关键字:微服务, 分布式, 配置中心, Java编程, 推荐系统, 运维, 高并发, 高可用, 机器学习, 深度学习。
Microservices: A definition of this new architectural term Martin Fowler
微服务架构风格
- 一组微型的服务/独立开发/通过轻量级机制通信/自动化的独立部署/各服务之间可采用不同语言和技术方案;
- 很难给微服务下一个具体的定义,Martin Fowler通过九大特性来阐述微服务;
the microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery. There is a bare minimum of centralized management of these services, which may be written in different programming languages and use different data storage technologies.
微服务的九大特性
1. 组件化与服务
- 组件(component)是一个可以独立更换和升级的软件单元;
- 软件库)(libraries是能被链接到程序且通过方法调用的组件;
- 服务(services)是进程外的组件,通过web service或rpc的机制来通信;
- 使用服务而非软件库的方式来组件化的主要原因是服务可被独立部署(避免一个组件修改导致需要重新部署整个应用),另外一个好处是能获得更加显式的组件接口(想想单体应用中的API依赖);
- 当然也有不足之处,比如远程调用比进程内的调用要更加昂贵;
2. 围绕业务功能组织团队
- 对一个大型的应用进行分解时,通常是按照技术层面来进行划分,比如分为前端开发、后端开发和数据库开发(当然实际情况比这更细),但是这样会带来一个问题就是一个很小的需求都需要跨团队的项目合作和进度安排;这就是康威定律(任何设计系统的组织,都会产生这样一个设计,即该设计的结构与该组织的沟通结构相一致)起作用的例子;
- 而微服务是通过业务功能将系统分解为若干服务,这些服务针对该业务领域提供多层次广泛的软件实现;因此团队是跨职能的,它拥有软件开发所需的全方位的技能(如用户体验、数据库和项目管理);
- 大型单体应用系统也可以根据业务功能进行模块化设计,但是通常的问题是一个团队会包含太多的功能,而团队之间的边界也不够清晰;
3. 做产品而非做项目
- 大部分的应用开发都使用这样一个产品模型:一旦某项软件功能已交付,就会将软件移交给维护团队,而开发团队随之被解散;
- 而微服务主张“一个团队应该拥有该产品的整个生命周期”(原子亚马逊的“you build, you run it”)这样的理念,即一个开发团队对一个生产环境下运行的软件负全责;
- 这样的产品理念是与业务功能相绑定的,它不会把软件开成是一系列待完成功能的集合,而是一种持续提升客户业务功能的关系;
- 当然,单体应用也可以采用上述的产品理念,但是更细粒度的服务能使服务的开发者和它的用户更近;
4. 智能终端和傻瓜管道
- 在不同的进程进行通信时,多数的产品或方法会在其中加入大量的智能特性,有个典型的例子就是ESB(企业服务总线),它通常包括消息路由、编制、转换和业务规则应用;
- 而微服务主张采用另一种做法:智能终端(smart endpoints)和傻瓜管道(dumb pipes)。这里的理解是应该尽可能地简化进程间的通信,将一些需要智能处理的逻辑(比如路由、重试等)交给服务处理;
- 微服务最常用的两种协议是:带有资源API的HTTP请求-响应协议和轻量级的消息发送协议(如RabbitMQ、ZeroMQ);
- 将一个单体应用拆分为微服务的最大挑战就是改变原有的通信模式,如果直接将原先的进程内方法调用改为RPC会导致微服务直接产生繁琐的通信,因此应该考虑更粗粒度的方式调用;
5. 去中心化的治理
- 集中治理的一个问题是会趋向于在单一技术平台上制定标准从而带来局限性;
- 微服务中的分权治理(去中心化的)使得每个服务可以选择不同的技术,比如选择不同的语言和数据库;
- 相比于选用一组已定义好的标准,微服务的开发者更喜欢自己编写一些有用的工具,这些工具通常源于他们的微服务实施过程并分享给更多的团队;比如Nteflix就是一个很好的例子,这家提供网络视频点播的公司开源了一系列的实施微服务的工具;
- 对微服务社区来说,像容错读取(Tolerant Reader)和消费者驱动的契约(Consumer-Driven Contracts)的模式已经被用于日常管理;
- 像Netflix这样的公司已经开始推行分权治理,这样可以令程序员更加注重质量(谁都不想半夜被电话叫去修复问题对吧),而这些与之前传统的集中治理有着天壤之别;
6. 去中心化的数据管理
- 去中心化的数据管理从最抽象的层面看,意味着各个系统对客观世界所构建的概念模型将彼此不同,比如客户的概念对于销售和支撑团队就有所不同;
- 思考这类问题的一个有用的方法就是使用领域驱动设计(Domain-Driven Design, DDD)中的上下文边界(Bounded Context)的概念;DDD将一个复杂的领域划分为多个上下文边界,并且将它们的相互关系用图表示出来;
- 不同于单体应用喜欢共用一个单独的数据库(也许是被商业数据库的license逼出来的),微服务更喜欢让每一个服务管理其自有的数据库,可以采用相同数据库技术的不同实例,也可以采用完全不同的数据库系统;
- 但是去中心化的数据管理会带来数据一致性的问题,对此微服务强调的是无事务的协调(transactionless coordination between services),这源自微服务社区明确地认识到以下两点:即数据一致性可能只要求数据最终一致性,并且一致性问题能够通过补偿操作来进行处理;
7. 基础设施自动化
- 云的发展已经很大程度上降低了构建、部署和运维微服务的复杂性了;
- 许多使用微服务构建的团队都具备持续交付(Continuous Delivery)的经验,这样的团队广泛采用了基础设施自动化的技术,如下图的构建流水线所示:

- 持续交付需要大量的自动化测试以及自动化部署的能力,通过这两个关键特点使得我们能更有信心、更愉快地部署功能到生成环境;另外,微服务的独立性也使得部署更加容易(这里的容易是指只需要部署修改的服务而不需要部署整个应用),当然也会带来困难(原来只需要部署一个系统,而现在需要部署更多的服务),此时就需要在部署工具上投入精力改进;
8. 容错设计
- 使用微服务作为组件,需要设计成能容忍这些服务所出现的故障;一旦某个服务出现故障,其他任何对该服务的调用都会出现故障,客户端需要尽可能优雅地处理这种情况;与单体应用相比,这是微服务引入的额外的复杂性;
- Netflix公司开源的Simian Army能够诱导服务发生故障来测试应用的弹性和监控能力;
- 断路器(Circuit Breaker)是一种用于隔离故障的模式,Netflix公司的这篇很精彩的博客解释了这些模式是如何应用的;
- 容错设计要求能够快速地检测出故障,而且在可能的情况下自动恢复服务;此时实时监控就变得非常重要,它可用来检查架构元素指标(比如数据库每秒接收到多少请求)和业务相关指标(如系统每分钟收到多少订单)以便预测故障的发生;这对于微服务来说尤为重要,因为微服务对于服务编排和事件协作的偏好更易导致突发行为;
- 采用微服务的团队通常希望使用仪表盘或者日志记录装置来监控服务的运行和各项指标;
9. 演进式设计
- 每当试图将软件系统拆分为各个组件时,都会面对一个棘手的问题,即如何拆分,拆分的原则是什么?
- 一个组件的关键属性,是具有独立可替换性和可升级性(independent replacement and upgradeability),这使得我们在重写一个组件时更多的是聚焦于功能而非与不用担心与其他的关联组件;
- 而事实上,许多做微服务的团队会更进一步,他们明确地预期许多服务将来会报废而不是长期演进;比如英国卫报网站,他们依然使用原先的单体应用作为网站核心,而对于一些新的功能,比如增加报道一个体育赛事的页面,就会采用微服务的方式来添加,一旦赛事结束了,这个服务就可以被废除;
- 这种强调可更换性的特点是模块化设计一般性原则的一个特例,通过变化模式(the pattern of change)来驱动进行模块化的实现;将那些能在同时发生变化的东西放到相同的模块中,如果发现需要同时反复变更两个服务是,这就是它们两个需要被合并的一个信号;
- 将一个个组件放入一个个服务中增加了做出更精细化版本发布的机会,对于单体应用,任何变化都需要做一次整个应用系统的全量构建和部署,而对微服务来说,只需要部署修改的服务即可;
微服务是未来的方向吗?
- 作者通过该文阐述了微服务的主要思路和原则,在当时已经有一些公司如亚马逊和Netflix提供了正面的经验,收到了不少正面的评价;
- 架构决策所产生的真正效果通常需要若干年后才能真正显现,当时考虑的限制微服务的因素主要有组件拆分的难度、组件直接的复杂关联关系以及团队技能,但从目前的发展来看,已经有越来越多的企业采用了微服务的架构;
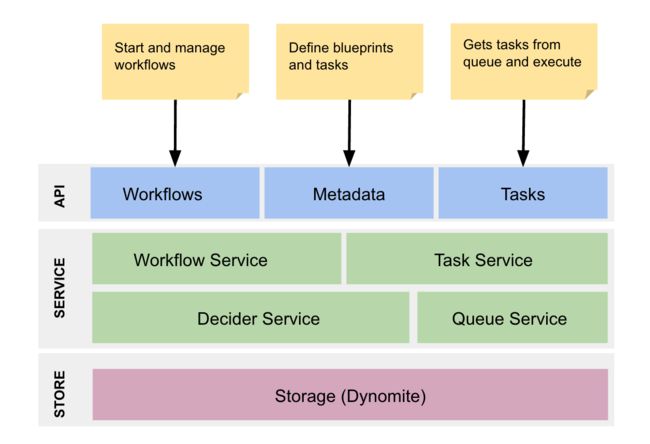
Netflix Conductor:一个微服务编制引擎 Abel Avram/杨雷
- Netflix开发了一个叫Conductor的编制引擎,已经在内部生产环境中使用了一年了。在这段时间里,Netflix已经运行了大约260万个处理工作流,包括简单的线性工作流,以及运行数天的动态工作流。
- 主要特性:能够构建复杂工作流;能够通过微服务执行任务;使用JSON DSL描述的工作流蓝图;执行过程可见、可跟踪;能够暂停、恢复、重启、停止任务;任务执行通常是异步的,也可以强制同步执行;处理工作流能够扩展到百万级别;
- Conductor的架构图如下所示;其中API和存储层都是可插拔的,允许使用不同的队列和存储引擎;工作流中的任务分为两种类型:Worker(运行在远端机器上的用户任务和System(运行在引擎的JVM上的任务),后者是用来对Worker执行任务进行branch、fork、join;Worker任务通过HTTP或者gRPC和Conductor通信;
深度学习并不是在“模拟人脑” 周志华
- 当特征信息和样本信息不充分时,机器学习可能就帮不上忙;
- 用机器学习解决问题更多的时候像一个裁缝,一定要量体裁衣,针对某个问题专门设计有效的方法,这样才能得到一个更好的结果;按需设计、度身定制,是在做机器学习应用的时候特别重要的一点;
- 机器学习有着深厚的理论基础,其中最基本的理论模型叫做概率近似正确模型;机器学习做的事情,是你给我数据之后,希望能够以很高的概率给出一个好模型;
- 从生物机理来说的话,一个神经元收到很多其它神经元发来的电位信号,信号经过放大到达它这里,如果这个累积信号比它自己的电位高了,那这个神经元就被激活了;其实神经网络本质上,是一个简单函数通过多层嵌套叠加形成的一个数学模型,背后其实是数学和工程在做支撑;而神经生理学起的作用,可以说是给了一点点启发,但是远远不像现在很多人说的神经网络研究受到神经生理学的“指导”,或者是“模拟脑”;
- 深度学习火起来的3个因素:有了大量的训练数据、有很强的计算设备、使用大量的“窍门”(Trick);
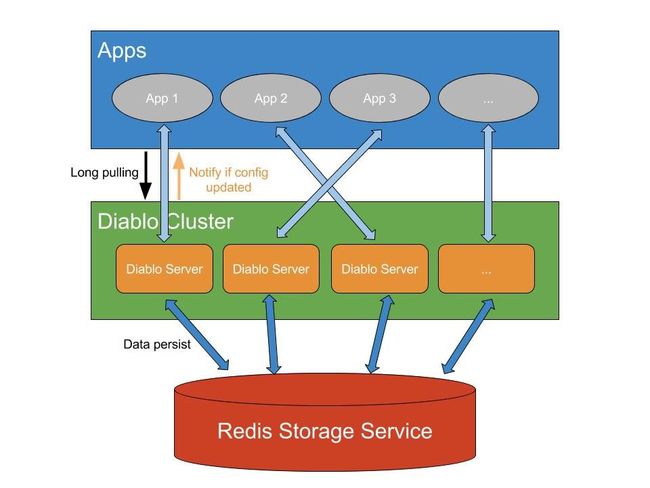
分布式配置管理平台的设计与实现 架构文摘
- 分布式配置平台的一些应用场景:对某些配置的更新,不想要重启应用,并且能近似实时生效;希望将配置进行统一管理,而非放入各应用的配置文件中;
- 分布式配置平台需要满足的一些基本特性:高可用性(服务器集群应该无单点故障)、容错性(主要针对客户端,应保证即便在配置平台不可用时,也不影响客户端的正常运行)、高性能、可靠的存储、近似实时生效、负载均衡、扩展性;
- 分布式配置平台Diablo的设计与实现:对等的服务器集群(Server被视为是对等的,没有主从关系)、高性能处理(客户端应用获取配置时,仅会从本地缓存中获取,开发人员在控制台更改配置后,会通知客户端刷新缓冲)、使用Redis作存储、重试等待(diablo会通过重试等待等机制保证,在服务端集群不可用时,也不会影响客户端应用的正常运行,而是等待集群恢复)、请求负载(使用一致性哈希分配客户端连接是Server)、配置更新实时生效(diablo使用了特殊Pull模式,即长轮询);
一篇好TM长的关于配置中心的文章 坤宇
- 每一个分布式系统都应该有一个动态配置管理系统
- 配置与环境:某个配置项,其具体的值域的定义往往跟具体的环境相关联,现实中相当一部分配置在不同的环境必须设定不同的值,但是也有相当的另一部分配置在不同的环境要设定为完全一致的值。配置管理系统应该做的是提供方便的交互方式保证这两种不同的一致性诉求同时得到很好的满足,这种诉求分为3个方面,如下示意图:

- 另外,一个配置中心也应该具备的能力是配置集的导出\导入功能,可以让应用将A环境中的配置集方便的导出和导入到环境B中的能力;
- 业界最新动态:Apache Commons Configuration(太繁琐)、owner(简单易上手,特性看起来很多,但是在很多关键常用的特性反倒是没有)、cfg4j(简单易上手,cfg4j 支持跟多种后端集成,做配置中心的解决方案,api设计也非常的不错)、Spring Framework、Spring Cloud Config Server;
- 配置(configuration)与元数据(metadata):配置的修改基本上都是由人来驱动,并且在ops上实现变更;而元数据的本质是一小段程序元数据,它很多时候是程序产生,程序消费,由程序通过调用Diamond的客户端api来实现变更,中间不会有ops 或者人的介入。Diamond 不光是应用配置存储,其目前存储的数据,很大一部分是metadata,所以Diamond 其实也是一个元数据存储中心。
Reddit是如何使用Memcached来存储3TB缓存数据的? 薛命灯
Reddit的缓存规模和基本策略
Reddit目前使用了54个规格为r3.2xlarge的AWS EC2实例,每个实例拥有61GB内存,也就是说总的缓存大小差不多是3.3TB。Reddit的缓存包含了多种类型的数据,包括数据库对象、查询结果集、函数调用,还有一些看起来不太像缓存的东西,比如限定速率、分布式锁等等。

如何管理这么大规模的缓存是一件很挑战性的事情,Reddit采用的是“不要把所有鸡蛋放在同一个篮子里”的基本策略。也就是说,他们并不是把3.3TB的内存看成一个总的大缓存池,而是按照负载类型对缓存进行分类,每种类型占用一定数量的缓存空间。
Reddit的缓存类型
- 数据库对象缓存(thing-cache):Reddit最大的缓存池。这些对象是无schema的,开发人员可以很容易地对这些对象添加新属性,而无需对数据库schema进行变更。这些对象包括用户评论、链接和账户等等。该类型缓存是Reddit最繁忙也最有用的缓存,命中率高达99%。
- 主缓存(cache-main):主缓存是Reddit第二大缓存池。这个缓存是一般性的缓存,里面存放的所有用来展示/r/all的结果集。
- 渲染缓存(cache-render):第三大缓存用来存放渲染过的页面模板或页面片段。这个缓存相对安全,就算发生失效,也不会对系统造成太大影响。它的命中率只有大概50%左右,毕竟页面信息需要不断更新,所以渲染过的页面模板或片段也需要更新。
- 持久缓存(cache-perma):它的命中率超过了99%。这个缓存用来存放数据库的查询结果,还有用户评论和链接。为什么管这个缓存叫持久缓存,因为他们使用了读-改-写(read-modify-write)的模式。例如,在用户新增一个评论时,他们会同时更新缓存和后端的数据库(Cassandra),而不是简单地让缓存失效,这样就避免了需要再次从数据库加载数据。
- 非缓存对象池:除了上述的几种缓存,Reddit还使用了速率限定和分布式锁。
mcrouter
- mcrouter是由Facebook开源的Memcached连接池。就像访问数据库要使用数据库连接池一样,使用连接池可以对连接进行重用和管理,避免了重复创建和销毁连接的开销。
- mcrouter提供了多种路由类型,比如PrefixSelectorRoute,它通过匹配key的前缀来决定应该到哪个缓存上获取数据。这样就可以把特定功能的操作路由到特定的缓存上。
- 如果要往缓存集群里增加新的缓存实例,那么可以使用WarmUpRoute。WarmUpRoute的工作原理是说,把所有写操作路由到“冷”缓存上,而把未命中的读操作路由到“热”缓存上,然后把在“热”缓存上命中的缓存结果异步地更新到“冷”缓存上,那么下次同样的读操作就也可以在“冷”缓存上命中。
- mcrouter还提供了FailoverRoute,顾名思义,这个特性可以避免缓存的单点故障;
- Reddit还使用了影子缓存,不同于WarmUpRoute,它会把读操作和写操作都拷贝一份到新的实例上,但前提是不改变数据源。
自定义监控
- 基于Memcached的“stats slabs”命令自己写了一个追踪板块度量指标的工具,他们还开发了一个简陋的可视化仪表盘;
- Reddit团队还开发了另外一个工具,叫作mcsauna。这个工具被部署在每个缓存服务器上,它可以检测网络流量,并根据配置规则把不同的key保存在不同的bucket里,然后把结果输出到文件上。FilesCollector会收集这些文件,分析里面的key,并以图形化的方式呈现出来。从这些图形上可以看出那些热点的key。
展望
缓存为提升网站的响应速度做出了不可磨灭的贡献。而在如何使用缓存方面,Reddit还有很长的路要走。接下来,他们可能要想着如何通过服务发现来对配置进行自动化,从而实现缓存的自动扩展,而不需要人工的介入。而随着Memcached版本的不断改进,他们也要针对现有系统进行调整,从而最大化缓存的性能。
微信高并发资金交易系统设计方案 方乐明
- 微信红包的两大业务特点:微信红包业务比普通商品“秒杀”有更海量的并发要求、微信红包业务要求更严格的安全级别;
- 微信红包系统的技术难点:事务级操作量级大、事务性要求严格;
- 解决高并发问题常用方案:使用内存操作替代实时的DB事务操作(用内存操作替代磁盘操作,提高了并发性能,但是DB持久化可能会丢数据)、使用乐观锁替代悲观锁(可以提高DB的并发处理能力,但是回滚失败带来很差的用户体验);
微信红包系统的高并发解决方案
系统垂直SET化,分而治之
红包系统根据微信红包ID,按一定的规则(如按ID尾号取模等),垂直上下切分。切分后,一个垂直链条上的逻辑Server服务器、DB统称为一个SET。各个SET之间相互独立,互相解耦。并且同一个红包ID的所有请求,包括发红包、抢红包、拆红包、查详情详情等,垂直stick到同一个SET内处理,高度内聚。通过这样的方式,系统将所有红包请求这个巨大的洪流分散为多股小流,互不影响,分而治之。
逻辑Server层将请求排队,解决DB并发问题。
如果到达DB的事务操作不是并发的,而是串行的,就不会存在“并发抢锁”的问题了。按这个思路,为了使拆红包的事务操作串行地进入DB,只需要将请求在Server层以FIFO的方式排队,就可以达到这个效果。从而问题就集中到Server的FIFO队列设计上。
微信红包系统设计了分布式的、轻巧的、灵活的FIFO队列方案。其具体实现如下:
- 将同一个红包ID的所有请求stick到同一台Server;
- 设计单机请求排队方案:将stick到同一台Server上的所有请求在被接收进程接收后,按红包ID进行排队。然后串行地进入worker进程(执行业务逻辑)进行处理,从而达到排队的效果;
- 增加memcached控制并发:利用memcached的CAS原子累增操作,控制同时进入DB执行拆红包事务的请求数,超过预先设定数值则直接拒绝服务。用于DB负载升高时的降级体验;
双维度库表设计,保障系统性能稳定
处理微信红包数据的冷热分离时,系统在以红包ID维度分库表的基础上,增加了以循环天分表的维度,形成了双维度分库表的特色。具体来说,就是分库表规则像db_xx.t_y_dd设计,其中,xx/y是红包ID的hash值后三位,dd的取值范围在01~31,代表一个月天数最多31天。通过这种双维度分库表方式,解决了DB单表数据量膨胀导致性能下降的问题,保障了系统性能的稳定性。同时,在热冷分离的问题上,又使得数据搬迁变得简单而优雅。
分布式系统理论基础 - 一致性、2PC和3PC bangerlee
- 狭义的分布式系统指由网络连接的计算机系统,每个节点独立地承担计算或存储任务,节点间通过网络协同工作。广义的分布式系统是一个相对的概念,正如Leslie Lamport所说:
What is a distributed systeme. Distribution is in the eye of the beholder.
To the user sitting at the keyboard, his IBM personal computer is a nondistributed system.
To a flea crawling around on the circuit board, or to the engineer who designed it, it's very much a distributed system.
- 一致性是分布式理论中的根本性问题;何为一致性问题?简单而言,一致性问题就是相互独立的节点之间如何达成一项决议的问题。分布式系统中,进行数据库事务提交(commit transaction)、Leader选举、序列号生成等都会遇到一致性问题。
- 假设一个具有N个节点的分布式系统,当其满足以下条件时,我们说这个系统满足一致性:全认同(agreement)、值合法(validity)、可结束(termination);
- 分布式系统实现起来并不轻松,因为它面临着这些问题:消息传递异步无序(asynchronous)、节点宕机(fail-stop)、节点宕机恢复(fail-recover)、网络分化(network partition)、拜占庭将军问题(byzantine failure);
- 一致性还具备两个属性,一个是强一致(safety),它要求所有节点状态一致、共进退;一个是可用(liveness),它要求分布式系统24*7无间断对外服务。FLP定理(FLP impossibility)已经证明在一个收窄的模型中(异步环境并只存在节点宕机),不能同时满足safety和liveness。FLP定理是分布式系统理论中的基础理论,正如物理学中的能量守恒定律彻底否定了永动机的存在,FLP定理否定了同时满足safety和liveness的一致性协议的存在。
2PC
2PC(tow phase commit,两阶段提交)顾名思义它分成两个阶段,先由一方进行提议(propose)并收集其他节点的反馈(vote),再根据反馈决定提交(commit)或中止(abort)事务。我们将提议的节点称为协调者(coordinator),其他参与决议节点称为参与者(participants, 或cohorts)。
在阶段一中,coordinator发起一个提议,分别问询各participant是否接受。

在阶段二中,coordinator根据participant的反馈,提交或中止事务,如果participant全部同意则提交,只要有一个participant不同意就中止。
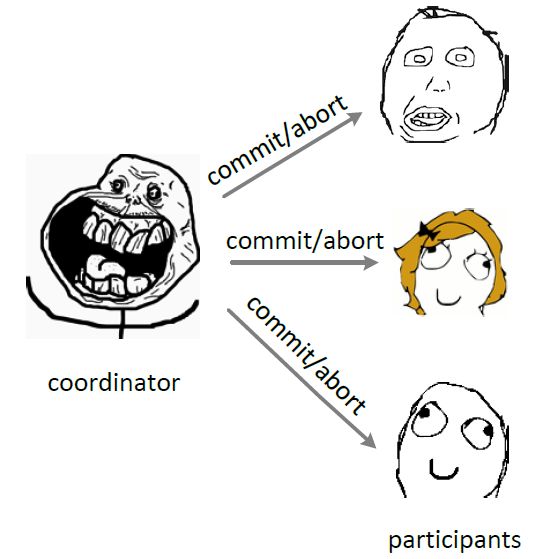
在异步环境(asynchronous)并且没有节点宕机(fail-stop)的模型下,2PC可以满足全认同、值合法、可结束,是解决一致性问题的一种协议。但如果再加上节点宕机(fail-recover)的考虑,就要求 coordinator/participant 记录历史状态,以备coordinator宕机后watchdog对participant查询、coordinator宕机恢复后重新找回状态;
3PC
在2PC中一个participant的状态只有它自己和coordinator知晓,假如coordinator提议后自身宕机,在watchdog启用前一个participant又宕机,其他participant就会进入既不能回滚、又不能强制commit的阻塞状态,直到participant宕机恢复。这引出两个疑问:
- 能不能去掉阻塞,使系统可以在commit/abort前回滚(rollback)到决议发起前的初始状态;
- 当次决议中,participant间能不能相互知道对方的状态,又或者participant间根本不依赖对方的状态;
相比2PC,3PC增加了一个准备提交(prepare to commit)阶段来解决以上问题。coordinator接收完participant的反馈(vote)之后,进入阶段2,给各个participant发送准备提交(prepare to commit)指令。participant接到准备提交指令后可以锁资源,但要求相关操作必须可回滚。coordinator接收完确认(ACK)后进入阶段3、进行commit/abort,3PC的阶段3与2PC的阶段2无异。协调者备份(coordinator watchdog)、状态记录(logging)同样应用在3PC。

因为有了准备提交(prepare to commit)阶段,3PC的事务处理延时也增加了1个RTT,变为3个RTT(propose+precommit+commit),但是它防止participant宕机后整个系统进入阻塞态,增强了系统的可用性,对一些现实业务场景是非常值得的。
分布式系统理论基础 - 选举、多数派和租约 bangerlee
- 选举(election)是分布式系统实践中常见的问题,通过打破节点间的对等关系,选得的leader(或叫master、coordinator)有助于实现事务原子性、提升决议效率。多数派(quorum)的思路帮助我们在网络分化的情况下达成决议一致性,在leader选举的场景下帮助我们选出唯一leader。租约(lease)在一定期限内给予节点特定权利,也可以用于实现leader选举。
- 选举(electioin):一致性问题(consistency)是独立的节点间如何达成决议的问题,选出大家都认可的leader本质上也是一致性问题;Bully算法是最常见的选举算法,其要求每个节点对应一个序号,序号最高的节点为leader,leader宕机后次高序号的节点被重选为leader;Bully算法中有2PC的身影,都具有提议(propose)和收集反馈(vote)的过程;在一致性算法Paxos、ZAB、Raft中,为提升决议效率均有节点充当leader的角色;
- 多数派(quorum):在网络分化的场景下以上Bully算法会遇到一个问题,被分隔的节点都认为自己具有最大的序号、将产生多个leader;多数派的思路在分布式系统中很常见,其确保网络分化情况下决议唯一;多数派的原理说起来很简单,假如节点总数为2f+1,则一项决议得到多于 f 节点赞成则获得通过。leader选举中,网络分化场景下只有具备多数派节点的部分才可能选出leader,这避免了多leader的产生;
- 租约(lease):选举中很重要的一个问题,怎么判断leader不可用、什么时候应该发起重新选举?最先可能想到会通过心跳(heart beat)判别leader状态是否正常,但在网络拥塞或瞬断的情况下,这容易导致出现双主;租约(lease)是解决该问题的常用方法,其最初提出时用于解决分布式缓存一致性问题,后面在分布式锁等很多方面都有应用;租约的原理同样不复杂,中心思想是每次租约时长内只有一个节点获得租约、到期后必须重新颁发租约;租约机制确保了一个时刻最多只有一个leader,避免只使用心跳机制产生双主的问题,在实践应用中,zookeeper、ectd可用于租约颁发。
分布式系统理论基础 - 时间、时钟和事件顺序 bangerlee
- 现实生活中时间是很重要的概念,时间可以记录事情发生的时刻、比较事情发生的先后顺序。分布式系统的一些场景也需要记录和比较不同节点间事件发生的顺序,但不同于日常生活使用物理时钟记录时间,分布式系统使用逻辑时钟记录事件顺序关系;
- 在1978年提出逻辑时钟的概念,并描述了一种逻辑时钟的表示方法,这个方法被称为Lamport时间戳(Lamport timestamps)。分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。Lamport时间戳原理如下:
每个事件对应一个Lamport时间戳,初始值为0
如果事件在节点内发生,时间戳加1
如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1

- Lamport时间戳帮助我们得到事件顺序关系,但还有一种顺序关系不能用Lamport时间戳很好地表示出来,那就是同时发生关系(concurrent)。Vector clock是在Lamport时间戳基础上演进的另一种逻辑时钟方法,它通过vector结构不但记录本节点的Lamport时间戳,同时也记录了其他节点的Lamport时间戳。Vector clock的原理与Lamport时间戳类似,使用图例如下:

- 基于Vector clock我们可以获得任意两个事件的顺序关系,结果或为先后顺序或为同时发生,识别事件顺序在工程实践中有很重要的引申应用,最常见的应用是发现数据冲突(detect conflict)。分布式系统中数据一般存在多个副本(replication),多个副本可能被同时更新,这会引起副本间数据不一致,Version vector的实现与Vector clock非常类似,目的用于发现数据冲突。下面通过一个例子说明Version vector的用法:

- Vector clock只用于发现数据冲突,不能解决数据冲突。如何解决数据冲突因场景而异,具体方法有以最后更新为准(last write win),或将冲突的数据交给client由client端决定如何处理,或通过quorum决议事先避免数据冲突的情况发生。
- 由于记录了所有数据在所有节点上的逻辑时钟信息,Vector clock和Version vector在实际应用中可能面临的一个问题是vector过大,用于数据管理的元数据(meta data)甚至大于数据本身。解决该问题的方法是使用server id取代client id创建vector (因为server的数量相对client稳定),或设定最大的size、如果超过该size值则淘汰最旧的vector信息。
- 小结:以上介绍了分布式系统里逻辑时钟的表示方法,通过Lamport timestamps可以建立事件的全序关系,通过Vector clock可以比较任意两个事件的顺序关系并且能表示无因果关系的事件,将Vector clock的方法用于发现数据版本冲突,于是有了Version vector。
分布式系统理论基础 - CAP bangerlee
- CAP由Eric Brewer在2000年PODC会议上提出,是Eric Brewer在Inktomi期间研发搜索引擎、分布式web缓存时得出的关于数据一致性(consistency)、服务可用性(availability)、分区容错性(partition-tolerance)的猜想:
It is impossible for a web service to provide the three following guarantees : Consistency, Availability and Partition-tolerance.
- 该猜想在提出两年后被证明成立[4],成为我们熟知的CAP定理:
数据一致性(consistency):如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据,对调用者而言数据具有强一致性(strong consistency) ;
服务可用性(availability):所有读写请求在一定时间内得到响应,可终止、不会一直等待;
分区容错性(partition-tolerance):在网络分区的情况下,被分隔的节点仍能正常对外服务;
- 在某时刻如果满足AP,分隔的节点同时对外服务但不能相互通信,将导致状态不一致,即不能满足C;如果满足CP,网络分区的情况下为达成C,请求只能一直等待,即不满足A;如果要满足CA,在一定时间内要达到节点状态一致,要求不能出现网络分区,则不能满足P。C、A、P三者最多只能满足其中两个,和FLP定理一样,CAP定理也指示了一个不可达的结果(impossibility result)。
- 要理解P,我们看回CAP证明中P的定义:
In order to model partition tolerance, the network will be allowed to lose arbitrarily many messages sent from one node to another.
网络分区的情况符合该定义,网络丢包的情况也符合以上定义,另外节点宕机,其他节点发往宕机节点的包也将丢失,这种情况同样符合定义。现实情况下我们面对的是一个不可靠的网络、有一定概率宕机的设备,这两个因素都会导致Partition,因而分布式系统实现中P是一个必须项,而不是可选项。对于分布式系统工程实践,CAP理论更合适的描述是:在满足分区容错的前提下,没有算法能同时满足数据一致性和服务可用性:
In a network subject to communication failures, it is impossible for any web service to implement an atomic read/write shared memory that guarantees a response to every request.
- CAP定理证明中的一致性指强一致性,强一致性要求多节点组成的被调要能像单节点一样运作、操作具备原子性,数据在时间、时序上都有要求。如果放宽这些要求,还有序列一致性(sequential consistency)和最终一致性(eventual consistency)。工程实践中,较常见的做法是通过异步拷贝副本(asynchronous replication)、quorum/NRW,实现在调用端看来数据强一致、被调端最终一致,在调用端看来服务可用、被调端允许部分节点不可用的效果。
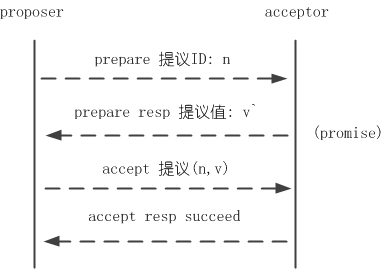
分布式系统理论进阶 - Paxos bangerlee
- Paxos协议在节点宕机恢复、消息无序或丢失、网络分化的场景下能保证决议的一致性,是被讨论最广泛的一致性协议。
- 一致性问题是在节点宕机、消息无序等场景可能出现的情况下,相互独立的节点之间如何达成决议的问题,作为解决一致性问题的协议,Paxos的核心是节点间如何确定并只确定一个值(value)。
- 和2PC类似,Paxos先把节点分成两类,发起提议(proposal)的一方为proposer,参与决议的一方为acceptor。
P1. 一个acceptor接受它收到的第一项提议 //假如只有一个proposer发起提议,并且节点不宕机、消息不丢包
P2. 如果一项值为v的提议被确定,那么后续只确定值为v的提议
P2a. 如果一项值为v的提议被确定,那么acceptor后续只接受值为v的提议
P2b. 如果一项值为v的提议被确定,那么proposer后续只发起值为v的提议
P2c. 对于提议(n,v),acceptor的多数派S中,如果存在acceptor最近一次(即ID值最大)接受的提议的值为v',那么要求v = v';否则v可为任意值
- 以上提到的各项约束条件可以归纳为3点,如果proposer/acceptor满足下面3点,那么在少数节点宕机、网络分化隔离的情况下,在“确定并只确定一个值”这件事情上可以保证一致性(consistency):
B1(ß): ß中每一轮决议都有唯一的ID标识
B2(ß): 如果决议B被acceptor多数派接受,则确定决议B
B3(ß): 对于ß中的任意提议B(n,v),acceptor的多数派中如果存在acceptor最近一次(即ID值最大)接受的提议的值为v',那么要求v = v';否则v可为任意值
- 至此,proposer/acceptor完成一轮决议可归纳为prepare和accept两个阶段。prepare阶段proposer发起提议问询提议值、acceptor回应问询并进行promise;accept阶段完成决议,图示如下:
分布式系统理论进阶 - Raft、Zab bangerlee
- Paxos偏向于理论、对如何应用到工程实践提及较少。理解的难度加上现实的骨感,在生产环境中基于Paxos实现一个正确的分布式系统非常难;Raft在2013年提出,提出的时间虽然不长,但已经有很多系统基于Raft实现。相比Paxos,Raft的买点就是更利于理解、更易于实行。
- 为达到更容易理解和实行的目的,Raft将问题分解和具体化:Leader统一处理变更操作请求,一致性协议的作用具化为保证节点间操作日志副本(log replication)一致,以term作为逻辑时钟(logical clock)保证时序,节点运行相同状态机(state machine)得到一致结果。Raft协议具体过程如下:
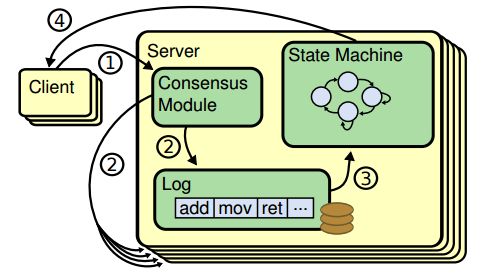
①Client发起请求,每一条请求包含操作指令
②请求交由Leader处理,Leader将操作指令(entry)追加(append)至操作日志,紧接着对Follower发起AppendEntries请求、尝试让操作日志副本在Follower落地
③如果Follower多数派(quorum)同意AppendEntries请求,Leader进行commit操作、把指令交由状态机处理
④状态机处理完成后将结果返回给Client
- Paxos中Leader的存在是为了提升决议效率,Leader的有无和数目并不影响决议一致性,Raft要求具备唯一Leader,并把一致性问题具体化为保持日志副本的一致性,以此实现相较Paxos而言更容易理解、更容易实现的目标。
- Zab的全称是Zookeeper atomic broadcast protocol,是Zookeeper内部用到的一致性协议。相比Paxos,Zab最大的特点是保证强一致性(strong consistency)。和Raft一样,Zab要求唯一Leader参与决议,Zab可以分解成discovery、sync、broadcast三个阶段:

discovery: 选举产生PL(prospective leader),PL收集Follower epoch(cepoch),根据Follower的反馈PL产生newepoch(每次选举产生新Leader的同时产生新epoch,类似Raft的term)
sync: PL补齐相比Follower多数派缺失的状态、之后各Follower再补齐相比PL缺失的状态,PL和Follower完成状态同步后PL变为正式Leader(established leader)
broadcast: Leader处理Client的写操作,并将状态变更广播至Follower,Follower多数派通过之后Leader发起将状态变更落地(deliver/commit)
- 了解完Zab的基本原理,我们再来看Zab怎样保证强一致性,Zab通过约束事务先后顺序达到强一致性,先广播的事务先commit、FIFO,Zab称之为primary order(以下简称PO)。实现PO的核心是zxid。
- Paxos、Raft、Zab和VR都是解决一致性问题的协议,Paxos协议原文倾向于理论,Raft、Zab、VR倾向于实践,一致性保证程度等的不同也导致这些协议间存在差异。
亿级规模的Elasticsearch优化实战 王卫华
- 索引优化:SSD是经济压力能承受情况下的不二选择。减少碎片也可以提高索引速度,每天进行优化还是很有必要的。在初次索引的时候,把replica设置为0,也能提高索引速度。
- 索引优化相关参数:threadpool.index.queue_size、indices.memory.index_buffer_size、index.translog.flush_threshold_ops和refresh_interval。
- 查询优化:可以使用多个集群,每个集群使用不同的routing,比如用户是一个routing维度。在实践中,这个routing非常重要。
- 索引越来越大,单个shard也很巨大,查询速度也越来越慢。这时候,是选择分索引还是更多的shards?在实践过程中,更多的shards会带来额外的索引压力,即IO 力。我们选择了分索引,比如按照每个大分类一个索引,或者主要的大城市一个索引。然后将他们进行合并查询。如:http://cluster1:9200/shanghai,beijing/_search?routing=fang;
- 线程池我们默认使用fixed,使用cached有可能控制不好。主要是比较大的分片relocation时,会导致分片自动下线,集群可能处于危险状态。
- 128G内存的机器配置一个JVM,然后是巨大的heapsize(如64G)还是配多个JVM instance,较小的 heapsize(如32G)?我的建议是后者。实际使用中,后者也能帮助我们节省不少资源,并提供不错的性能。具体请参阅 “Don’t Cross 32 GB!" (https://www.elastic.co/guide/en/elasticsearch/guide/current/heap-sizing.html#compressed_oops)
怎样读一本书V5.0 ljinkai
JVM为什么需要GC? 周明耀
- HotSpot的垃圾回收器总结:如果你想要最小化地使用内存和并行开销,请选Serial GC;如果你想要最大化应用程序的吞吐量,请选Parallel GC;如果你想要最小化GC的中断或停顿时间,请选CMS GC。
- G1 GC基本思想:G1 GC是一个压缩收集器,它基于回收最大量的垃圾原理进行设计。G1 GC利用递增、并行、独占暂停这些属性,通过拷贝方式完成压缩目标。此外,它也借助并行、多阶段并行标记这些方式来帮助减少标记、重标记、清除暂停的停顿时间,让停顿时间最小化是它的设计目标之一。
- G1 GC的垃圾回收循环组成:年轻代循环、多步骤并行标记循环、混合收集循环、Full GC;
- G1的区间设计:在G1中,堆被平均分成若干个大小相等的区域(Region)。每个Region都有一个关联的Remembered Set(简称RS),RS的数据结构是Hash表,里面的数据是Card Table (堆中每512byte映射在card table 1byte)。简单的说RS里面存在的是Region中存活对象的指针。当Region中数据发生变化时,首先反映到Card Table中的一个或多个Card上,RS通过扫描内部的Card Table得知Region中内存使用情况和存活对象。在使用Region过程中,如果Region被填满了,分配内存的线程会重新选择一个新的Region,空闲Region被组织到一个基于链表的数据结构(LinkedList)里面,这样可以快速找到新的Region。

让机器读懂用户--大数据中的用户画像 杨杰
- 用户画像(persona)的概念最早由交互设计之父Alan Cooper提出:“Personas are a concrete representation of target users.” 是指真实用户的虚拟代表,是建立在一系列属性数据之上的目标用户模型。随着互联网的发展,现在我们说的用户画像又包含了新的内涵——通常用户画像是根据用户人口学特征、网络浏览内容、网络社交活动和消费行为等信息而抽象出的一个标签化的用户模型。构建用户画像的核心工作,主要是利用存储在服务器上的海量日志和数据库里的大量数据进行分析和挖掘,给用户贴“标签”,而“标签”是能表示用户某一维度特征的标识。具体的标签形式可以参考下图某网站给其中一个用户打的标签。

- 用户画像的作用:精准营销、用户研究、个性服务、业务决策;
- 用户画像的内容:对于大部分互联网公司,用户画像都会包含人口属性和行为特征。人口属性主要指用户的年龄、性别、所在的省份和城市、教育程度、婚姻情况、生育情况、工作所在的行业和职业等。行为特征主要包含活跃度、忠诚度等指标。另外,电商购物网站的用户画像,一般会提取用户的网购兴趣和消费能力等指标。
- 用户画像的生产,大致可以分为以下几步:
- 用户建模,指确定提取的用户特征维度,和需要使用到的数据源。
- 数据收集,通过数据收集工具,如Flume或自己写的脚本程序,把需要使用的数据统一存放到Hadoop集群。
- 数据清理,数据清理的过程通常位于Hadoop集群,也有可能与数据收集同时进行,这一步的主要工作,是把收集到各种来源、杂乱无章的数据进行字段提取,得到关注的目标特征。
- 模型训练,有些特征可能无法直接从数据清理得到,比如用户感兴趣的内容或用户的消费水平,那么可以通过收集到的已知特征进行学习和预测。
- 属性预测,利用训练得到的模型和用户的已知特征,预测用户的未知特征。
- 数据合并,把用户通过各种数据源提取的特征进行合并,并给出一定的可信度。
- 数据分发,对于合并后的结果数据,分发到精准营销、个性化推荐、CRM等各个平台,提供数据支持。
- 应用示例之个性化推荐:很多推荐场景都会用到基于商品的协同过滤,而基于商品协同过滤的核心是一个商品相关性矩阵W,假设有n个商品,那么W就是一个n * n的矩阵,矩阵的元素wij代表商品Ii和Ij之间的相关系数。而根据用户访问和购买商品的行为特征,可以把用户表示成一个n维的特征向量U=[ i1, i2, ..., in ]。于是U * W可以看成用户对每个商品的感兴趣程度V=[ v1, v2, ..., vn ],这里v1即是用户对商品I1的感兴趣程度,v1= i1*w11 + i2*w12 + in*w1n。如果把相关系数w11, w12, ..., w1n 看成要求的变量,那么就可以用LR模型,代入训练集用户的行为向量U,进行求解。这样一个初步的LR模型就训练出来了,效果和基于商品的协同过滤类似。
推荐系统本质与网易严选实践 沈燕
- 推荐系统作用本质:有资料称亚马逊的推荐系统带来的GMV占其全站总量的20%-30%;推荐的本质就是提升用户体验,为此它们最主要的方式就是帮助用户快速的找到它需要的产商品,其他的方式还包括给用户新颖感等。
- 推荐系统工作原理本质:所谓embedding,数学上的意义就是映射。如word2vec通过语料训练把词变成一个数百维的向量,向量的每一维没有明确的物理意义(或者说我们无法理解)。推荐系统如果可以把人很精确地映射成一个向量,把物品也映射成一个同维度同意义的向量,那么推荐就是可以按规则处理的精确的事情了。
- 电商推荐系统的特点:商品种类数巨大,不同的商品需要不同的embedding;单种商品深度不够,难以有效embedding;人对商品的兴趣大都建立在短期或者瞬时需求之上;大量耐消品的影响;用户理论上对所有商品都会有兴趣。基于以上的原因,在电商领域难以找到完美的embedding方式来实现推荐。其实我们在看各大电商的个性化推荐时,无论宣称背后用怎样复杂的模型融合,从结果看,用户近期行为的权重是非常大的,使得结果非常像itemCF推荐出来的。
网易严选推荐实践
网易严选推荐的基础模型采用的是CTR模型,基于LR(逻辑回归)。
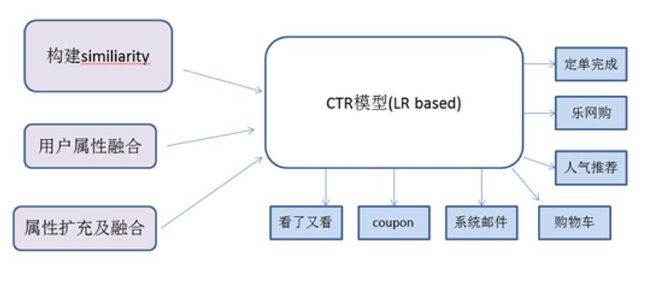
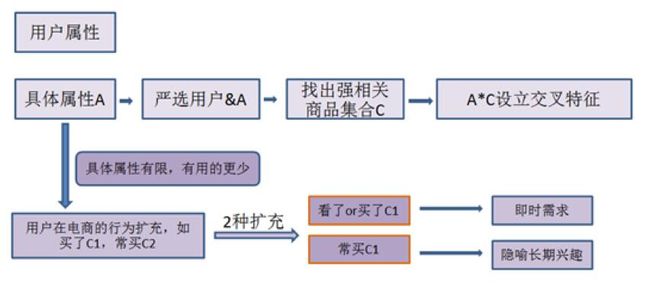
在核心的特征工程方面,网易严选推荐团队将用户的具体属性(性别、收入水平、地域等)、用户在网易严选的行为属性(短期,长期)、及时间上下文(季节、上次购买时间间隔等)作为属性空间,从1层迪卡尔积开始往上构造N层迪卡尔积形成复杂属性空间P,挖掘属性空间与商品的相关,对有明显相关(正相关或负相关)的(属性、物品)对构造特征。
用户属性空间

具体属性应用

行为属性作为抽象属性与具体属性置以相同的地位
二阶属性(属性的2重迪卡尔积)

从结果来看,这一套特征工程方法可以挖出比较全的特征集,在鲁棒性与效果上都有不错的效果,自上线以来各项指标均在稳步提升。
深入探索Java 8 Lambda表达式 Richard Warburton/Raoul Urma/Mario Fusco/段建华
- 为什么匿名内部类不好?编译器会为每一个匿名内部类创建一个类文件,而类在使用之前需要加载类文件并进行验证,这个过程则会影响应用的启动性能,另外类文件的加载很有可能是一个耗时的操作,这其中包含了磁盘IO和解压JAR文件。最重要的,一旦Lambda表达式使用了匿名内部类实现,就会限制了后续Lambda表达式实现的更改,降低了其随着JVM改进而改进的能力。
- Lambdas表达式和invokedynamic:将Lambda表达式转化成字节码只需要如下两步:1.生成一个invokedynamic调用点,也叫做Lambda工厂,当调用时返回一个Lambda表达式转化成的函数式接口实例;2.将Lambda表达式的方法体转换成方法供invokedynamic指令调用。需要注意的是编译器对于Lambda表达式的翻译策略并非固定的,因为这样invokedynamic可以使编译器在后期使用不同的翻译实现策略。
- 性能分析:Lambda工厂的预热准备需要消耗时间,但Lambda工厂方式也会比匿名内部类加载要快,最高可达100倍;如果是不进行捕获变量,这一步会自动进行优化,避免在基于Lambda工厂实现下额外创建对象;对于真实方法的调用,匿名内部类和Lambda表达式执行的操作相同,没有性能上的差别;
- 对于大多数情况来说,Lambda表达式要比匿名内部类性能更优。然而现状并非完美,基于测量驱动优化,我们仍然有很大的提升空间。
红黑树 Hosee
- 先来看下算法导论对R-B Tree的介绍:
红黑树,一种二叉查找树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。
通过对任何一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近平衡的。
- 二叉查找树,也称有序二叉树(ordered binary tree),是指一棵空树或者具有下列性质的二叉树:
1.若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2.若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3.任意节点的左、右子树也分别为二叉查找树。
4.没有键值相等的节点(no duplicate nodes)。
- 红黑树虽然本质上是一棵二叉查找树,但它在二叉查找树的基础上增加了着色和相关的性质使得红黑树相对平衡,从而保证了红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。但它是如何保证一棵n个结点的红黑树的高度始终保持在logn的呢?这就引出了红黑树的5个性质:
1.每个结点要么是红的要么是黑的。
2.根结点是黑的。
3.每个叶结点(叶结点即指树尾端NIL指针或NULL结点)都是黑的。
4.如果一个结点是红的,那么它的两个儿子都是黑的。
5.对于任意结点而言,其到叶结点树尾端NIL指针的每条路径都包含相同数目的黑结点。

- 当在对红黑树进行插入和删除等操作时,对树做了修改可能会破坏红黑树的性质。为了继续保持红黑树的性质,可以通过对结点进行重新着色,以及对树进行相关的旋转操作,即通过修改树中某些结点的颜色及指针结构,来达到对红黑树进行插入或删除结点等操作后继续保持它的性质或平衡的目的。
- 红黑树的插入:首先,将红黑树当作一颗二叉查找树,将节点插入;然后,将节点着色为红色;最后,通过旋转和重新着色等方法来修正该树,使之重新成为一颗红黑树。
- 红黑树与AVL树的区别:红黑树旋转操作非常局部化,而且次数极少(插入最多两次旋转,删除最多三次旋转),而改变颜色的操作不会影响到用户对树的query操作(即不要lock),另外很多树,如AVL树,2-3树,2-4树都可以转化成红黑树,红黑树能达到O(logn)高度,但是不像AVL树那样严格要求左右子树高度差必需相差不超过1。可以说RB树是目前为止高度要求最灵活的准平衡BST。准平衡是相对完全二叉树来说的,AVL树(比如Fibonacci树)也不是完美平衡的。
业界难题-“跨库分页”的四种方案 58沈剑
方法一:全局视野法
- 将order by time offset X limit Y,改写成order by time offset 0 limit X+Y
- 服务层对得到的N*(X+Y)条数据进行内存排序,内存排序后再取偏移量X后的Y条记录这种方法随着翻页的进行,性能越来越低。
方法二:业务折衷法-禁止跳页查询
- 用正常的方法取得第一页数据,并得到第一页记录的time_max
- 每次翻页,将order by time offset X limit Y,改写成order by time where time>$time_max limit Y 以保证每次只返回一页数据,性能为常量。
方法三:业务折衷法-允许模糊数据
将order by time offset X limit Y,改写成order by time offset X/N limit Y/N
方法四:二次查询法
- 将order by time offset X limit Y,改写成order by time offset X/N limit Y
- 找到最小值time_min
- between二次查询,order by time between $time_min and $time_i_max
- 设置虚拟time_min,找到time_min在各个分库的offset,从而得到time_min在全局的offset
- 得到了time_min在全局的offset,自然得到了全局的offset X limit Y
从GITLAB误删除数据库想到的 陈皓
- 事件回顾:Gitlab某员工在做负载均衡工作时需要解决突发情况,误将删除命令敲到生产环境的窗口上导致线上数据库被删除,然后视图通过多种备份机制都无法恢复,最终只能从6小时前的数据库中拷贝回来,导致在这6个小时期间的数据丢失;
- 人肉运维:一个公司的运维能力的强弱和你上线上环境敲命令是有关的,你越是喜欢上线敲命令你的运维能力就越弱,越是通过自动化来处理问题,你的运维能力就越强。
- 数据丢失有各种各样的情况,不单单只是人员的误操作,比如,掉电、磁盘损坏、中病毒等等,在这些情况下,你设计的那些想流程、规则、人肉检查、权限系统、checklist等等统统都不管用了,这个时候,你觉得应该怎么做呢?是的,你会发现,你不得不用更好的技术去设计出一个高可用的系统!别无它法。
- 关于备份:如果你要让你的备份系统随时都可以用,那么你就要让它随时都Live着,而随时都Live着的多结点系统,基本上就是一个分布式的高可用的系统。
- 非技术方面:故障反思(5 whys分析)、工程师文化(如果你是一个技术公司,你就会更多的相信技术而不是管理)、事件公开(公开所有的细节,会让大众少很多猜测的空间,有利于抵制流言和黑公关,同时,还会赢得大众的理解和支持。);
AWS 的 S3 故障回顾和思考 陈皓
- 故障原因:AWS某员工在修复账务系统问题,需要移除某些子系统时有一条命令搞错了,移除了大量S3的控制系统,包括对象索引服务和位置服务系统。而这两个系统重启花费了非常长时间(由于该系统非常稳定,以及很长时间没有重启过,而数据量级却一直在增长),最终导致服务挂了4个小时;
- AWS后续改进措施:改进运维操作工具(让删除服务这个操作变慢一些、任何服务在运行时都应该有一个最小资源数、Review所有和其它的运维工具);改进恢复过程(分解现有厚重的重要服务成更小的单元、今年内完成对 Index 索引服务的分区计划);
- 一个系统的高可用的因素很多,不仅仅只是系统架构,更重要的是——高可用运维。对于高可用的运维,平时的故障演习是很重要的。
关于高可用的系统 陈皓
- 理解高可用系统:要做到数据不丢,就必需要持久化;要做到服务高可用,就必需要有备用(复本),无论是应用结点还是数据结点;要做到复制,就会有数据一致性的问题;我们不可能做到100%的高可用,也就是说,我们能做到几个9个的SLA;
- 高可用系统的技术解决方案:下图基本上来说是目前高可用系统中能看得到的所有的解决方案的基础了。M/S、MM实现起来不难,但是会有很多问题,2PC的问题就是性能不行,而Paxos的问题就是太复杂,实现难度太大。

- 高可用技术方案的示例:MySQL的高可用的方案的SLA(下图下面红色的标识表示了这个方案有几个9):
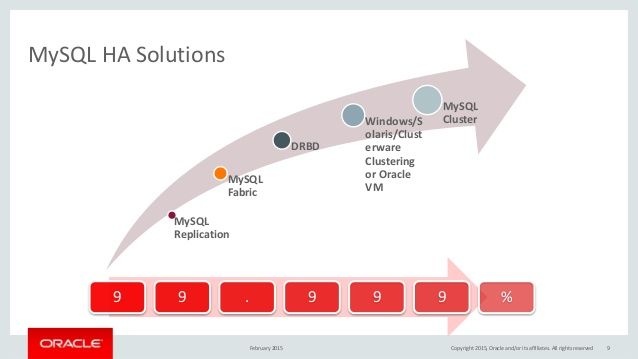
1.MySQL Repleaction就是传统的异步数据同步或是半同步Semi-Sync这个方式本质上不到2个9;
2.MySQL Fabric简单来说就是数据分片下的M/S的读写分离模式。这个方案的的可用性可以达到99%;
3.DRBD通过底层的磁盘同步技术来解决数据同步的问题,就是RAID 1——把两台以上的主机的硬盘镜像成一个。这个方案不到3个9;
4.Solaris Clustering/Oracle VM ,这个机制监控了包括硬件、操作系统、网络和数据库。这个方案一般会伴随着节点间的“心跳机制”,
而且还会动用到SAN(Storage Area Network)或是本地的分布式存储系统,还会动用虚拟化技术来做虚拟机的迁移以降低宕机时间的概率。这个解决方案完全就是一个“全栈式的解决方案”。这个方案接近4个9;
5.MySQL Cluster是官方的一个开源方案,其把MySQL的集群分成SQL Node 和Data Node,
Data Node是一个自动化sharing和复制的集群NDB,为了更高的可用性,MySQL Cluster采用了“完全同步”的数据复制的机制来冗余数据结点。这个方案接近5个9;
- 影响高可用的因素:无计划的宕机原因(系统级的故障、数据和中介的故障、自然灾害、人为破坏等);有计划的宕机原因(日常任务、运维相关、升级相关);
- 要干出高可用的系统,其中包括但不限于:软件的设计、编码、测试、上线和软件配置管理的水平;工程师的人员技能水平;运维的管理和技术水平;数据中心的运营管理水平;依赖于第三方服务的管理水平;
- 深层交的东西则是——对工程这门科学的尊重:对待技术的态度、一个公司的工程文化、领导者对工程的尊重;
专访RocketMQ联合创始人:项目思路、技术细节和未来规划 王小瑞/冯嘉
- RocketMQ的由来:第一代,推模式,数据存储采用关系型数据库,典型代表包括Notify、Napoli;第二代,拉模式,自研的专有消息存储,典型代表MetaQ;第三代,以拉模式为主,兼有推模式的高性能、低延迟消息引擎RocketMQ,在二代功能特性的基础上,为电商金融领域添加了可靠重试、基于文件存储的分布式事务等特性,并做了大量优化。
- RocketMQ的技术概览:在我们看来,它最大的创新点在于能够通过精巧的横向、纵向扩展,不断满足与日俱增的海量消息在高吞吐、高可靠、低延迟方面的要求。目前RocketMQ主要由NameServer、Broker、Producer以及Consumer四部分构成,所有的集群都具有水平扩展能力,如下图所示:

- 与其他消息中间件比较:RabbitMQ是AMQP规范的参考实现,AMQP是一个线路层协议,面面俱到,很系统,也稍显复杂;ActiveMQ是JMS规范的参考实现,JMS虽说是一个API级别的协议,但其内部还是定义了一些实现约束,不过缺少多语言支撑;而Kafka最初被设计用来做日志处理,是一个不折不扣的大数据通道,追求高吞吐,存在丢消息的可能;RocketMQ天生为金融互联网领域而生,追求高可靠、高可用、高并发、低延迟,是一个阿里巴巴由内而外成功孕育的典范。

- 三项技术发力点:消息的顺序(全局保序)、消息的去重(目前的版本是不支持去重的,建议用户通过外置全局存储自己做判重处理,后续版本内置解决方案)、分布式的挑战(基于Zab一致性协议,利用分布式锁和通知机制保障多副本数据的一致性);
- 新一代RocketMQ:期望构建一套厂商无关的集线路层、API层于一体的规范,这也是第四代消息引擎最大的亮点。
分布式事务原理与实践 沈询
- 事务的四大特性分别是:原子型、一致性、隔离性和持久性。
- 事务单元是通过Begin-Traction,然后Commit(Begin-Traction、Commit和Rollback之间所有针对数据的写入、读取的操作都应该添加同步访问),Begin和Commit之间就是一个同步的事务单元。
- Two Phase Lock(2PL)是数据库中非常重要的一个概念。数据库操作Insert、Update、Delete都是先读再写的操作,例如Insert操作是先读取数据,读取之后判读数据是否存在,如果不存在,则写入该数据,如果数据存在,则返回错误。
- 处理事务的常见方法有排队法、排他锁、读写锁、MVCC等方式。事务处理中最重要也是最简单的方案是排队法,单线程地处理一堆数据;有些场景不适合用单线程操作,可以利用排他锁的方式来快速隔离并发读写事务;读写锁的核心是在多次读的操作中,同时允许多个读者来访问共享资源,提高并发性;MVCC本质是Copy On Write,也就是每次写都是以重新开始一个新的版本的方式写入数据,因此,数据库中也就包含了之前的所有版本,在数据读的过程中,先申请一个版本号,如果该版本号小于正在写入的版本号,则数据一定可以查询到,无需等到新版本完全写完即可返回查询结果。
- 事务的调优原则:尽可能减少锁的覆盖范围、增加锁上可并行的线程数、选择正确锁类型(比如悲观锁适合并发争抢比较严重的场景,乐观锁适合并发争抢不太严重的场景);
对比了解Grafana与Kibana的关键差异 Asaf Yigal/冬雨
- Kibana是一个分析和可视化平台,它可以让你浏览、可视化存储在Elasticsearch集群上排名靠前的日志数据,并构建仪表盘。你可以执行深入的数据分析并以多种图表、表格和地图方式可视化这些数据。Kibana的仪表盘非常简单易用,任何人都可以使用它,甚至IT技能和知识很少的业务人员也可以使用。
- Grafana是一个开源仪表盘工具,它可用于Graphite、InfluxDB与 OpenTSDB一起使用。最新的版本还可以用于其他的数据源,比如Elasticsearch。它包含一个独一无二的Graphite目标解析器,从而可以简化度量和函数的编辑。Grafana快速的客户端渲染默认使用的是 Flot ,即使很长的时间范围也可应对。
- 日志与度量:Grafana专注于根据CPU和IO利用率之类的特定指标提供时间序列图表,而Kibana能创建一个复杂的日志分析仪表盘;
- 基于角色的访问:默认情况下Kibana的仪表盘是公开的,Grafana内置的RBA允许你维护用户和团队访问仪表盘的权限;
- 仪表盘灵活性:虽然Kibana有大量内置的图表类型,但它们之上的控制仍是最初的限制,Grafana包括更多的选择,可以更灵活地浏览和使用图表;
- 数据源的集成:Grafana支持许多不同的存储后端,它是针对数据源所具备的特性和能力特别定制的,而Kibana原生集成进了ELK栈,这使安装极为简单,对用户非常友好;
- 开源社区:ELK仍保持着快速的增长,并有潜力在不久的将来保持领先;
- 共同协作:Kibana和Grafana都是强大的可视化工具。然而,Grafana和InfluxDB组合是用于度量数据的,反之,Kibana是流行的ELK栈的一部分,它可以更为灵活地浏览日志数据。这两个平台都是好的选择,甚至有时还可以互补。首先,用Kibana去分析你的日志。然后,把数据导入到Grafana作为可视化层。这些的前提是需要同一个Elasticsearch库。
百度宣布将在Kubernetes上运行其深度学习平台PaddlePaddle 木环
- 本月初,Kubernetes在其官网上宣布了百度的PaddlePaddle成为目前唯一官方支持Kubernetes的深度学习框架。PaddlePaddle是百度于2016年9月开源的一款深度学习平台,具有易用,高效,灵活和可伸缩等特点,为百度内部多项产品提供深度学习算法支持。
- Kubernetes 把很多分散的物理计算资源抽象成一个巨大的资源池,它利用这些资源来帮助用户执行计算任务。对于用户来说,操作一个分散的集群资源可以像使用一台计算机一样简单。对于这个项目,Kubernetes 主要负责将学习任务分配到集群的物理节点上进行运算;如果遇到任务失败的情况,Kubernetes 会自动重启任务。
- 能不能将框架的作业和任务模式,同“容器”这个全新的部署概念匹配起来,才是现阶段最重要的。毕竟,如果框架连正常运行起来都很困难,再好的资源利用率提升机制也没有用武之地。在这一点上,Kubernetes应该说是现有的容器管理项目中做的最好的。
- 容器化实施深度学习的优点:轻量级、更高的资源利用率、基于容器的设计模式、高度的可扩展性和容错能力;
建设DevOps统一运维监控平台,先从日志监控说起 王海龙
- DevOps浪潮下带来的监控挑战:监控源的多样化挑战、海量数据的分析处理挑战、软硬件数据资源的管理分析挑战;
- 一个好的统一监控平台,应当具备:高度抽象模型,扩展监控指标、多种监控视图、强大的数据加工能力、多种数据采集技术、多种报警机制、全路径问题跟踪;
- 统一监控平台由七大角色构成:监控源、数据采集、数据存储、数据分析、数据展现、预警中心、CMDB(企业软硬件资产管理)。

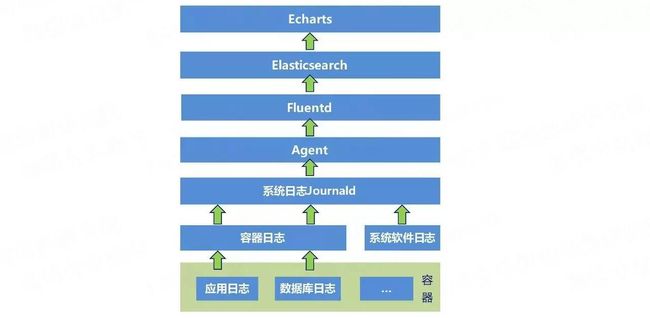
- 日志监控的技术栈

- ELK-日志监控经典方案

- 微服务+容器云背景下的日志监控实践:跑在容器中的应用、数据库等软件都会把日志落到容器日志(docker日志),然后在docker系统服务上进行配置,将docker容器日志输出到系统日志服务journald中。这样,容器中的日志就统一到了系统日志中。针对于运行在虚拟机上的系统软件,如kubernetes、etcd等,配置成系统服务service,使用systemd管理,自然也就做到了将其日志输入到journald中。再往上就比较简单了,自实现一个agent,读取journald中的日志,通过tcp协议发送到fluentd中,考虑到现在的日志量并不会太大,所以没有再使用kafka进行缓冲,而是直接经过fluentd的拦截和过滤,将日志发送到Elasticsearch中。
- 如何选择适合自己的日志监控方案:工具能力是否满足、性能对比、看技术能力是否能cover住、监控平台日志量评估;
函数式编程入门教程 阮一峰
- 函数式编程的起源,是一门叫做范畴论(Category Theory)的数学分支。理解函数式编程的关键,就是理解范畴论。它是一门很复杂的数学,认为世界上所有的概念体系,都可以抽象成一个个的"范畴"(category)。
- 范畴就是使用箭头连接的物体。也就是说,彼此之间存在某种关系的概念、事物、对象等等,都构成"范畴"。箭头表示范畴成员之间的关系,正式的名称叫做"态射"(morphism)。范畴论认为,同一个范畴的所有成员,就是不同状态的"变形"(transformation)。通过"态射",一个成员可以变形成另一个成员。
- 我们可以把"范畴"想象成是一个容器,里面包含两样东西:值(value)和值的变形关系,也就是函数。
- 本质上,函数式编程只是范畴论的运算方法,跟数理逻辑、微积分、行列式是同一类东西,都是数学方法,只是碰巧它能用来写程序。
- 如果一个值要经过多个函数,才能变成另外一个值,就可以把所有中间步骤合并成一个函数,这叫做"函数的合成"(compose)。
- f(x)和g(x)合成为f(g(x)),有一个隐藏的前提,就是f和g都只能接受一个参数。如果可以接受多个参数就需要函数柯里化了。所谓"柯里化",就是把一个多参数的函数,转化为单参数函数。
- 函子是函数式编程里面最重要的数据类型,也是基本的运算单位和功能单位。它首先是一种范畴,也就是说,是一个容器,包含了值和变形关系。比较特殊的是,它的变形关系可以依次作用于每一个值,将当前容器变形成另一个容器。
- 学习函数式编程,实际上就是学习函子的各种运算。
