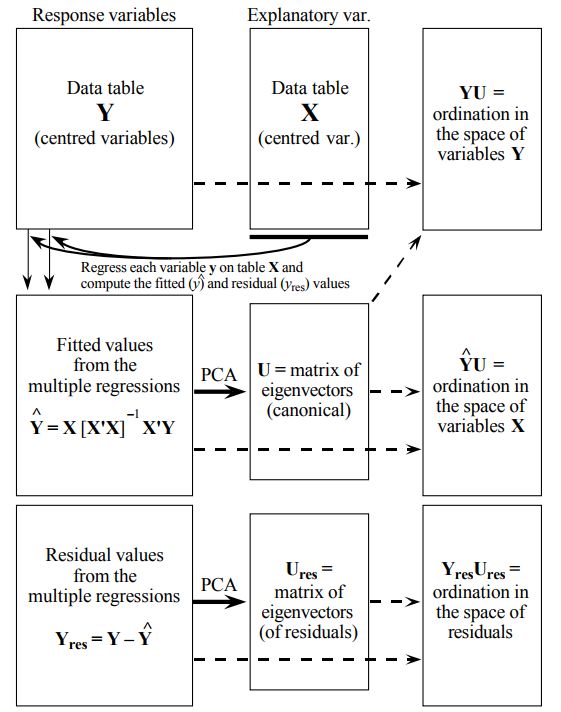
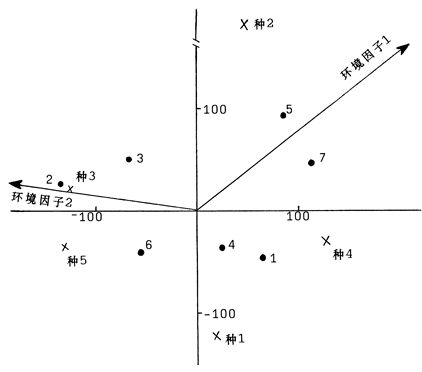
由于RDA的原理讲解也是比较少,那么直接从结果解读来揭示更多的信息。
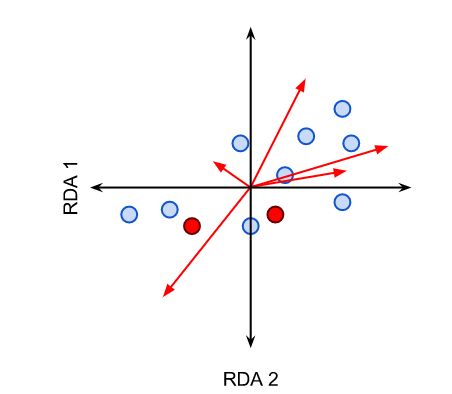
以上的图就是一个典型的RDA的结果,其中红色的箭头是解释变量(例如说PH、BMI之类的)的一个特征,其长度表示该特征与样本分布间相关程度的大小,连线越长,相关性越大,反之越小。箭头连线和排序轴的夹角以及箭头连线之间的夹角表示相关性,锐角表示成正相关关系。蓝色的点为原始数据降维后的投影(这个投影与PCA的结果是相近的)。
特点与注意事项
RDA 或者CCA是基于对应分析发展而来的一种排序方法,将对应分析与多元回归分析相结合,每一步计算均与环境因子进行回归,又称多元直接梯度分析(Multivariate direct gradient analysis )。此分析是主要用来反映菌群与环境因子之间关系。RDA是基于线性模型,CCA 是基于单峰模型。
RDA 或CCA 模型的选择原则:先用species-sample 数据(97%相似性的样品OTU 表)做DCA 分析,看分析结果中Lengths of gradient 的第一轴的大小,如果大于4.0,就应该选CCA,如果3.0-4.0 之间,选RDA 和CCA均可,如果小于3.0,RDA 的结果要好于CCA。参考自:非文献,慎用。
NMDS(Non-metric multidimensional scaling)
对于metric MDS而言,一般是使cost function最小化,也就是叫Stress的(residual sum of squares)。简单地说就是距离矩阵的距离减去投影后的欧式距离的平方和的开平方。但是对于很多的距离矩阵来说,你使用一个欧氏距离的公式(即使是应用在投影后的距离上),是十分难以衡量原来距离矩阵的差异的。
而非度量的MDS就是使用了一个不一样的Stress,先对距离矩阵进行一个变换(这个变换多种多样),然后再与投影后的欧氏距离进行差值的平方和再开平方。这个变换仅仅保持距离矩阵中的大小关系,而忽略其数值大小的差异,即为单调函数。所以在不同的尺度上会有不同的大小。
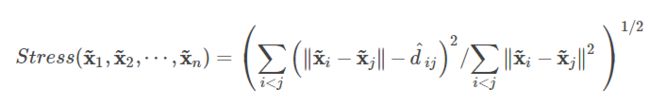
基本的步骤为
- 随机找一堆点的,例如通过在正态分布上进行采样。
- 计算点之间的几何距离
- 根据计算原先距离矩阵中的大小关系。对新的点点之间的几何距离进行一个保序回归(isotonic regression)得到新的距离矩阵
- 将新的的距离矩阵,代入Stress公式,通过优化计算,得到更新的投影后的点的坐标
- 若Stress小于阈值,则停止迭代。
DbRDA(distance-based Redundancy Analysis)
属于RDA的拓展,也就是当响应变量属于距离矩阵的时候,那么就应该先用PCoA的来进行一次投影,从而得到一个新的坐标数据。后面的过程即将这个坐标数据当做RDA中接受的响应变量,进行一次RDA的分析,得到一个新的坐标轴以及箭头之类的。
结语
其实讲到上面那里应该就已经把大部分的A都讲完了,当然还有一些拓展的例如dbRDA、ICA、DCA这些其实都还算是上面的一部分,但如果硬要这么说的话,其实上述的A们都应该用一个共同的名字去描述,即Ordination analysis,中文大概叫排序分析(我个人是不喜欢这个名字的...)。所以一般用Ordination称呼就好。
而且还有一些A是不属于Ordination,例如LDA,属于机器学习的范畴。剩下的那些也就不加赘述。
大致就这样的。
至于上面各种A之间的比较用图进行阐释。

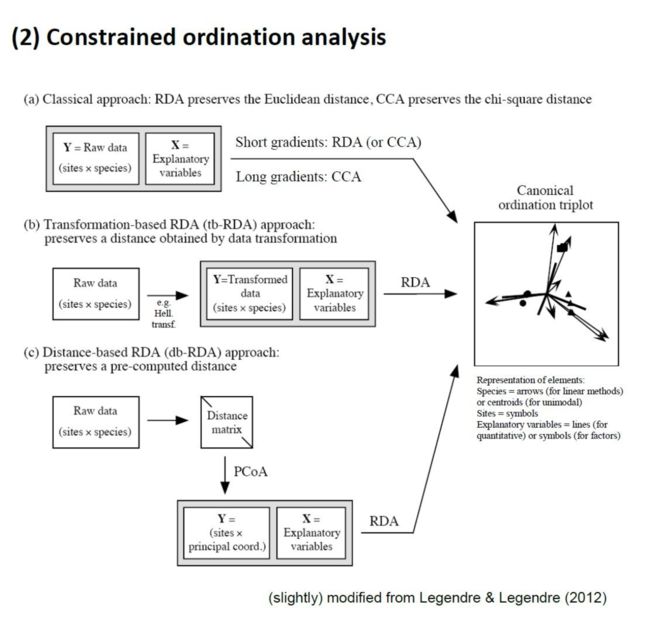
其中MDS与环境因子的关联同样的可以用多元线性回归进行解决(虽然也是感觉十分的奇怪,仅仅为了通过投影后的坐标关联出的环境因子的结果。)R包:Vegan:envfit。
参考
PCA的数学原理
Multidimensional scaling
http://www.stat.pitt.edu/sungkyu/course/2221Fall13/lec8_mds_combined.pdf
https://stats.stackexchange.com/questions/68680/how-to-interpret-variation-explained-by-principal-coordinates
MDS的数值优化方法
RDA
GUide to STatistical Analysis in Microbial Ecology (GUSTA ME)
CCA