上一篇讲了webflux的简单使用,但如果深入点想就会有很多疑问。webflux是如何同netty协作的?响应式的线程是如何调度的?一个请求是怎么来到我们定义的RequestMapping方法的?本篇通过对webflux源码的阅读,简要分析这几点。
spring webflux基于reactor,默认的容器为netty,所以想学习spring webflux的源码,必须要有这两个技术的知识。这里先简要介绍一下。
Netty
Netty是一个高性能、异步事件驱动的NIO框架,提供了对TCP、UDP和文件传输的支持,作为一个异步NIO框架,Netty的所有IO操作都是异步非阻塞的。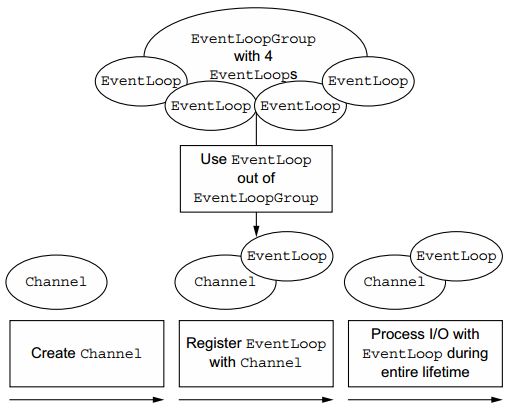
上图是netty的基本工作流程,简单来说:
· 一个EventLoopGroup包含一个或多个EventLoop。
· 一个EventLoop在生命中周期绑定到一个Thread上。
· EventLoop使用其对应的Thread处理IO事件。
· 一个Channel使用EventLoop进行注册。
· 一个EventLoop可被分配至一个或多个Channel。
EventLoop除了要负责处理绑定的Channel所有io操作,由于其继承了Executor接口,还可以执行提交的任务。需要注意的是,提交给EventLoop的任务必须是非阻塞的,否则将使io处理没有资源,导致整个应用吞吐量下降。
netty处理数据流程如下:

数据从客户端传入服务端称为出站,反之称为入站。一个socket链接为一个channel,一个channel有一个channelpipeline,pipeline是入站处理器和出站处理器的链式集合。当一个请求msg从某个channel入站时,将从该channel绑定的pipeline的head开始,经过一个个ChannelInboundHandler入站处理器的处理。反之,当一个响应msg从channel出站时,将从该channel绑定的pipeline的tail开始,经过一个个ChannelOutboundHandler入站处理器的处理。
当某个ChannelHandler被添加到ChannelPipeline中时,会为其创建一个ChannelHandlerContext,ChannelHandler可以访问其绑定的ChannelHandlerContext,从而和pipeline交互。有点类似拦截器链,ChannelHandler通过ChannelHandlerContext将数据交给pipe中的下一个处理器处理。
Reactor
Reactor的核心是Mono和Flux两个类,他们都继承了Publisher接口,代表一个数据流的发布者。其中,一个Flux代表一个0~N个元素的序列发射源,而Mono代表只有0或1个元素的发射源。可以通过subscribe()方法订阅发射源,类似java中的stream操作,在执行subscribe()之前,Mono和Flux并不会开始发射数据。
Mono和Flux提供了丰富的api可以进行链式调用,并且可以通过subscribeOn()或者publishOn()指定Mono中某一步操作的执行线程。如果不指定Mono或Flux的执行线程,那么默认会在调用subscribe()的线程上运行,这一点也和Stream相似。
public Mono say(String name) {
return Mono.just(name)
.publishOn(Schedulers.elastic())
.map(Try.of(this::hello));
}
private String hello(String name) throws InterruptedException {
Thread.sleep(10000);
String result = String.format("hello %s, current-thread is [%s]", name, Thread.currentThread().getName());
System.out.println(result);
return result;
}
上述代码将打印:
main thread
hello nihao, current-thread is [elastic-2]
但如果将
.publishOn(Schedulers.elastic())注释那么结果是:
hello nihao, current-thread is [main]
main thread
从这里可以看出Reactor的优点,她极大的简化了异步编程中线程切换处理的难度。
Spring Webflux
回到Webflux,他是如何工作的?可以从@EnableWebFlux注解开始看,这里略去复杂的过程直接说结果。首先,WebFlux的核心仍然和MVC一样是Dispatcher,另外简单来说,可以将整个过程描述为两步:
一、向Netty注册ChannelHandler
二、Netty调用ChannelHandler
先说向Netty注册ChannelHandler。
- 容器启动,@EnableWebFlux注解引入的DelegatingWebFluxConfiguration配置类向容器注册基础bean,包括DispatcherHandler、WebFluxResponseStatusExceptionHandler、RequestMappingHandlerMapping等。
- 向WebHttpHandlerBuilder传入ApplicationContext,WebHttpHandlerBuilder利用context获得WebHandler(Dispatcher)、List
、List 等bean,并构造HttpHandler(HttpWebHandlerAdapter)。HttpHandler接口的方法:Mono handle(ServerHttpRequest request, ServerHttpResponse response)。很明显,她是Webflux功能的集合和对外接口。 - 由于使用Netty,使用ReactorHttpHandlerAdapter是包装HttpHandler,ReactorHttpHandlerAdapter作为WebFlux上层到底层容器Netty的桥梁,类似的还有ServletHttpHandlerAdapter,链接Servlet容器。
- 使用httpServer.newHandler(adapter)注册ReactorHttpHandlerAdapter。 httpServer下一层是tcpServer,tcpServer将ReactorHttpHandlerAdapter包装包装成ContextHandler,ContextHandler实现了ChannelInitializer接口,可以用来向Netty注册ChannelHandler
@Override
public final Mono newHandler(BiFunction> handler) {
Objects.requireNonNull(handler, "handler");
return Mono.create(sink -> {
ServerBootstrap b = options.get();
SocketAddress local = options.getAddress();
b.localAddress(local);
ContextHandler contextHandler = doHandler(handler, sink);
b.childHandler(contextHandler);
if(log.isDebugEnabled()){
b.handler(loggingHandler());
}
contextHandler.setFuture(b.bind());
});
}
- ContextHandler在initChannel()->accept()方法中向pipeline中注册了ChannelOperationsHandler,ChannelOperationsHandler实现了Netty的ChannelDuplexHandler接口,可以通过ChannelHandlerContext处理入站和出站数据。
channel.pipeline()
.addLast(NettyPipeline.ReactiveBridge,
new ChannelOperationsHandler(this));
- ChannelOperationsHandler通过channelActive()在channel每次激活时调用了ContextHandler的createOperations()方法创建ChannelOperations。这一步很关键,首先通过channelActive()说明ChannelOperations是与一次请求对应的。另外看createOperations()的代码,有两处:
ChannelOperations op =
channelOpFactory.create((CHANNEL) channel, this, msg);
channel.eventLoop().execute(op::onHandlerStart);
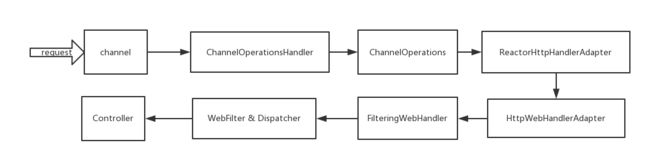
这说明了Spring Webflux处理一次请求的方式:
- 一个request到Netty时,Netty传递给ChannelOperationsHandler
- ChannelOperationsHandler将数据和对数据的操作封装成ChannelOperations
- 将ChannelOperations作为一个任务提交给Netty的eventLoop
- eventLoop在对一个channel的pipeline调用完成后,将执行提交的任务,此时将进入处理Spring WebFlux的操作。
来看看ChannelOperations做了什么,首先明确几点:ChannelOperations中封装了this(ContextHandler),而ContextHandler中封装了ReactorHttpHandlerAdapter,ReactorHttpHandlerAdapter中则封装了HttpHandler,HttpHandler中则是核心组件WebHandler(Dispatcher)、List
protected final void applyHandler() {
// channel.pipeline()
// .fireUserEventTriggered(NettyPipeline.handlerStartedEvent());
if (log.isDebugEnabled()) {
log.debug("[{}] {} handler is being applied: {}", formatName(), channel
(), handler);
}
try {
Mono.fromDirect(handler.apply((INBOUND) this, (OUTBOUND) this))
.subscribe(this);
}
catch (Throwable t) {
log.error("", t);
channel.close();
}
}
关键点又来了,提交给eventLoop 的任务做了什么:
Mono.fromDirect(handler.apply((INBOUND) this, (OUTBOUND) this))
.subscribe(this);
从中我们可以得到使用Spring WebFlux的核心法则:
绝对不要阻塞Controller的方法。
因为这将导致eventLoop线程的阻塞,而eventLoop线程数量一般只有cpu核心数*2个,如果阻塞了eventLoop线程将导致真个服务不可用。
下面做个小实验
package com.xinan.demo.rest;
import com.xinan.demo.util.Try;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Mono;
import reactor.core.scheduler.Schedulers;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author xinan
* @date 2018/8/3
*/
@RestController
@RequestMapping("hello")
@Slf4j
public class HelloController {
@GetMapping
public Mono say(String name) {
return Mono.just(name)
.map(Try.of(this::hello));
}
private String hello(String name) throws InterruptedException {
Thread.sleep(10000);
String result = String.format("hello %s, current-thread is [%s]", name, Thread.currentThread().getName());
System.out.println(result);
return result;
}
@GetMapping("nob")
public Mono nob() {
return Mono.just(Thread.currentThread().getName());
}
}
通过webbench say()同时发送20个请求(大于eventLoop线程数)
webbench -c 20 -t 30 http://localhost:8080/hello/say
再立即通过浏览器访问 http://localhost:8080/hello/nob,可以看到http://localhost:8080/hello/nob接口直到10秒之后才返回结果。这就是阻塞了eventLoop线程的结果,耗尽了线程资源,导致服务不可用。
本文简要分析了Spring WebFlux的主要工作流程,可以看到WebFlux在线程调用方面和Spring MVC还是又很大不同的,在使用中一定要注意WebFlux的特点,避免错误使用导致性能远低于预期。
如有错误,恳请批评指正!