目录
- 概述
- 继承关系
2.1. Executor
2.2. ExecutorService
2.3. AbstractExecutorService - 生命周期
- 如何使用
4.1. 核心配置
4.2. 常用线程池 - 源码解析
5.1. 核心组件
5.2. 线程池状态记录
5.3. 执行任务
5.4. 获取线程池运行情况
5.5. 关闭线程池
1. 概述
为什么要使用线程池?
线程的创建和销毁涉及到系统调用等等,是比较消耗 CPU 资源的。如果线程本身执行的任务时间短,创建和销毁线程所耗费的资源就会占很大比例,对系统起源和运行时间上是一个瓶颈。
这时候线程池就派上了用场,作为线程的容器,实现对线程的复用。如果线程长时间没有任务可以执行,也是很消耗系统资源的,所以也有对线程的销毁机制。
有了这个中心化的容器,我们不需要关心线程的创建和销毁,由线程池进行合理地调度,还可以对线程的执行情况进行监控。
线程池的优势可以归纳如下:
- 降低资源消耗,线程频繁的创建和销毁的消耗可以降低。
- 提高响应速度,两个线程如果被分配到不同的 CPU 内核上运行,任务可以真实的并发完成。
- 提供线程的可管理性,比如对线程的执行任务过程的监控。
ThreadPoolExecutor 是大神 Doug Lea 在 java.util.concurrent 包提供的线程池实现,很好地满足了各个应用场景对于线程池的需求。
这里对 ThreadPoolExecutor 的使用和原理进行详细的分析。
2. 继承关系
首先了解一下 ThreadPoolExecutor 的继承关系。如下:

2.1. Executor
执行器,只声明了一个execute() 方法用来执行 Runnable 任务。
public interface Executor {
void execute(Runnable command);
}
执行器子类的实现,可以对任务的执行制定各种策略,比如:
- 同步还是异步?
- 直接执行还是延迟执行?
ThreadPoolExecutor 作为它的实现类,实现了具体的执行策略。比如在内部有工作线程队列和任务队列,实现了多线程并发执行任务。
2.2. ExecutorService
增加了对执行器生命周期的管理,并扩展对 Callable 任务的支持,返回 Future 来提供给调用者。
涉及到的生命周期的处理方法有:
- shutdown(),关闭。
- shutdownNow(),马上关闭。
- awaitTermination(),阻塞等待结束。
- isTerminated(),判断是否结束。
- isShutdown(),判断是否关闭。
可以看到主要是对执行器对一些关闭处理。ThreadPoolExecutor 实现了这些方法,比如使用 shutdown() 来关闭线程池。但是线程池不会马上关闭,所以还可以继续调用 awaitTermination() 方法来阻塞等待线程池正式关闭。
2.3. AbstractExecutorService
抽象类,配置了多任务执行的工具方法。
对 ExecutorService.submit() 提供默认实现,可供子类直接使用。
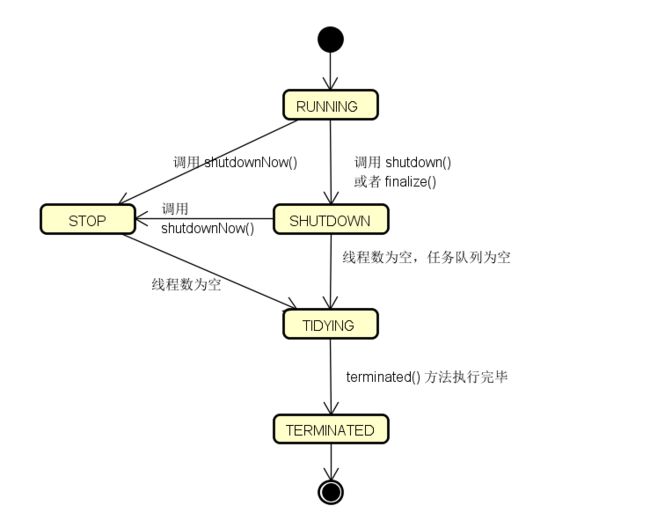
3. 生命周期
这里了解一下线程池的生命周期,状态有这 5 种:
- RUNNING,运行状态。接受新的任务,并且把任务入列,线程会从队列中取出任务并执行。
- SHUTDOWN,关闭状态。当线程池在 RUNNING 的情况下,调用
shutdown()或者finalize()方法会进入到 SHUTDOWN 状态。该阶段无法接受新任务,但会继续执行完队列中的任务。如果这个期间线程池没有线程,任务队列中还有任务,会创建新的线程把任务执行完。 - STOP,停止状态。当线程池处于 RUNNING 或者 SHUTDOWN 的情况下,调用
shutdownNow()方法会进入 STOP 状态。不接受新任务,不会继续执行队列中的任务,并且会 对线程池中正在执行的线程设置中断标记。如果还有任务未执行完成,会把未完成的任务返回给调用方。 - TIDYING,整理状态。当所有任务结束,工作者数量也为 0,会进入该状态并且调用
terminated()钩子方法。这个钩子方法由子类实现,用来执行进行最后的关闭操作。 - TERMINATED,终止状态。
terminated()钩子方法执行完毕后进入。
这个生命周期如下:
4. 如何使用
这里介绍线程池的一些常规配置和使用。
线程池的构造函数如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler);
4.1. 核心配置
corePoolSize,核心线程数。创建后不会关闭的线程数量(特殊情况:设置了
allowCoreThreadTimeout后,空闲时间超时后还是会关闭)。执行任务时,没有达到核心线程数的话,是会直接创建新的线程。maximumPoolSize,最大线程数量。当核心线程数和任务队列也都满了,这个配置开始生效。如果当前有效工作线程数量小于最大线程数量,会再创建新的线程。
keepAliveTime 和 unit,线程池中线程的空闲时间限制。也称为保活时间。TimeUnit 用来指定
keepAliveTime的时间单位。workQueue,任务队列,为阻塞队列 BlockingQueue 的实现。线程池会先满足 corePoolSize 的限制,在核心线程数满了后,将任务加入队列。但队列也满了后,线程数小于 maximumPoolSize ,线程池继续创建线程。
ThreadFactory,线程工厂。用来创建新线程,可以用来配置线程的命名、是否是守护线程、优先级等等。
handler,拒绝处理器,为 RejectedExecutionHandler 的实现类。当任务队列满负荷,已经达到最大线程数,把新加入的任务交给这个 handler 进行处理。线程池默认使用 AbortPolicy 策略,直接抛出异常。
这里再补充一个配置:
- allowCoreThreadTimeout,核心线程的空闲时间也要进行超时限制,也就是
keepAliveTime的限制。如果配置为 true 后,所有的线程空闲时间超时后,都会进行线程退出操作。
4.2. 常用线程池
Executors 工具类提供了多种比较常规的线程池配置,具体使用哪一种要看实际的业务场景。主要有这几种:
- FixedThreadPool,固定线程数线程池。
- SingleThreadPool,单线程线程池。
- CachedThreadPool,缓存线程池。
- ScheduledThreadPool,定时任务线程池。
4.2.1. 固定线程数线程池
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory);
}
配置如下:
- 核心线程数和最大线程数相同。
- 超时时间为 0。
- 使用无界任务队列。
线程一旦创建会一直存在于线程池中,直到达到核心线程数。如果中途有某个线程发生异常退出了,线程池会马上新起一个线程补上,直到使用 shutdown() 关闭线程池。
因为任务队列是无界队列,在核心线程数满了后,新任务会不断地加入到队列中,不存在任务队列满了的情况。我们知道 maximumPoolSize 生效的前提是任务队列满负荷,所以在该线程池中,maximumPoolSize 不生效。
超时时间设置 0,如果设置 allowCoreThreadTimeout 的话会对核心线程生效。否则的话这个配置也没有效果。
适用于每个时间段执行的任务数相对稳定,数量不大,执行时间又比较长的场景。
使用该线程池的风险在于任务队列没有指定长度,在短时间高密度任务同时并发执行的情况下,可能会发生内存溢出。
4.2.2. 单一线程数线程池
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue(),
threadFactory));
}
配置如下:
- 核心线程数和最大线程数都为 1。
- 超时时间为 0。
- 使用无界队列。
和固定线程数相似,只是线程数为固定为 1。
和固定线程池不一样,这个线程池不允许重新配置 maximumPoolSize。为了满足这个需求,内部做了一个代理线程池 FinalizableDelegatedExecutorService,不再提供 setMaxmiumPoolSize 等方法来重新配置线程池。
所有任务都顺序执行。适合那些任务执行时间短,实时性要求又不高的场景。
和固定线程数线程池一样,使用无界队列,有内存溢出风险。
4.2.3. 缓存线程数线程池
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue(),
threadFactory);
}
配置如下:
- 核心线程数为0,最大线程数不做限制。
- 超时时间为 60 秒。
- 使用有界队列 SynchronousQueue,该队列没有实际容量,只用来做生产者和消费者之间的任务传递。
在每个任务到达,没有线程空闲的话,会再创建一个。
线程执行完任务后,没有新任务到达,会有 60s 的保活时间,这段时间没有新任务到达后线程就会直接关闭。
适用于那些任务量大,然后耗时时间比较少的场景。比如 OkHttp 的线程池的配置就和缓存线程数线程池的配置一样。
没有使用无界队列,但是不限制最大线程数量,如果短时间高并发任务执行的话,也是有内存溢出风险。
4.2.4. 定时任务线程池
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
直接创建一个 ScheduledThreadPoolExecutor。
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
配置如下:
- 核心线程数有设置,但最大线程数不做限制。
- 使用了一个可延迟获取任务的无界队列 DelayedWorkQueue,可以实现定期执行任务的特点。
所以可以用来执行定时任务,或者有固定周期执行的任务。
5. 源码解析
5.1. 核心组件
这里分析一下 ThreadPoolExecutor 内部的主要部分。正是通过这些组件的结构组合和行为交互,实现了线程池的基本功能。
5.1.1. Thread
线程实现类。JVM 的线程和操作系统的线程是对应的。Thread很多方法最终都会执行到 native 方法上。
Thread 非常庞大和复杂,我们这次主要分析它的生命周期,以及正确关闭线程的方式(中断)。
5.1.1.1. 生命周期
一个线程又这几个状态:
-
NEW,新创建。 -
RUNNALE,可运行。 -
BLOCKED,被阻塞。 -
WAITING,等待。 -
TIMED_WAITING,计时等待。 -
TERMINATED,被终止。
完整的线程状态机如下:

5.1.1.2. 优先级
线程的优先级有 1-10,默认优先级是 5。有这几种类型:
- MIN_PRIORITY = 1,最小优先级。
- NORM_PRIORITY = 5,普通优先级。
- MAX_PRIORITY = 10,最高优先级。
线程优先级体现的是 竞争到 CPU 资源的概率,高优先级概率高。所以,并不能百分白保证高优先级的线程一定优先执行。
在线程初始化的时候就会进行优先级设置,见 Thread.init();
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
...
Thread parent = currentThread();
...
this.group = g;
this.daemon = parent.isDaemon();
this.priority = parent.getPriority();
...
setPriority(priority);
...
}
也可以直接调用 Thread.setPriority() 方法设置:
public final void setPriority(int newPriority) {
ThreadGroup g;
checkAccess();
if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) {
throw new IllegalArgumentException();
}
if((g = getThreadGroup()) != null) {
if (newPriority > g.getMaxPriority()) {
newPriority = g.getMaxPriority();
}
setPriority0(priority = newPriority);
}
}
5.1.1.3. 线程中断
中断是退出线程的一种方式。也是最合理的退出方式。
中断首先要设置中断标记,比如调用 Thread.interrupt() 方法后,中断标记会设置为 true。
- 线程被阻塞,比如调用了
object.wait(),thread.join(),thread.sleep(),中断标记会被清除,然后抛出 InterruptedException。 - 线程没有被阻塞,中断标志会被设置为 true。这时候就需要业务方去处理了。如果内部有个循环还在进行,需要去判断这个标志进行退出。
举个 ReentrantLock 的例子。
我们知道,ReentrantLock 内部是使用 AQS 来实现加锁的。然后有个方法 lockInterruptibly(),从字面上理解,就是在加锁的状态下,能够响应线程中断。它是如何实现的?见 AbstractQueuedSynchronizer.acquireInterruptibly:
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
可以看到,这里识别到中断标记后直接抛出 InterruptedException 异常。
Thread 中两种方法来判断是否中断:
-
interrupted()。 -
isInterrupted()。
这两种方法的区别在于 interruped 会重置中断标记为 false,有清除中断标记的功能。
而 isInterrpted 仅仅只是用来测试线程是否被终止,不会清除中断标记。
比如我们上面提到的 AbstractQueuedSynchronizer.acquireInterruptibly 的方法中,调用 interrupted() 后同时清空了中断标记。
5.1.2. Worker
Worker 是ThreadPoolExecutor的内部类,每个 Worker 和一个工作线程绑定,提供任务执行方法和对执行状态的监控。
执行状态的监控使用了不可重入锁,后续会进行分析。
5.1.2.1. 成员变量
看 Worker 的成员变量,主要有三个:
- thread, 和
Worker绑定的工作线程。 - firstTask ,线程要执行的第一个任务,在
Worker.runWorker()中会调用,可能为 null。为 null 的话线程会从任务队列取出新任务。 - completedTasks ,该线程一共执行了多少任务。
我们可以在 ThreadPoolExecutor.getCompletedTaskCount 中看到 completedTasks 的使用:
public long getCompletedTaskCount() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
long n = completedTaskCount;
for (Worker w : workers)
n += w.completedTasks;
return n;
} finally {
mainLock.unlock();
}
}
5.1.2.2. 不可重入锁
Worker 使用 AQS 的方法实现了简单的锁。任务执行过程中,执行前会去获取锁,执行后会去释放锁。这里的锁可以用来表示线程是否在执行任务。执行任务中的 Worker 是不可以被中断的,这也是记录正在执行的任务的线程的意义。
看下 Worker 的锁操作方法:
-
lock(),上锁。 -
tryLock(),尝试获取锁。 -
unlock(),解锁。 -
isLocked(),判断是否上锁。
和 ReentrantLock 是不是很相似?为什么不直接使用?
那是因为 不需要 ReentrantLock 的可重入特性。
为了理解这个点,我们看什么时候会去中断线程。中断意味着退出线程, ThreadPoolExecutor 关闭线程的方法:
shutdown()tryTerminate()
还有修改配置的方法:
allowCoreThreadTimeOut()setCorePoolSize()setKeepAliveTime()setMaximumPoolSize()
这些方法都有一个共同点,会触发 ThreadPoolExecutor.interruptIdleWorkers 方法中断空闲线程。方式就是调用 tryLock 去尝试获取锁,空闲的线程是可以获取到锁的。
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
如果我们允许可重入锁的话会发生什么?
我们正在执行的任务的线程,因为可重入的特性,可以反复获取到锁。如果这时候线程调用关闭或者配置线程池的方法,触发 interruptIdleWorkers() 方法,获取锁后,把自己给中断了,线程发生异常退出。
所以 Worker 这里实现的是不可重入锁 ,避免了上述情况的发送。
我们来对比一下 Worker 和 ReentrantLock 的对是否可重入特性的具体实现。先看 ReentrantLock.tryLock() :
public boolean tryLock() {
return sync.nonfairTryAcquire(1);
}
sync 就是 ReentrantLock 的 AbstractQueuedSynchronizer 的实现。nofairTryAcquire() 方法如下:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
getState() 的值,0 表示没有锁,0 以上表示已经被锁了。然后 ReentrantLock 会继续判断持有锁的线程是否是当前线程 current == getExclusiveOwnerThread() ,如果是的话还可以继续拿到锁,并增加 state 的值,实现了可重入的特性。
再看 Worker.tryLock() :
public boolean tryLock() { return tryAcquire(1); }
也是调用 AQS 的 tryAcquire(),这里的实现很简单:
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
可以看到没有可重入的概念。
已经持有锁的线程,到新的临界区,还是要继续阻塞等待,不能马上执行。
这样也限制了线程池中的工作线程,是不允许主动调用关闭或配置线程池的方法。
5.1.3. ThreadFactory
线程工厂,用来生产线程,定义如下:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
在 Worker 的构造函数里,使用了该类来创建新线程:
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
对新创建线程的配置:
- 设置线程名。
- 设置为守护线程(不推荐)。
- 设置线程优先级(不推荐)。
工具类 Executors 内置了一个线程工厂的默认实现 DefaultThreadFactory:
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
这样运行起来的线程会有这样的名字
pool-1-thread-1
pool-1-thread-2
pool-1-thread-3
...
可以看到这里的线程计数方式,来创建线程名时使用了一个 AtomicInteger 来实现序号递增的原子操作。
线程优先级为NORM_PRIORITY 。
5.1.4. BlockingQueue
阻塞队列,也是我们的任务队列,定义如下:
public interface BlockingQueue extends Queue {
boolean add(E e);
boolean offer(E e);
void put(E e) throws InterruptedException;
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
E take() throws InterruptedException;
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
int remainingCapacity();
boolean remove(Object o);
public boolean contains(Object o);
int drainTo(Collection c);
int drainTo(Collection c, int maxElements);
}
任务队列的使用是经典的生产者消费者模型:
- 如果队列为空,获取任务会阻塞等待,直到加入新任务。
- 如果队列不能加入新任务(比如满了),添加任务会阻塞等待,直到队列可用。
工作线程在阻塞等待新任务的时间被称为 空闲时间。
如果受到超时限制,比如非核心线程,并且 keepAliveTime 有配置,线程会调用 BlockingQueue.poll() 方法获取新任务,阻塞时间超过了 keepAliveTime 会直接返回 null。
E poll(long timeout, TimeUnit unit)
如果不受超时限制,比如核心线程,且没有设置 allowCoreThreadTimeOut = true , 会调用 BlockingQueue.take() 方法阻塞等待直到加入新任务,或者发生中断。
E take() throws InterruptedException;
阻塞队列 JDK 提供了多种阻塞队列的实现,都可以应用到线程池中。我们比较常用的有这三种:
5.1.4.1. ArrayBlockingQueue
有界队列,FIFO,内部使用数组实现。
创建时必须指定容量 capacity。它使用的数组定义如下:
final Object[] items;
内部使用了 ReentrantLock 和 Condition 来实现生成者消费者模型。
ArrayBlockingQueue.take() 方法如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
ArrayBlockingQueue.put() 方法如下:
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
ArrayBlockingQueue 读写方法都使用同一个锁 lock 来实现,所以对记录队列中任务数量的 count 不存在并发问题。
为什么没有区分读写锁,因为每次都是对整个数组操作,需要获取数组的整体状态,比如 length。
线程被唤醒的时候会检查 count 判断是否队列是否又任务,没有的话调用 notEmpty.await() 继续等待。
有任务的话调用 dequeue 获取任务。
5.1.4.2. LinkedBlockingQueue
可以是有界或无界,FIFO,内部使用链表实现。每个节点定义如下:
static class Node {
E item;
Node next;
Node(E x) { item = x; }
}
LinkedBlockingQueue.take() 方法:
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
LinkedBlockingQueue.put() 方法:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
// Note: convention in all put/take/etc is to preset local var
// holding count negative to indicate failure unless set.
int c = -1;
Node node = new Node(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
/*
* Note that count is used in wait guard even though it is
* not protected by lock. This works because count can
* only decrease at this point (all other puts are shut
* out by lock), and we (or some other waiting put) are
* signalled if it ever changes from capacity. Similarly
* for all other uses of count in other wait guards.
*/
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
也是使用 ReentrantLock 和 Condition 来完成生产者消费者模型。
和 ArrayBlockingQueue 不一样,读写分别使用了两个锁来实现 takeLock 和 putLock ,做到了读写锁的分离。
所以 count 的计数可能会被多个线程同时触发,这里使用 AtomicInteger 来实现计数的线程安全。
工具类 Executors 创建的固定线程数线程线程池 newFixedThreadPool和单线程线程池 newSingleThreadPool使用的就是无界的 LinkedBlockingQueue。
5.1.4.3. SynchronousQueue
该队列没有实际大小,capacity 始终为空,作用就是做个中转,把任务从生产者转移给消费者。
SynchronousQueue.take() 方法:
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
内部使用了 Transferer 进行任务的传输。
工具类 Executors 创建的缓存线程池 newCacheThreadPool 使用的就是该队列。
5.1.5. RejectExecutionHandler
在调用 ThreadPoolExecutor.execute() 执行新任务时,线程池已满,队列已满,或者线程池已经进入关闭阶段,会拒绝执行该任务。
然后把任务 Runnable 传递给 RejectExecutionHandler ,根据具体的拒绝策略进行处理。
看 RejectExecutionHandler 的定义:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
JDK 提供了一些实现类,实现了具体的拒绝策略。
CallerRunsPolicy ,让调用者去执行。见 CallerRunsPolicy.rejectedExecution() :
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
AbortPolicy,线程池默认使用该策略,直接抛出 RejectedExecutionException 异常。见 AbortPolicy.rejectedExecution() :
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
DiscardPolicy ,空实现,正如它的名字所言,任务被直接忽略。见 DiscardPolicy.rejectedExecution() :
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
DiscardOldestPolicy ,先抛弃线程池任务队列中尚未执行的任务,然后再尝试调用 execute 方法。如果线程池已经是 SHUTDOWN 状态,也不处理。见 DiscardOldestPolicy.rejectedExecution()
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
5.2. 线程池状态记录
平时涉及到状态机的状态记录,我们一般会直接用 Integer,有多少状态就有多少 Integer。
ThreadPoolExecutor 只用了一个 Integer,使用位记录状态,通过位运算来获取状态。这个在 C&C++ 中是很常见的。同时这些在 JDK 或者 Android 源码中经常可以见到。
特点是效率高、内存小但可读性差。
这里来理解一下 ThreadPoolExecutor 对线程状态的记录方式。
5.2.1. 记录控制量
在每个 ThreadPoolExecutor 实例都会持有一个成员 ctl:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
这个 ctl 是个 AtomicInteger ,使用 CAS 的方式来实现原子操作。初始化为 RUNNING 状态,Worker 数量为 0。
ctl 的 32 位被分割成两个部分
- workerCount,低29位。有效的工作线程的数量。
- runState,高3位。当前线程池的状态。
可以这样表示:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
|runState| workerCount |
+--------+-----------------------------------------------------------------------------------------+
所以一个 AtomicInteger 记录了两种变量,有效工作线程数量和线程池状态。
runState 有 3 位可以表示 2^3 = 8 种状态。这里使用它来表示线程池生命周期中的 5 种状态:
| 状态 | 位移计算(Int) | 高三位二进制表示 |
|---|---|---|
| RUNNING | -1 << COUNT_BITS |
111 |
| SHUTDOWN | 0 << COUNT_BITS |
000 |
| STOP | 1 << COUNT_BITS |
001 |
| TIDYING | 2 << COUNT_BITS |
010 |
| TERMINATED | 3 << COUNT_BITS |
100 |
5.2.2. 计算控制量
现在来看 ThreadPoolExecutor 是如何计算 ctl 的:
5.2.2.1. ctl 的打包与拆包
打包表示把 runState 和 workerCount 合并成 ctl 的值。拆包表示分别读出这两个值。
获取 runState 的值,使用 CAPACITY 的反做掩码对 c 进行与操作获得:
private static int runStateOf(int c) {
return c & ~CAPACITY;
}
获取 workerCount 的值,使用 CAPACITY 做掩码对 c 进行与操作获得:
private static int workerCountOf(int c) {
return c & CAPACITY;
}
合并 runState 和 workerCount 为 c ,采用或操作:
private static int ctlOf(int rs, int wc) {
return rs | wc;
}
所以我们对 ctl 的初始化 ctlOf(RUNNING, 0) ,就是初始化为 RUNNING,并且线程数为 0。
5.2.2.2. runState 的状态判断
因为运行状态在高 3 位,所以后面低 29 位不会影响判断。
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
5.2.2.3. workerCount 的增减
直接对 ctl 进行加和减操作,允许多线程并发,AtomicInteger 使用 CAS 确保线程安全。
private boolean compareAndIncrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect + 1);
}
private boolean compareAndDecrementWorkerCount(int expect) {
return ctl.compareAndSet(expect, expect - 1);
}
5.3. 执行任务
5.3.1. execute()
线程池执行任务的入口。任务都被封装在 Runnable 中。线程池 execute 方法的源码代码加上我理解后的注释如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// 获取控制量的值,控制量 ctl = runState | workerCount。
int c = ctl.get();
// 判断工作线程数是否小于核心线程数。
if (workerCountOf(c) < corePoolSize) {
// 创建核心工作线程,当前任务作为线程第一个任务,使用 corePoolSize 作为最大线程限制。
if (addWorker(command, true))
return;
// 创建核心工作线程失败,重新获取控制量
c = ctl.get();
}
// 判断线程池是否是运行中的状态,是的话将线程加入任务队列
if (isRunning(c) && workQueue.offer(command)) {
// 再次获取控制量的值,double-check
int recheck = ctl.get();
// 判断线程是否已经不是运行状态了,不是运行状态尝试从任务队列中把任务移出
if (!isRunning(recheck) && remove(command))
// 移出任务成功后,使用执行拒绝策略
reject(command);
else if (workerCountOf(recheck) == 0)
// 工作线程数量为 0,创建工作线程
addWorker(null, false);
// 线程不在运行状态或任务无法加入队列,创建新工作线程
} else if (!addWorker(command, false))
// 创建工作线程失败,执行拒绝策略
reject(command);
}
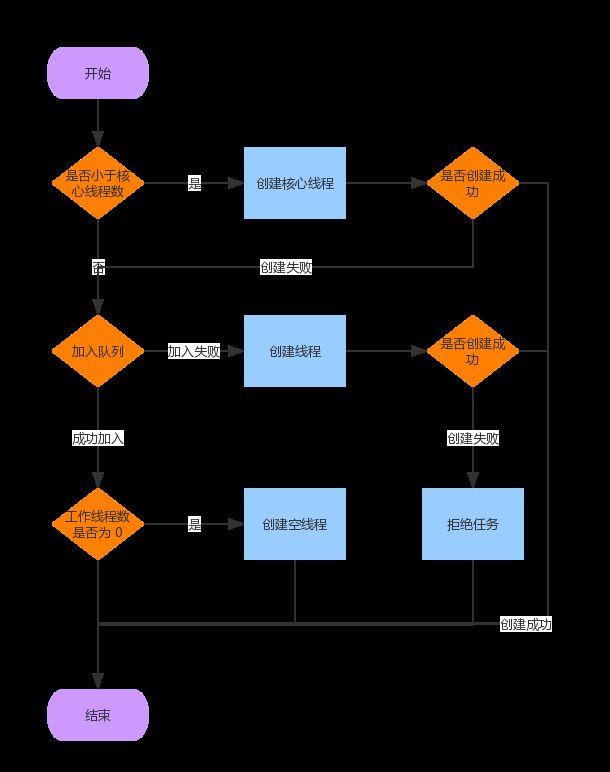
整个执行过程中,主要面临三种情况:
- 如果当前运行的线程数小于核心线程数,会尝试启动一个新的线程,这里的任务将成为线程的第一个任务。调用
addWorker会自动检查线程状态 runState 和工作线程数 workerCount 。无法创建新线程的情况下addWorker返回 false。 - 如果任务可以成功加入队列(队列满的话就无法加入了),创建一个新的线程,这里还会在读取一下状态,是 double-check ,原因在于第一获取状态到现在,线程池有可能被调用
shutdown退出 RUNNING 状态。检查状态后,如果线程被停止了,会把任务从任务队列中回滚,如果线程池没有空闲线程的话会启动新线程直接完成该任务。 - 如果无法让任务加入队列,会再尝试去加入一个新的线程。如果创建线程又失败了,比如线程池已经满了,或者已经被执行 shutdown 而退出 RUNNING 状态,会拒绝掉任务。
所以一个任务能否被线程池执行,需要考虑到多个方面的因素,比如:
- 线程池是否是运行中状态?
- 任务队列满了吗?
- 线程数量是否小于核心线程数?
- 线程数量是否达到最大线程数?
- 如果线程池非运行状态,任务已经入队列了,是否还有线程可以把任务执行完?
所以对传入线程池的任务,根据上面的各种因素综合判断,会有三种操作:
- 创建线程执行。调用
addWorker(command, true)用来创建核心线程,addWorker(command, false)用来创建普通线程,addWorker(null, false)用来创建线程。 - 加入任务队列。比如
workQueue.offer(command),将任务入列。 - 执行拒绝策略,默认采用
AbortPolicy的处理,会直接抛出RejectedExecutionException异常。
为了便于理解,假设线程池始终是在运行状态,就会得到这样的流程图:
5.3.2. addWorker()
该方法用来创建新的 Worker。内部会根据线程池的状态和工作线程数量约束来决定是否要创建。
有两个参数:
- firstTask,
Runnable,要马上执行的任务。有传入的话新创建的线程将会立即执行。否则启动的线程会直接去任务队列中取任务。 - core,boolean,是否是核心线程。用来决定线程数量使用哪种约束,如果为 true,使用 corePoolSize。如果为 false,则使用 maximumPoolSize。
addWorker 方法可以分成两个阶段来解读。第一阶段是通过自旋和 CAS 的方式,来增加工作线程数。第二部阶段则是创建并且启动工作线程。
5.3.2.1. 阶段一:增加 workerCount
第一阶段会根据线程池的状态,来判断是否可以创建或者启动新的线程。如果可以的话,会先增加 workerCount。源码和我的根据理解添加的注释如下:
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (; ; ) {
// 读取线程池状态
int c = ctl.get();
int rs = runStateOf(c);
/*
* 检查线程池状态:
* 1. 如果已经是 TIDYING 或者 TERMINATED,不创建线程,返回失败;
* 2. 如果是 SHUTDOWN 状态,首个任务为空,任务队列不为空,会继续创建线程;
* 3. 如果是 SHUTDOWN 状态,首个任务不为空,不创建线程,返回失败;
* 4. 如果是 SHUTDOWN 状态,首个任务为空,任务队列为空,不创建线程,返回失败;
*
* 所以在 SHUTDOWN 状态下,不会再创建线程首先去运行 firstTask,只会去创建线程把任务队列没执行完的任务执行完。
*/
if (rs >= SHUTDOWN && !(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false;
// 自旋加 CAS 操作增加工作线程数
for (; ; ) {
// 获取有效工作线程数
int wc = workerCountOf(c);
/*
* 检查有效工作线程数量是否达到边界:
* 1. 如果有效工作线程数大于最大工作线程数 2^29-1,不创建线程,返回失败;
* 2. 判断是否达到最大线程限制,core 为 true 的时候为核心线程数 corePoolSize,false 为最大线程数 maximumPoolSize。
*/
if (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))
return false;
/*
* 增加工作线程数,CAS 操作:
* 增加失败说明已经有其他线程修改过了,进行自旋重试;
* 增加成功,跳出自旋,进入下一个环节,去创建新线程。
*/
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
// 重新获取状态,如果运行状态改变了,从 retry 段重新开始
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
...
}
addWorker 来创建线程,在不同状态下的执行情况如下:
- **TIDYING 或 TERMINATED **。直接返回 false。
- SHUTDOWN 且传入的任务不为空,但该状态已经不能去创建新线程来执行未入队列的任务,所以直接返回 false。
- SHUTDOWN 且传入的任务为空,当前任务队列为空。首个任务为空只有
addWorker(null, false)的操作,这个执行前任务已经加入任务队列了。所以这里工作队列为空说明任务已经被其他线程执行完了。直接返回 false。 - RUNNING 或者 SHUTDOWN 状态传入的任务为空,任务队列不为空。进行工作线程的数量判断。线程数量大于线程的容量
CAPACITY,返回 false 。根据core参数来确定线程数量的约束为corePoolSize或maximumPoolSize,超过约束返回 false。
如果添加新线程,通过 CAS 加自旋的方式,增加 workerCount 的值。失败的话说明这段时间内线程池发生了新变化,还会从头再来一次。
for (;;) {
...
if (compareAndIncrementWorkerCount) {
break retry;
}
...
}
5.3.2.2. 阶段二:创建并运行新线程
第一阶段增加 workerCount,这里进入第二阶段,创建并且启动工作线程。源码和注释如下:
private boolean addWorker(Runnable firstTask, boolean core) {
...
// 标记值,表示已经启动 Worker
boolean workerStarted = false;
// 标记值,表示添加 Worker
boolean workerAdded = false;
Worker w = null;
try {
// 创建新的 worker,并且传入 firstTask
w = new Worker(firstTask);
final Thread t = w.thread;
// 判断线程是否创建成功
if (t != null) {
// 接下来要访问工作线程队列,它是 HashSet 类型,非线程安全集合需要加锁访问
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 再次读取线程池状态
int rs = runStateOf(ctl.get());
/*
* 再次判断线程池状态是否满足下面的条件之一:
* 1. 处于 RUNNING 状态
* 2. 处于 SHUTDOWN 状态,但是首任务为空。这里开线程来跑任务队列的剩余任务。
*/
if (rs < SHUTDOWN || (rs == SHUTDOWN && firstTask == null)) {
/*
* 判断新创建的线程状态,如果线程已经是启动后的状态,就无法再次启动执行任务;
* 这个是个不可恢复的异常,会抛出 IllegalThreadStateException 异常。
*/
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 加入队列
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 根据标记值得知线程已经成功创建,启动线程,更新标记 workerStarted 表示线程已经启动。
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
/*
* 有这种情况,线程没有启动
* 1. ThreadFactory 返回的线程为 null
* 2. 线程池进入了 SHUTDOWN 状态,并且传入的任务不为空。
* 这是因为这段代码执行期间线程状态发生了改变,比如 RUNNING 的时候进来,
* 准备创建核心线程的时候,线程池被关闭了,这个任务就不会执行。
* 所以即使是在创建核心线程的时候调用了 shutdown,任务也是不执行的。
* 3. ThreadFactory 返回的线程已经被启动了,抛出 IllegalThreadStateException 异常
*/
if (!workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
在调用调用 t.start() 启动线程时,会调用 Worker.run 方法。这是因为创建 Worker实例的时候,会把 Worker(也实现了 Runnable)传入 Thread。
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
所以 t.start() 后执行:
/**
* Delegates main run loop to outer runWorker.
*/
public void run() {
runWorker(this);
}
调用了ThreadPoolExecutor.runWorker() 。ThreadPoolExecutor.runWorker() 会从任务队列中取任务给工作线程执行。
如果创建线程失败了,会执行 ThreadPoolExecutor.addWorkerFailed 方法:
- 线程的异常,ThreadFactory 返回了 null 的线程,或者线程已经被启动过抛出的 IllegalThreadStateException 异常。
- 状态的变化,创建线程期间线程池被关闭了,进入关闭和终止流程。
5.3.3. addWorkerFailed()
做一些线程创建失败的善后工作。
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w);
decrementWorkerCount();
tryTerminate();
} finally {
mainLock.unlock();
}
}
从队列中移出 Worker ,调用 ThreadPoolExecutor.decrementWorkerCount() 恢复 workerCount ,这里还是使用自旋锁加 CAS 的方式:
private void decrementWorkerCount() {
do {
} while (!compareAndDecrementWorkerCount(ctl.get()));
}
然后尝试进入到 TERMINATED 状态。如果线程池正在关闭,这个 Worker 可能会停止了线程池的终止过程,所以这里尝试再调用tryTerminate() 重新尝试终止。
5.3.4. runWorker()
在 addWorker() 成功创建并启动后,会执行 ThreadPoolExecutor.runWorker() 方法。
runWorker() 会启动一个无限循环,线程不断地从任务队列中取任务执行。如果线程被中断结束或者因为异常结束后,还调会用了 processWorkerExit 处理线程退出的一些逻辑。代码如下:
final void runWorker(Worker w) {
// 获取线程
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 解锁 Worker,表示没有执行任务,空闲中可以被中断
w.unlock();
// 标记变量,记录是否因为异常终止
boolean completedAbruptly = true;
try {
/* 循环获取任务:
* 1. 有传入任务且还没有执行,先执行;
* 2. 从任务队列获取任务执行。
*/
while (task != null || (task = getTask()) != null) {
// 加锁 Worker,表示该线程已经在执行任务了。
w.lock();
/*
* 这里中断标记的处理:
* 1. STOP 状态,设置中断。
* 2. 不是 STOP 状态,先调用 interrupted 清除中断标记。
* 3. 清除前如果不是中断状态,不设置中断。清除前是中断状态,有可能在这段时间内,线程池可能调用了 shutdownNow 方法,所以再判断一下运行状态。如果这时候是 STOP 状态,并且之前设置的中断已经清了,这时候要恢复设置中断。
*/
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();
try {
// 钩子方法,执行任务前
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 运行任务,
task.run();
} catch (RuntimeException x) {
thrown = x;
throw x;
} catch (Error x) {
thrown = x;
throw x;
} catch (Throwable x) {
thrown = x;
throw new Error(x);
} finally {
// 钩子方法,执行任务后。因为放在 finally 块中,出现异常也会执行该钩子方法。
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
// 解锁 Worker,表示任务执行完
w.unlock();
}
}
// 异常终止标记位设为 false,表示执行期间没有因为异常终止
completedAbruptly = false;
} finally {
// 线程退出处理
processWorkerExit(w, completedAbruptly);
}
}
线程池提供了任务处理前和处理后的钩子方法:
beforeExecute()afterExecute()
需要监控线程池执行,或者需要在执行前或执行后做一些特殊处理的的,继承 ThreadPoolExecutor 然后实现这两个方法即可。
5.3.5. getTask()
从任务队列中取出任务,包含空闲线程的超时处理:
private Runnable getTask() {
// 标记变量,标记 poll 方法是否超时
boolean timedOut = false;
for (; ; ) {
// 读取线程池状态
int c = ctl.get();
int rs = runStateOf(c);
/*
* 1. 如果是 RUNNING 状态,进入下一步;
* 1. 如果是 SHUTDOWN 状态,并且任务队列为空,返回 null,减少 workerCount;
* 2. 如果是 STOP,TIDYING 或者 TERMINATED 状态,直接返回 false,减少 workerCount。
*/
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// 获取有效线程数
int wc = workerCountOf(c);
/*
* 标记变量,表示当前 worker 是否要超时退出
* 1. allowCoreThreadTimeOut 设置 true 的话,所有的线程超时都要退出;
* 2. 否则,只有当有效线程数大于核心线程数,需要减少线程池的数量,要设置超时退出。
*/
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 根据是否超时、线程数大小、任务队列大小的情况,判断是否要退出
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
// 如果可以减少 workerCount,返回 null,否则进入自旋,进入下一个循环。
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
/*
* 如果要超时退出,当前使用 poll 方法,并设置了超时时间,超时后会退出
* 如果不需要设置超时,使用 take 方法,一直阻塞直到队列中有任务
*/
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
在 runWorker() 中,如果传入要执行的任务,是不会调用 getTask() 的。
如果线程取不到任务,返回 null 的同时,会调用 decrementWorkerCount 减少有效工作线程数量 workerCount。
什么时候会取不到任务返回 null 让线程关闭呢?作者的方法注释中总结如下:
- **当前线程数大于最大线程数
maximumPoolSize**,比如执行期间调用 setMaximumPoolSize 方法调整了配置。 - STOP 状态。我们从前面线程池的生命周期可以知道,SHUTDOWN 状态下,如果任务队列还有任务没有执行完,会先执行完。而 STOP 状态更严格,不会等待队列里的任务执行完就会退出线程。
- SHUTDOWN 状态,并且任务队列为空。SHUTDOWN 状态下,如果任务队列没有任务了,线程不会阻塞等待任务,返回 null 让线程退出。
- 如果 线程池设置了超时时间,并且满足这两种情况之一:1. allowCoreThreadTimeOut 被设置为 true,说明所有的线程超时都要关闭。 2. 当前工作线程数量大于
corePoolSize。就会使用 BlockingQueue 的 poll 方法设置超时时间去取任务。超时时间到了取不到任务后,还会进入下一个循环,再做一次判断(timed && timedOut)) && (wc > 1 || workQueue.isEmpty()),确定线程不是最后一个线程,并且队列为空。也就是说,如果超时后发现队列还有任务,那么还会再次尝试去取任务;超时后发现整个线程池只剩下一个线程的话,那么这个线程会留着不会关闭。
我们从上面的 runWorker() 解析可以看到,当 getTask() 返回 null 的话,runWorker() 的死循环会被打破,然后进入线程退出处理方法 processWorkerExit。
所以线程进入关闭流程的重要条件,就是 getTask() 返回了 null。
5.3.6. processWorkerExit()
如何处理工作线程的退出?会调用 ThreadPoolExecutor.processWorkerExit。这个方法有两个参数:
- w ,要执行关闭的
Worker对象。线程池会取出Worker里对Thread执行的一些记录,比如完成的任务数 completedTasks。 - completedAbruptly ,boolean 值,是否是异常引起的关闭。如果是的话,线程池会尝试再开启一个线程来做补充。
代码如下:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 如果是异常退出的话,恢复 workerCount
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 把之前 Worker 的完成任务数收集起来,然后从工作线程队列中移除。
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
tryTerminate();
int c = ctl.get();
if (runStateLessThan(c, STOP)) {
/*
* 如果还在 RUNNING 或者 SHUTDOWN 状态,这里还处理
* 1. 如果是异常退出,再启动一个新的线程替换。
* 2. 如果不是异常退出,确定一个最少存在的线程数:
* 如果设置了 allowCoreThreadTimeout 的话,并且任务队列还有值,min = 1,
* 如果设置了 allowCoreThreadTimeout 的话,min = corePoolSize,
* 然后如果当前工作线程数比 min 小的话,会再启动一个新线程替换。
*/
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && !workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}
主要如下:
- 异常退出,会再调用 decrementWorkerCount 减一下 workerCount。
- 记录已经完成的任务数收集到
completedTaskCount中。 - 把 Worker 从工作线程队列 workers 中移除。
- 也会调用一下
tryTerminate(),这个我们在之前的addWorkerFailed()也看到有调用。原因一样,还是这个Worker可能停止了线程池的终止过程,所以这里尝试再调用tryTerminate重新尝试终止线程池。 - RUNNING 或者 SHUTDOWN 状态,并且是异常退出 ,创建新的 Worker;
- **RUNNING 或者 SHUTDOWN 状态,不是异常退出 **,根据是否配置 allowCoreThreadTimeout 来会确定一个 min 的值。如果设置了 allowCoreThreadTimeout = true,所有的线程超时都要退出,就没有核心线程的概念了,所以 min = 0。如果 allowCoreThreadTimeout = false,那就有核心线程数的概念,这是要常驻的线程,min = corePoolSize。 然后再看当前线程池的数量和任务队列的数量,如果任务队列不是空的,还有队列,至少需要一个线程把任务执行完,如果 min 为 0 调整为 1,确保有线程把任务队列中尚未执行完的任务执行完。
5.4. 获取线程池运行情况
线程池启动后,可以通过一些接口获取整体运行情况。
-
getPoolSize(),获取工作的线程池数量。源码如下:
public int getPoolSize() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Remove rare and surprising possibility of // isTerminated() && getPoolSize() > 0 return runStateAtLeast(ctl.get(), TIDYING) ? 0 : workers.size(); } finally { mainLock.unlock(); } }可以看到,如果已经进入了 TIDYING 状态,会直接返回 0。
-
getActiveCount(),获取正在执行任务的线程数。如何知道线程正在执行任务?
根据我们之前的分析,Worker 继承 AQS 实现了不可重入锁,在执行任务的时候加锁,执行完毕后解锁。所以,只要统计加锁的 Worker 的数量。 源码如下:
public int getActiveCount() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { int n = 0; for (Worker w : workers) if (w.isLocked()) ++n; return n; } finally { mainLock.unlock(); } } -
getTaskCount(),获取线程池执行的任务数,包括执行完成的和正在执行的。Worker 内部有一个变量
completedTasks来记录线程已经完成的任务数,在runWorker()的方法中,每执行完一个任务会增加计数。while (task != null || (task = getTask()) != null) { ... try { ... } finally { task = null; w.completedTasks++; ... } }线程退出执行
processWorkerExit()时,内部会把退出线程执行的任务数加入到completeTaskCount中。completedTaskCount += w.completedTasks;又因为正在执行的任务数,会统计加锁的 Worker 数量,源码如下:
public long getTaskCount() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { long n = completedTaskCount; for (Worker w : workers) { n += w.completedTasks; if (w.isLocked()) ++n; } return n + workQueue.size(); } finally { mainLock.unlock(); } }需要注意的是,这里只是一个快照值。因为我们在执行
getTaskCount(),并不会阻塞线程池执行任务。
5.5. 关闭线程池
现在来看看如何关闭线程池。
5.5.1. shutdown()
该方法会触发线程池关闭流程,但不会马上关闭。
什么时候才能知道线程池已经执行完关闭流程?需要使用 awaitTermination 去判断。见 ThreadPoolExecutor.shutdown():
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(SHUTDOWN);
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
执行 checkShutdownAccess(),如果没有权限的话会抛出 SecurityException。
调用 advanceRunState() 改变线程池状态为 SHUTDOWN。内部使用 CAS 加自旋。
调用 interruptIdleWorkers() 方法去中断空闲的线程。
然后留了一个钩子方法 onShutDown(),如果有需要的话,可以继承 ThreadPoolExecutor 实现该回调,做一些关闭的其他处理。
最后会调用 tryTerminate() 方法,尝试终止线程池。如果任务队列还有任务没有执行完,这个尝试是不成功的。
5.5.2. shutdownNow()
这个方法和 shutdown() 类似,但会去关闭所有线程,不会再去执行任务队列中的未执行的任务,把这些未执行的队列返回。
见 ThreadPoolExecutor.shutdownNow():
public List shutdownNow() {
List tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
可以看到,和 shutdown() 流程基本相同。状态修改为 STOP。
我们之前线程取任务执行的 ThreadPoolExecutor.getTask() 方法中,有对 STOP 状态的判断:
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
可以看到,只要是大于等于 STOP 状态,直接返回 null,触发线程关闭。
如果有一些线程不是空闲线程,比如处于 sleep() 或者 wait() 的线程,会去中断这些线程。所以设计运行任务 Runnable 的时候,有 sleep 或者 wait 操作,或者内部有一个循环,需要响应中断并进行退出处理。在 runWorker() 可以看到中断这些线程的逻辑:
if ((runStateAtLeast(ctl.get(), STOP) || (Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();
调用 drainQueue() 方法把未执行的任务取出,会返回给调用者。
调用 tryTerminate() 方法,尝试终止线程池。
5.5.3. tryTerminate()
前面分析的 addWorkerFailed(),processWorkerExit(),shutdown(),shutdownNow() 都有调用 tryTerminate() 。源码如下:
final void tryTerminate() {
for (; ; ) {
int c = ctl.get();
if (isRunning(c) || runStateAtLeast(c, TIDYING) || (runStateOf(c) == SHUTDOWN && !workQueue.isEmpty()))
return;
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}
通过该方法,让线程池进入到 TIDYING 和 TERMINATED。
当然,这里只是尝试,对照代码我们可以知道,这些情况下不会直接退出尝试。
- RUNNING,不终止。
- TIDYING 或者 TERMINATED,不需要重复终止,直接退出。
- SHUTDOWN 且任务队列 workQueue 里还有任务,不终止,需要把任务执行完。
如果上面的条件都通过了,要进入 TIDYING 和 TERMINATED 状态,必须工作线程都关闭,workerCount 为 0。还有线程未关闭,调用 interruptIdleWorkers(ONLY_ONE) 去关闭。
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
线程关闭完毕,状态切换为 TIDYING,线程池会再调用一次钩子方法 terminated() 。
最后直接设置状态为 TERMINATED。