Sqoop框架基础
本节我们主要需要了解的是大数据的一些协作框架,也是属于Hadoop生态系统或周边的内容,比如:
** 数据转换工具:Sqoop
** 文件收集库框架:Flume
** 任务调度框架:Oozie
** 大数据Web工具:Hue
这些框架为什么成为主流,请自行百度谷歌,此处不再赘述。
* CDH版本框架
Cloudera公司发布的CDH版本,在国内,很多大公司仍在使用,比如:一号店,京东,淘宝,百度等等。Cloudera公司发布的每一个CDH版本,其中一个最大的好处就是,帮我们解决了大数据Hadoop 2.x生态系统中各个框架的版本兼容问题,我们直接选择某一版本,比如CDH5.3.6版本,其中hadoop版本2.5.0,hive版本0.13.1,flume版本1.4.5;还有一点就是类似Sqoop、Flume、Oozie等框架,在编译的时候都要依赖对应的Hadoop 2.x版本,使用CDH版本的时候,已经给我们编译好了,无需再重新配置编译。
传送门已开启:CDH5.x版本下载地址
分享地址:链接:http://pan.baidu.com/s/1bpIPhxH 密码:qes2
* 安装配置CDH版本Hadoop
** 这一点与之前配置安装apache的hadoop差不多,所以,直接写主体思路:
1、在modules中创建新目录cdh来解压hadoop-cdh
2、修改hadoop以下配置文件的JAVA_HOME
** hadoop-env.sh
** yarn-env.sh
** mapred-env.sh
3、继续修改以下配置文件
** core-site.xml
** hdfs-site.xml
** yarn-site.xml
** mapred-site.xml
** slaves
4、拷贝至其他服务器
* 安装配置CDH版本zookeeper
1、修改zoo.cfg
2、修改myid(zkData目录不变的话,就不用再次修改了)
3、格式化HDFS,初始化zookeeper,并开启服务
三台机器:
分别开启:
** zookeeper服务,以及journalnode节点服务
$ sh /opt/modules/zookeeper-xx.xx.xx/bin/zkServer.sh start
$ sbin/hadoop-daemon.sh start journalnode
** 接着格式化namenode节点
$ bin/hadoop namenode -format
** 然后在备用namenode机器上执行元数据同步
$ bin/hdfs namenode -bootstrapStandby
** 最后依次启动即可
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
$ sbin/mr-jobhistory-daemon.sh start historyserver
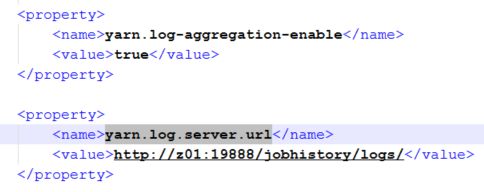
(尖叫提示:如果设置了日志聚合功能,请在yarn-site.xml中配置yarn.log.server.url,如下图)
(尖叫提示:如果重新制定了HDFS的Data目录,或者格式化了NameNode节点,请登录mysql删除metastore库,因为该库存储了hive数据仓库的元数据)
* 安装配置CDH版本Hive
** 修改如下配置文件:
** hive-env.sh
** hive-site.xml
** 拷贝JDBC驱动到hive的lib目录下
$ cp mysql-connector-java-5.1.27-bin.jar /opt/modules/cdh/hive-0.13.1-cdh5.3.6/lib/
** 启动mysql,设置用户,权限
忘记请翻阅前一篇文章
** 修改目录权限
确保HDFS正常运行,之后涉及命令:
$ bin/hadoop fs -chmod g+w /tmp
$ bin/hadoop fs -chmod g+w /user/hive/warehouse
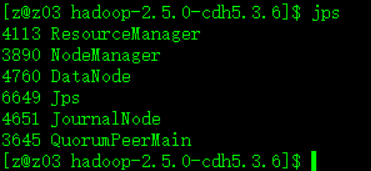
以上配置完成后我的三台机器的JPS分别为:
z01:

z02:
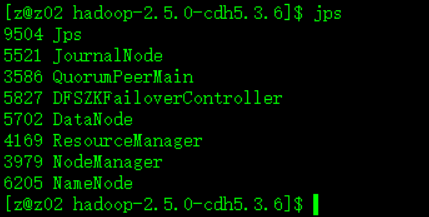
z03:
* Sqoop
** 什么?这个英文单词的意思?只能这么解释:
SQL-TO-HADOOP
看加粗部分即可明白,这个东西其实就是一个连接传统关系型数据库和Hadoop的桥梁,有如下两个主要功能:
** 把关系型数据库的数据导入到Hadoop与其相关的系统(HBase和Hive)中
** 把数据从Hadoop系统里抽取并导出到关系型数据库里
在转储过程中,sqoop利用mapreduce加快数据的传输速度,以批处理的方式进行数据传输。
如图所示:

** 版本划分
** sqoop1(1.4.x+)和sqoop2(1.99.x+),注意这两个版本是完全不兼容的
** sqoop2的进化:
*** 引入了sqoop server,集中化管理Connector
*** 多种访问方式:CLI,Web UI,REST API
*** 引入基于角色的安全机制
** sqoop设计架构
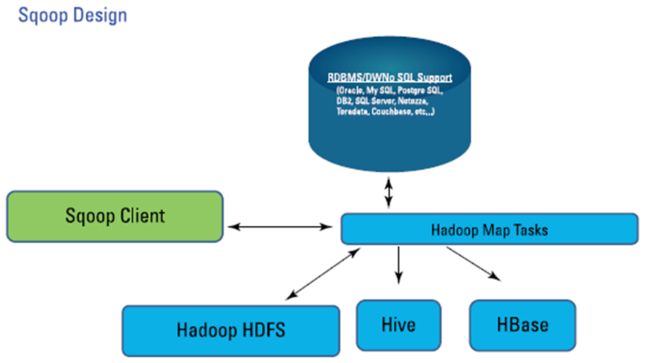
** sqoop使用逻辑
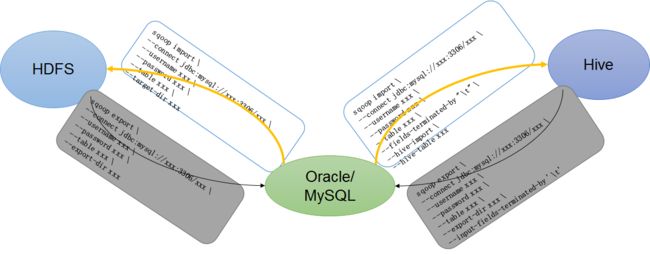
基于上图,我们需要理解几个概念:
** import:
向HDFS、hive、hbase中写入数据
** export
向关系型数据库中写入数据
** 安装sqoop
*** 将sqoop压缩包解压至/opt/modules/cdh目录下
*** 拷贝sqoop-env-template.sh文件并命名为sqoop-env.sh文件
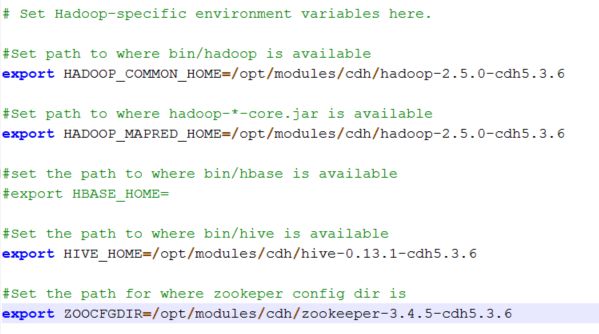
*** 配置sqoop-env.sh
根据里面的英文注释,应该也能够明白需要改些什么:没错,就是让sqoop去关联其他服务,hbase先不用管它。
配置好后如图:
*** 拷贝jdbc的驱动到sqoop的lib目录下
$ cp /opt/modules/apache-hive-0.13.1-bin/lib/mysql-connector-java-5.1.27-bin.jar lib/
** 开始玩耍sqoop
*** 查看sqoop帮助:
$ bin/sqoop help,如图:
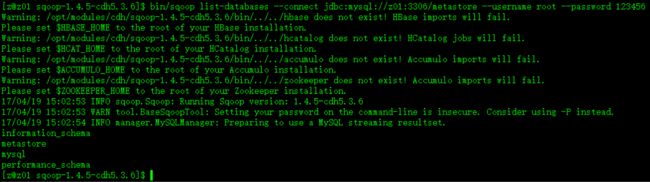
*** 测试sqoop是否连接成功
$ bin/sqoop list-databases --connect jdbc:mysql://z01:3306/metastore --username root --password 123456
如图:
* 接下来我们写几个例子,功能用法便可一目了然
例子1:RDBMS->HDFS
利用sqoop将mysql中的数据导入到HDFS中
step1、在mysql中创建一张表,表里面弄点数据
开启mysql服务:
# systemctl start mysqld.service
登入mysql服务:
# mysql -uroot -p123456
创建一个新的数据库:
mysql> create database db_demo;
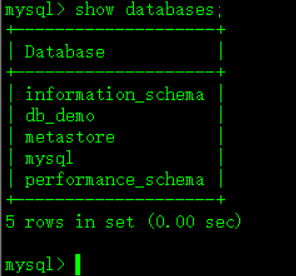
创建完成后,显示一下,如图:
在db_demo下创建一张表:
mysql> use db_demo;
mysql> create table user(
-> id int(4) primary key not null auto_increment,
-> name varchar(255) not null,
-> sex varchar(255) not null
-> );
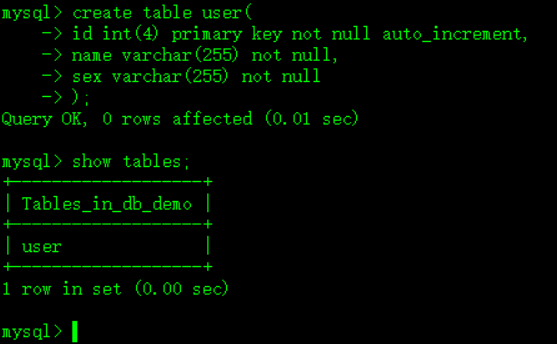
如图:
step2、向刚才创建的这张表中导入一些数据
mysql> insert into user(name, sex) values('Thomas','Male'); 如果需要插入行数据,你知道怎么做。
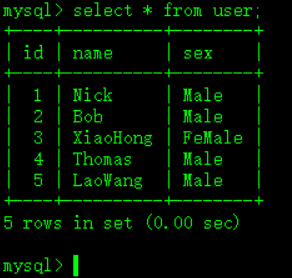
最后我的表变成了这样:
step3、使用sqoop导入数据至HDFS
形式1:全部导入
$ bin/sqoop import \
--connect jdbc:mysql://z01:3306/db_demo \
--username root \
--password 123456 \
--table user \
--target-dir /user/hive/warehouse/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
解释:
** --target-dir /user/hive/warehouse/user: 指定HDFS输出目录
** --delete-target-dir \:如果上面输出目录存在,就先删除
** --num-mappers 1 \:设置map个数为1,默认情况下map个是4,默认会在输出目录生成4个文件
** --fields-terminated-by \t:指定文件的分隔符为 \t
成功后,HDFS对应目录中会产生一个part文件,如图所示:
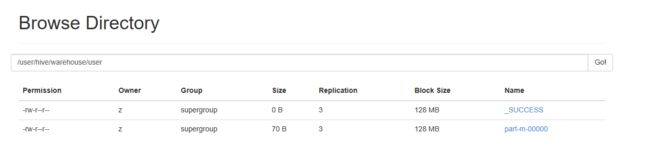
查看该文件:

形式2:导入指定查询结果
$ bin/sqoop import \
--connect jdbc:mysql://z01:3306/db_demo \
--username root \
--password 123456 \
--target-dir /user/hive/warehouse/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select id,name from user where id>=3 and $CONDITIONS'
解释:
--query 'select id,name from user where id>=3 and $CONDITIONS' :把select语句的查询结果导入
形式3:导入指定列
$ bin/sqoop import \
--connect jdbc:mysql://z01:3306/db_demo \
--username root \
--password 123456 \
--table user \
--target-dir /user/hive/warehouse/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,sex
形式4:where指定条件
$ bin/sqoop import \
--connect jdbc:mysql://z01:3306/db_demo \
--username root \
--password 123456 \
--table user \
--target-dir /user/hive/warehouse/user \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,name \
--where "id<=3"
例子2:Mysql -> Hive
利用sqoop将mysql里面的数据导入到Hive表
Step1、创建hive表(注:如果不创建,则自动生成表)
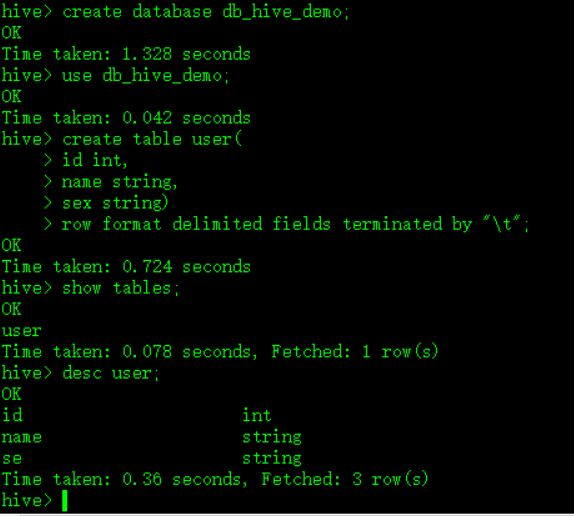
hive> create database db_hive_demo ;
create table db_hive_demo.user (
id int,
name string,
sex string
)
row format delimited fields terminated by "\t" ;
操作如图:
Step2、向hive中导入数据
$ bin/sqoop import \
--connect jdbc:mysql://z01:3306/db_demo \
--username root \
--password 123456 \
--table user \
--num-mappers 1 \
--hive-import \
--hive-database db_hive_demo \
--hive-table user \
--fields-terminated-by "\t" \
--delete-target-dir \
--hive-overwrite
完成后,查看:
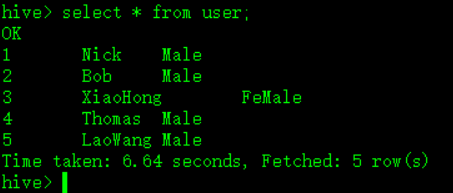
例子3:Hive/HDFS -> RDBMS
从Hive或HDFS中把数据导入mysql
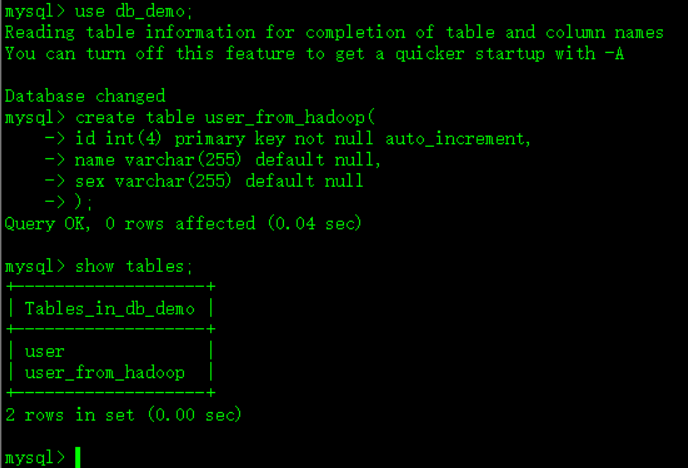
Step1、在mysql中创建一个待导入数据的表
mysql> use db_demo;
mysql> create table user_from_hadoop(
-> id int(4) primary key not null auto_increment,
-> name varchar(255) default null,
-> sex varchar(255) default null
-> );
如图:
Step2、将hive或者hdfs中的数据导入到mysql表中
$ bin/sqoop export \
--connect jdbc:mysql://z01:3306/db_demo \
--username root \
--password 123456 \
--table user_from_hadoop \
--num-mappers 1 \
--export-dir /user/hive/warehouse/db_hive_demo.db/user \
--input-fields-terminated-by "\t"
导入成功后,查看:
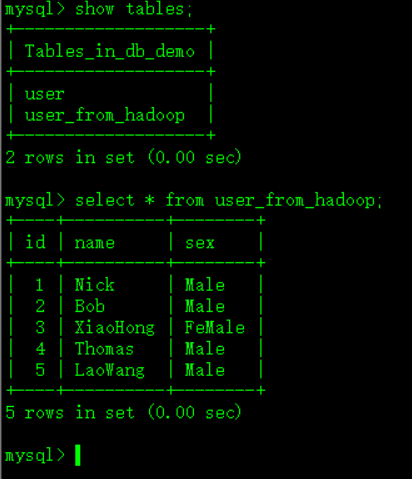
* Sqoop 其他用法
类似hive,sqoop也可以将语句保存在文件中,然后执行这个文件。
例如:
编写该文件:
$ mkdir opt/
vi opt/job_temp.opt,内容如图:
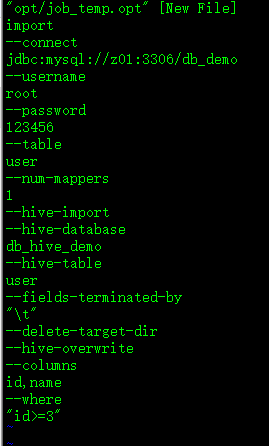
执行该文件:
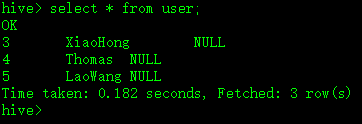
$ bin/sqoop --options-file opt/job_temp.opt,完成后查看该hive表,如图:
* 总结
本节讲解了如何在CDH中配置使用hadoop、hive、sqoop,以及学习了整个操作流程,大家可以自己试着练习一下,数据分析并把结果输出到Mysql数据库中以便于接口等服务。
IT全栈公众号:

QQ大数据技术交流群(广告勿入):476966007

下一节:Hive框架基础(四)后续更新