
开篇
Elasticsearch以下简称ES,接下来ES将从几个方面进行解释:
1.ES是什么?
2.应用场景
3.ES的生态
4.ES的一些特性
5.ES的一些好用插件
6.ES在PHP Laravel的中实战
7.ES在Spark中的实战
8.ES调优
9.致谢参考链接
1.ES是什么?
ES是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
这段话就是对ES的一个描述,简单概括:
“高性能全文搜索引擎,RESTful API接口调用”
ES的内部设计非常优雅,一切的一切统统都是接口调用,针对ES的开发维护会比较轻松,一般到后续我们都会针对ES进行定制开发,好比ES当成一个数据库,通过它定制的查询语法进行交互来完成我们的数据分析需求。
2.ES应用场景
对于刚刚接触ES的人应该比较陌生,我们来直接对ES使用做一个定位
那么我们来列举一下ELK这套使用的应用场景:
1.监听网站Nginx的日志时时同步到ES,通过Kibana来分型日志是否存在问题,服务器层面的监控。
2.监听Mysql日志,对日志进行监控检测,对于业务来说可以进行一些辅助分析。
3.用户行为数据埋点收集,提供大数据分析数据支持。
4.使用ES来构建网站的全文检索引擎。
这是一些常见的使用场景,还可以继续补充。
3.ES的生态
我们在进行ES开发的时候一般会选用一整套ES的技术栈ELK(Elasticsearch+Logstash+Kibana)
我们大部分情况会接入Flume,Kafka来做数据的消息中间件来作为Logstash的数据源。
我们还可能使用PHP,Spark,Scala等来分析ES中的数据提供个性化服务。
我们还可能使用Firebeat来替换Logstash。
其中ES是可以支持集群横向拓展来完成对性能的要求,后续会讲到关于ES的调优。
ELK是同一家公司提供的打包的一组服务,其中
E:就是这个全文检索引擎了
L:一个日志收集服务,可以把你的log,kafka等其中的数据收集并输出到ES中
K:一个可视化图表工具, 通过接入ES提供直接的页面来完成数据的分析查询使用
“我们可以通过L来监听一些文件的改动,然后把数据从文件灌入ES,最后通过K来可视化查看。”
这是一种比较简单直接的使用方式。
我们经常会使用一种架构:
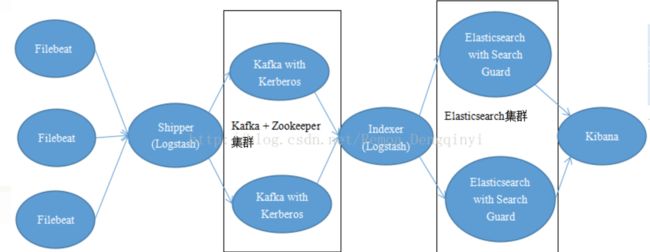
这里面Filebeat是比较轻量级的日志收集工具,和Logstash配合可以提升吞吐量。
好了,到这里介绍完了我们常用的生态组件。
4.ES的一些特性
在使用之前我们还是要先从ES的一些特性进行了解,
首先:ES有索引,分片,文档等基础概念,我们必须先了解这些。
文档(Docs)
存储的一条记录
索引 (Index)
我们可以先暂时吧索引比作MySQL中的数据库的概念。这样会比较好理解。
分片(Shard)
分片是组成索引的单元,我们创建索引的时候可以指定分片的信息,默认创建一个
索引的时候会创建5个主分片,同时每个主分片对应一个副本分片。
这里的对应关系应该是 索引->分片 是 1:N的关系。
同时一般一个分片的最大存储空间是有限制的,50GB大小通常是一个上限。其实主要原因是
每个分片都是一个Lucene Index,一个分片只能存放Integer.MAX_VALUE-128个文档2,147,483,519 个docs,所以一个分片能存多少数据也要基于单个文档的内容而定。
在ES集群的环境下,副本分片会分散在不同的节点,来实现高可用,提升查询性能。
分片数量会影响什么?
ES的查询如果分片数量太多,就需要每个分片都查询一次,然后聚合结果,一般建议根据数据量大小来
设定索引和分片数,后续关于ES调优中分片的配置比较重要,不过也不必太担心,不管索引和分片设置的
如何我们都是可以通过API进行reindex等操作来完成调整。
5.ES的一些好用插件
elasticsearch-sql 把sql语句转换成DSL查询语法,或者直接通过sql进行查询ES。
ES-HEAD ES集群信息监控等(chrome插件)
X-PACK 官方查询,提供权限管控,性能跟踪等。
6.ES在PHP Laravel中的实战
其实上面介绍了那么多,很多时候大家在搭建好一整套ELK的时候直接访问K的服务就能可视化的进行交互了,但是如果有一天,你想通过代码来拉取数据并且执行一定的逻辑功能,那么你可能就需要进行开发了。
那我们先使用PHP来对接ES吧。
为了方便使用Laravel来做一个ES的接入
先引入一些依赖包在composer.json中添加
"ruflin/elastica": "dev-master"
引入了包之后我们先初始化一个Client
$this->es = new \Elastica\Client([ 'host' => 'x.x.x.x', 'port' => 9200 ]);
#ES默认端口9200
拿到了ES对象,构建一个基于DSL语法的数组或JSON
$query = [ "query" => [ "bool" => [ "must" => ["match" => ["@fields.ctxt_event" => "打开"]], "must_not" => ["match" => ["@fields.ctxt_event" => "more"]], ], ], "aggs" => [ "toptap" => [ "terms" => [ "field" => "@fields.ctxt_event", "order" => ["_count" => "desc"], "size" => 50 ] ], ]];
#接口中index是索引名称,doc是文档的type
$response = $this->es->request( 'index/doc/_search', Request::GET, $query);
此时就是完成一次接口调用,关于DSL的语法需要进行另外的学习。
当然这一步中是有问题的,因为这是由于聚合查询中fielddata是在ES5.x默认关闭的,需要手动指定开启。
(因为我们的语句中含有“aggs”参数表示要聚合结果)
开启需要的字段方式:“@fields.ctxt_event“为我们需要聚合字段
$enable = [ "properties" => [ “@fields.ctxt_event”=> [ "type" => "text", "fielddata" => true, "norms" => false ] ]];
$this->es->request("index/_mapping/doc", Request::PUT, $enable);
#index 表示索引名,支持通配符,逗号分隔比如(logstash2018.*或者logstash2018.01,logstash2018.02)
#doc是记录的类型对应_type字段的值,一般默认是doc
至此完成一次基础的查询,关于DSL语法的一些问题请读者根据实际的文档内容进行调整。
那么我们是否可以通过更加简单的方式?
我们可以安装elasticsearch-sql插件,之后我们可以调整查询方式为
$sql = "SELECT * FROM indexname WHERE @fields.ctxt_event ='分享作品' OR @fields.ctxt_event ='下载作品' OR @fields.ctxt_event ='收藏点击' OR @fields.ctxt_event ='分享点击' OR @fields.ctxt_event ='下载点击')";
$url = 'http://' . $this->host . ':' . $this->port . "/_sql";
$ret = $http_client->post($url,[
'body' => $sql
])
这里的http_client只要能发起post请求的网络对象即可。
此时的调用方式就不在需要使用DSL语法,而是转变成sql查询。
当然前提是需要预先安装好插件。
7.ES在Spark中的实战
本段内容是在Spark中如何对接ES的数据
项目基于sbt构建平台,scala语言。
首先我们需要在sbt配置中引入必须的依赖包
libraryDependencies += "org.apache.hadoop" % "hadoop-client" % "2.7.5"libraryDependencies += "org.apache.hadoop" % "hadoop-hdfs" % "2.7.5"
libraryDependencies += "org.apache.hadoop" % "hadoop-common" % "2.7.5"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "2.2.1"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.2.1"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.2.1"
libraryDependencies += "org.elasticsearch" % "elasticsearch-hadoop" % "6.1.1"
根据各自需求可能还需要引入其他的包,但是这几个包是必须引入的。
之后我们开始构建Spark
val config = PropertiesUtils.fetchProperties("es.properties")
val host = config.getProperty("es.host")
val port = config.getProperty("es.port")// 生成spark session对象
val spark = SparkSession .builder() .appName("es") .master("local[4]") //本地调试打开 .config("es.index.auto.create", "true") .config("pushdown", "true").config("es.nodes", host) .config("es.port", port) .config("es.nodes.wan.only", "true") .config("es.read.field.as.array.include", "tags") .getOrCreate()
val df = spark.sqlContext.read.format("org.elasticsearch.spark.sql").load("index")
df.show(false)
这其中包含了从创建Spark Session,然后从ES中load需要的index给dataframe。
至此我们已经完全拿到了ES的数据,关于后续的增删改查另外补充。
8.ES调优
目前根据使用情况大概介绍一下。
分片优化
首先看数据每天的增量来确定索引的数量,比如我预估每天的数据增量是1GB,那么我一个索引如果设置成5个分片,基本上这个索引可以支撑我接近250天的数据。单节点中的分片数量和节点数的关系官方推荐是一个节点不要超过三个分片。
副本分片
主分片的备份,在分布式查询中可以提升性能
集群高可用,高性能
ES提供了自动的感知节点,同时会通过自动将所有主副分片进行分配转移。

如果是有三个p0,p1,p2主节点,r0,r1,r2三个副节点的自动分布,支持自动扩容和缩容。
由于每个分片都是独立的搜索引擎单元,因此水平扩容的时候每个分片同样也能获取更多的硬件资源。
如果我们将每个主节点增加更多的副本节点,在节点数够多的情况下能更加提升查询性能!
内存调优
根据服务器内存调整ES最大堆内存,不要超过服务器内存60%,最大不要超过32G。
索引优化
增加文件描述符
9.致谢参考链接
ELK + Kafka + Filebeat架构 :https://blog.csdn.net/remoa_dengqinyi/article/details/77902391