
《Keras快速上手:基于Python的深度学习实战》系统地讲解了深度学习的基本知识、建模过程和应用,并以深度学习在推荐系统、图像识别、自然语言处理、文字生成和时间序列中的具体应用为案例,详细介绍了从工具准备、数据获取和处理到针对问题进行建模的整个过程和实践经验,是一本非常好的深度学习入门书。本章节选自《Keras快速上手:基于Python的深度学习实战》第四章Keras入门部分内容。
福利提醒:在评论区留言,分享你的Keras学习经验,评论点赞数前五名可获得本书。时间截止周五(8月11日)晚22点。
作者 | 谢梁 鲁颖 劳虹岚
从上面的介绍看到,在Keras中,定义神经网络的具体结构是通过组织不同的网络层(Layer)来实现的。因此了解各种网络层的作用还是很有必要的。
核心层
核心层(CoreLayer)是构成神经网络最常用的网络层的集合,包括:全连接层、激活层、放弃层、扁平化层、重构层、排列层、向量反复层、Lambda 层、激活值正则化层、掩盖层。所有的层都包含一个输入端和一个输出端,中间包含激活函数以及其他相关参数等。
(1) 全连接层。
在神经网络中最常见的网络层就是全连接层,在这个层中实现对神经网络里面的神经元的激活。比如:y = g(x′w + b),其中w 是该层的权重向量,b 是偏置项,g() 是激活函数。如果use_bias 选项设置为False,那么偏置项为0。常见的引用全连接层的语句如下:
model.add(Dense(32,activation='relu',use_bias=True, kernel_initializer='uniform',kernel_initializer='uniform', activity_regularizer=regularizers.l1_l2(0.2, 0.5) )
在上面的语句中:
32,表示向下一层输出向量的维度,
activation='relu',表示使用relu 函数作为对应神经元的激活函数。
kernel_initializer='uniform',表示使用均匀分布来初始化权重向量,类似的选项也可以用在偏置项上。读者可以参考前面的“初始化对象”部分的介绍。
activity_regularizer=regularizers.l1_l2(0.2, 0.5),表示使用弹性网作为正则项,其中一阶的正则化参数为0.2,二阶的正则化参数为0.5。
(2) 激活层。
激活层是对上一层的输出应用激活函数的网络层,这是除应用activation选项之外,另一种指定激活函数的方式。其用法很简单,只要在参数中指明所需的激活函数即可,预先定义好的函数直接引用其名字的字符串,或者使用TensorFlow 和Theano 自带的激活函数。如果这是整个网络的第一层,则需要用input_shape 指定输入向量的维度。
(3) 放弃层。
放弃层(Dropout)是对该层的输入向量应用放弃策略。在模型训练更新参数的步骤中,网络的某些隐含层节点按照一定比例随机设置为不更新状态,但是权重仍然保留,从而防止过度拟合。这个比例通过参数rate 设定为0 到1 之间的实数。在模型训练时不更新这些节点的参数,因此这些节点并不属于当时的网络;但是保留其权重,因此在以后的迭代次序中可能会影响网络,在打分的过程中也会产生影响,所以这个放弃策略通过不同的参数估计值已经相对固化在模型中了。
(4) 扁平化层。
扁化层(Flatten)是将一个维度大于或等于3 的高维矩阵按照设定“压扁”为一个二维的低维矩阵。其压缩方法是保留第一个维度的大小,然后将所有剩下的数据压缩到第二个维度中,因此第二个维度的大小是原矩阵第二个维度之后所有维度大小的乘积。这里第一个维度通常是每次迭代所需的小批量样本数量,而压缩后的第二个维度就是表达原图像所需的向量长度。
比如输入矩阵的维度为(1000;64; 32; 32),扁平化之后的维度为(1000; 65536),其中65536 = 64 32 32。如果输入矩阵的维度为(None;64; 32; 32),则扁平化之后的维度为(None; 65536)。
(5) 重构层。
重构层(Reshape)的功能和Numpy 的Reshape 方法一样,将一定维度的多维矩阵重新排列构造为一个新的保持同样元素数量但是不同维度尺寸的矩阵。其参数为一个元组(tuple),指定输出向量的维度尺寸,最终的向量输出维度的第一个维度的尺寸是数据批量的大小,从第二个维度开始指定输出向量的维度大小。
比如可以把一个有16 个元素的输入向量重构为一个(None;4; 4) 的新二维矩阵:
1 model = Sequential()
2 model.add(Reshape( (4, 4), input_shape=(16, ) ) )
最后的输出向量不是(4,4),而是(None, 4, 4)。
(6) 排列层。
排列层(Permute)按照给定的模式来排列输入向量的维度。这个方法在连接卷积网络和时间递归网络的时候非常有用。其参数是输入矩阵的维度编号在输出矩阵中的位置。比如:
model.add(Permute((1, 3, 2), input_shape=(10, 16, 8)))
将输入向量的第二维和第三维的数据进行交换后输出,但是第一维的数据还是待在第一维。这个例子使用了input_shape 参数,它一般在第一层网络中使用,在接下来的网络层中,Keras 能自己分辨输入矩阵的维度大小。
(7) 向量反复层。
顾名思义,向量反复层就是将输入矩阵重复多次。比如下面这个例子:
1 model.add(Dense(64, input_dim=(784, )))
2 model.add(RepeatVector(3))
在第一句中,全连接层的输入矩阵是一个有784 个元素的向量,输出向量是一个维度为(one, 64) 的矩阵;而第二句将该矩阵反复3 次,从而变成维度为(None, 3, 64) 的多维矩阵,反复的次数构成第二个维度,第一个维度永远是数据批量的大小。
(8) Lambda 层。
Lambda 层可以将任意表达式包装成一个网络层对象。参数就是表达式,一般是一个函数,可以是一个自定义函数,也可以是任意已有的函数。如果使用Theano 和自定义函数,可能还需要定义输出矩阵的维度。如果后台使用CNTK 或TensorFlow,可以自动探测输出矩阵的维度。比如:
model.add(Lambda(lambda x: numpy.sin(x)))
使用了一个现成函数来包装。这是一个比较简单的例子。在Keras 手册中举了一个更复杂的例子,在这个例子中用户自定义了一个激活函数叫作AntiRectifier,同时输出矩阵的维度也需要明确定义。
1 def antirectifier(x):
2 x -= K.mean(x, axis=1, keepdims=True)
3 x = K.l2_normalize(x, axis=1)
4 pos = K.relu(x)
5 neg = K.relu(-x)
6 return K.concatenate([pos, neg], axis=1)
7
8 def antirectifier_output_shape(input_shape):
9 shape = list(input_shape)
10 assert len(shape) == 2
11 shape[-1] *= 2
12 return tuple(shape)
13
14 model.add(Lambda(antirectifier, output_shape=antirectifier_output_shape))
(9) 激活值正则化层。
这个网络层的作用是对输入的损失函数更新正则化。
(10) 掩盖层。
该网络层主要使用在跟时间有关的模型中,比如LSTM。其作用是输入张量的时间步,在给定位置使用指定的数值进行“屏蔽”,用以定位需要跳过的时间步。
输入张量的时间步一般是输入张量的第1 维度(维度从0 开始算,见例子),如果输入张量在该时间步上等于指定数值,则该时间步对应的数据将在模型接下来的所有支持屏蔽的网络层被跳过,即被屏蔽。如果模型接下来的一些层不支持屏蔽,却接收到屏蔽过的数据,则抛出异常。
1 model = Sequential()
2 model.add(Masking(mask_value=0., input_shape=(timesteps, features)))
3 model.add(LSTM(32))
如果输入张量X[batch,timestep, data] 对应于timestep=5, 7 的数值是0,即X[:, [5,7],:] = 0,那么上面的代码指定需要屏蔽的对象是所有数据为0 的时间步,然后接下来的长短记忆网络在遇到时间步为5 和7 的0 值数据时都会将其忽略掉。
卷积层
针对常见的卷积操作,Keras提供了相应的卷积层API,包括一维、二维和三维的卷积操作、切割操作、补零操作等。
卷积在数学上被定义为作用于两个函数f 和g 上的操作来生成一个新的函数z。这个新的函数是原有两个函数的其中一个(比如f)在另一个(比如g)的值域上的积分或者加权平均。维基百科图例https://en.wikipedia.org/wiki/Convolution
假设有两个函数f 和g,其函数形式如图4.2所示。对这两个函数进行卷积操作按如下步骤进行。
(1) 将f 和g 函数都表示为一个变量t 的函数,如图4.2所示。
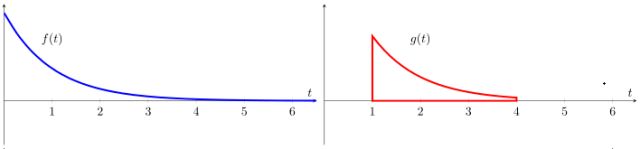
图4.2 f 和g 函数形式
(2) 将f 和g 函数都表示为虚拟变量 的函数,并将其中一个函数比如g 的取值进行反转,如图4.3所示。
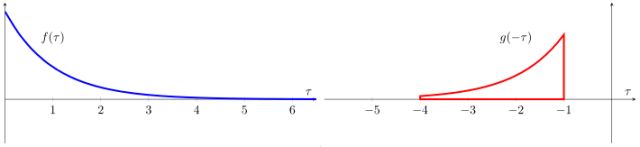
图4.3 反转g 的取值
(3) 接下来在此基础上加一个时间抵消项,这样在新的值域上的函数g 就是在这个轴上移动的窗口,如图4.4所示的一样。虽然这里是静态图像,但是读者可以想象g函数的曲线表示的是该函数沿着坐标轴移动的情景。
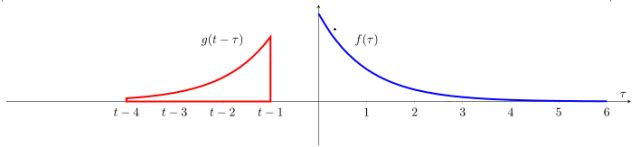
图4.4 移动g 函数
(4) 从负无穷大的时间开始,一直移动到正无穷大。在两个函数取值有交接的地方,找出其积分,换句话说,就是对函数f 计算其在一个平滑移动窗口的加权平均值,而这个权重就是反转后的函数g 在同样值域中的相应取值。图4.5展示了这个过程。
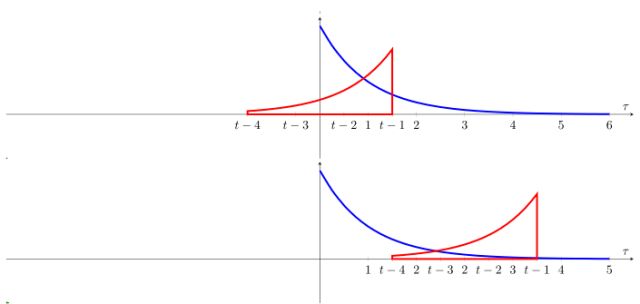
图4.5 卷积过程
这样得到的波形就是这两个函数的卷积。
卷积操作分为一维、二维和三维,对应的方法分别是Conv1D、Conv2D 和Conv3D,这些方法有同样的选项,只是作用于不同维度的数据上,因此适用于不同的业务情景。当作为首层使用时,需要提供输入数据维度的选项input_shape。这个选项指定输入层数据应有的维度,但是每个维度数据的含义不同,需要分别介绍。
一维卷积通常被称为时域卷积,因为其主要应用在以时间排列的序列数据上,其使用卷积核对一维数据的邻近信号进行卷积操作来生成一个张量。二维卷积通常被称为空域卷积,一般应用在与图像相关的输入数据上,也是使用卷积核对输入数据进行卷积操作的。三维卷积也执行同样的操作。
Conv1D、Conv2D 和Conv3D 的选项几乎相同。
filters:卷积滤子输出的维度,要求整数。
kernel_size:卷积核的空域或时域窗长度。要求是整数或整数的列表,或者是元组。如果是单一整数,则应用于所有适用的维度。
strides:卷积在宽或者高维度的步长。要求是整数或整数的列表,或者是元组。如果是单一整数,则应用于所有适用的维度。如果设定步长不为1,则dilation_rate选项的取值必须为1。
padding:补齐策略,取值为valid、same 或causal。causal 将产生因果(膨胀的)卷积,即output[t] 不依赖于input[t+1:],在不能违反时间顺序的时序信号建模时有用。请参考WaveNet: A Generative Model for Raw Audio, section 2.1.。valid代表只进行有效的卷积,即对边界数据不处理。same 代表保留边界处的卷积结果,通常会导致输出shape 与输入shape 相同。
data_format:数据格式,取值为channels_last 或者channels_first。这个选项决定了数据维度次序,其中channels_last 对应的数据维度次序是(批量数,高,宽,频道数),而channels_first 对应的数据维度次序为(批量数,频道数,高,宽)。
activation:激活函数,为预定义或者自定义的激活函数名,请参考前面的“网络层对象”部分的介绍。如果不指定该选项,将不会使用任何激活函数(即使用线性激活函数:a(x) = x)。
dilation_rate:该选项指定扩张卷积(Dilated Convolution)中的扩张比例。要求为整数或由单个整数构成的列表/元组,如果dilation_rate 不为1,则步长一项必须设为1。
use_bias:指定是否使用偏置项,取值为True 或者False。
kernel_initializer:权重初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的函数。请参考前面的“网络层对象”部分的介绍。
bias_initializer:偏置初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置的函数。请参考前面的“网络层对象”部分的介绍。
kernel_regularizer:施加在权重上的正则项,请参考前面的关于网络层对象中正则项的介绍。
bias_regularizer:施加在偏置项上的正则项,请参考前面的关于网络层对象中正则项的介绍。
activity_regularizer:施加在输出上的正则项,请参考前面的关于网络层对象中正则项的介绍。
kernel_constraints:施加在权重上的约束项,请参考前面的关于网络层对象中约束项的介绍。
bias_constraints:施加在偏置项上的约束项,请参考前面的关于网络层对象中约束项的介绍。
除上面介绍的卷积层以外,还有一些特殊的卷积层,比如SeparableConv2D、Conv2DTranspose、UpSampling1D、UpSampling2D、UpSampling3D、ZeroPadding1D、ZeroPadding-2D、ZeroPadding3D 等,这里限于篇幅就不一一介绍了,感兴趣的读者请参阅Keras 用户手册。
池化层
池化(Pooling)是在卷积神经网络中对图像特征的一种处理,通常在卷积操作之后进行。池化的目的是为了计算特征在局部的充分统计量,从而降低总体的特征数量,防止过度拟合和减少计算量。
举例说明:假设有一个128 128 的图像,以88 的网格做卷积,那么一个卷积操作一共可以得到(128..8+1)2 个维度的输出向量,如果有70 个不同的特征进行卷积操作,那么总体的特征数量可以达到70(128..8+1)2 = 1 024 870个。用100 万个特征做机器学习,除非数据量极大,否则很容易发生过度拟合。所以池化技术就是对卷积出来的特征分块(比如分成新的m n 个较大区块)求充分统计量,比如本块内所有特征的平均值或者最大值等,然后用得到的充分统计量作为新的特征。
当然,这个操作依赖于一个假设,就是卷积之后的新特征在局部是平稳的,即在相邻空间内的充分统计量相差不大。对于大多数应用,特别是与图像相关的应用,这个假设可以认为是成立的。图4.6展示了对卷积出来的特征在4 个(22)不重合区块进行池化操作的结果。
Keras 的池化层按照计算的统计量分为最大统计量池化和平均统计量池化;按照维度分为一维、二维和三维池化层;按照统计量计算区域分为局部池化和全局池化。
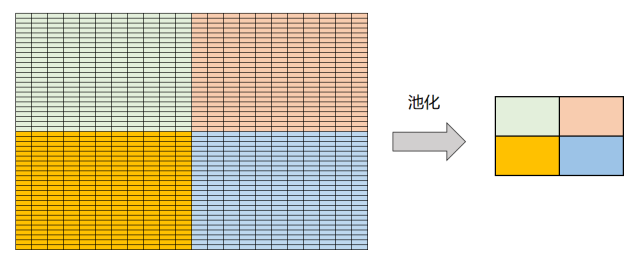
图4.6 池化操作
(1) 最大统计量池化方法:
MaxPooling1D,这是对一维的时域数据计算最大统计量的池化函数,输入数据的格式要求为(批量数,时间步,各个维度的特征值),输出数据为三维张量(批量数,下采样后的时间步数,各个维度的特征值)。
MaxPooling2D ,这是对二维的图像数据计算最大统计量的池化函数,输入输出数据均为四维张量,具体的格式根据data_format 选项要求分别为:
data_format="channels_first":输入数据=(样本数,频道数,行,列),输出数据=(样本数,频道数,池化后行数,池化后列数)。
data_format="channels_last":输入数据=(样本数,行,列,频道数),输出数据=(样本数,池化后行数,池化后列数,频道数)。
MaxPooling3D,这是对三维的时空数据计算最大统计量的池化函数,输入输出数据都是五维张量,具体的格式根据data_format 选项要求分别为:
data_format="channels_first":输入数据=(样本数,频道数,一维长度,二维长度,三维长度),输出数据=(样本数,频道数,池化后一维长度,池化后二维长度,池化后三维长度)。
data_format="channels_last":输入数据=(样本数,行,一维长度,二维长度,三维长度),输出数据=(样本数,池化后一维长度,池化后二维长度,池化后三维长度,频道数)。
(2) 平均统计量池化方法:
这个方法的选项和数据格式要求跟最大化统计量池化方法一样,只是池化方法使用局部平均值而不是局部最大值作为充分统计量,方法名字分别为AveragePooling1D、AveragePooling2D 和AveragePooling3D。
(3) 全局池化方法:
该方法应用全部特征维度的统计量来代表特征,因此会压缩数据维度。比如在局部池化方法中,输出维度和输入维度是一样的,只是特征的维度尺寸因为池化变小;但是在全局池化方法中,输出维度小于输入维度,如在二维全局池化方法中输入维度为(样本数,频道数,行,列),全局池化以后行和列的维度都被压缩到全局统计量中,因此输出维度只有(样本数,频道数)二维。全局池化方法也分为最大统计量池化和平均统计量池化,以及一维和二维池化方法。
一维池化:一维池化方法分为最大统计量和平均统计量两种,方法名字分别为GlobalMaxPooling1D 和GlobalAveragePooling1D。输入数据格式要求为(批量数,步进数,特征值),输出数据格式为(批量数,频道数)。这两个方法都没有选项。
二维池化:二维池化方法也分为最大统计量和平均统计量两种,方法名字分别为GlobalMaxPooling2D 和GlobalAveragePooling2D。这两个方法有关于输入数据要求的选项:data_format。当data_format="channels_first" 时,输入数据格式为(批量数,行,列,频道数);当data_format="channels_last" 时,输入数据格式为(批量数,频道数,行,列)。输出数据格式都为(批量数,频道数)。
循环层
循环层(RecurrentLayer)用来构造跟序列有关的神经网络。但是其本身是一个抽象类,无法实例化对象,在使用时应该使用LSTM,GRU 和SimpleRNN 三个子类来构造网络层。在介绍这些子类的用法之前,我们先来了解循环层的概念,这样在写Keras代码时方便在头脑中进行映射。循环网络和全连接网络最大的不同是以前的隐藏层状态信息要进入当前的网络输入中。
比如,全连接网络的信息流是这样的:(当前输入数据)→隐藏层→输出。
而循环网络的信息流是这样的:(当前输入数据+ 以前的隐藏层状态信息)→当前隐藏层→输出。
下面的例子借用了iamtrask.github.io博主的讲解。
图4.7展示了一个典型的循环层依时间步变化的结构。
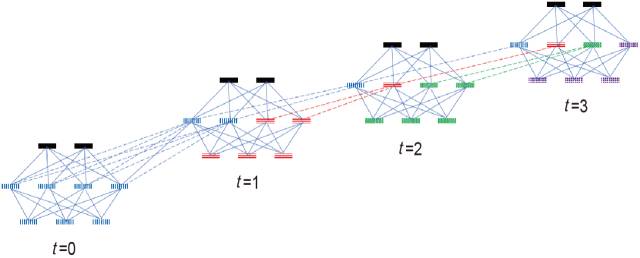
图4.7 典型的循环层依时间步变化的结构
首先,在时间步为0 的时候,所有影响都来自于输入,但是从时间步1 开始,其隐藏层的信息是时间步0 和时间步1 的一个混合,时间步3 的隐藏层状态信息是以前两个时间步和当前时间步信息的混合,依此类推。以前时间步的隐藏层状态信息构成了记忆,因此,网络的大小决定了记忆力的大小,而通过控制哪些记忆来保留和去除可以选择以前时间步的信息对当前时间步的影响力,即记忆的深度。
用上面的信息流方式来表达这个网络,如图4.8所示。

图4.8 循环层结果依时间步变化的信息流表达形式
这里使用色彩形象地显示了在不同时间段的信息通过隐藏层在以后时间中传播和施加影响的过程。
简单循环层。SimpleRNN 是循环层的一个子类,用来构造全连接的循环层,是循环网络最直接的应用,使用recurrent.SimipleRNN 来调用。
长短记忆层。LSTM 是循环层的另一个子类,和简单循环层相比,其隐藏状态的权重网络稀疏。
带记忆门的循环层(GRU)。
以上具体类别包含如下共同选项。
units:输出向量的大小,为整数。
activation:激活函数,为预定义或者自定义的激活函数名,请参考前面的“网络层对象”部分的介绍。如果不指定该选项,将不会使用任何激活函数(即使用线性激活函数:a(x) = x)。
use_bias:指定是否使用偏置项,取值为True 或者False。
kernel_initializer:权重初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的函数。请参考前面的“网络层对象”部分的介绍。
recurrent_initializer:循环层状态节点权重初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的函数。请参考前面的“网络层对象”部分的介绍。
bias_initializer:偏置初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置的函数。请参考前面的“网络层对象”部分的介绍。
kernel_regularizer:施加在权重上的正则项,请参考前面的关于网络层对象中正则项的介绍。
recurrent_regularizer:施加在循环层状态节点权重上的正则项,请参考前面的关于网络层对象中正则项的介绍。
bias_regularizer:施加在偏置项上的正则项,请参考前面的关于网络层对象中正则项的介绍。
activity_regularizer:施加在输出上的正则项,请参考前面的关于网络层对象中正则项的介绍。
kernel_constraint:施加在权重上的约束项,请参考前面的关于网络层对象中约束项的介绍。
recurrent_constraint:施加在循环层状态节点权重上的约束项,请参考前面的关于网络层对象中约束项的介绍。
bias_constraint:施加在偏置项上的约束项,请参考前面的关于网络层对象中约束项的介绍。
dropout:指定输入节点的放弃率,为0 到1 之间的实数。
recurrent_dropout:指定循环层状态节点的放弃率,为0 到1 之间的实数。
LSTM 和GRU 则额外包含一个选项叫作recurrent_activation,这个选项控制循环步所使用的激活函数。
嵌入层
嵌入层(EmbeddingLayer)是使用在模型第一层的一个网络层,其目的是将所有索引标号映射到致密的低维向量中,比如[[4], [32], [67]]![[0.3, 0.9, 0.2], [-0.2, 0.1, 0.8],[0.1, 0.3,0.9]] 就是将一组索引标号映射到一个三维的致密向量中,通常用在对文本数据进行建模的时候。输入数据要求是一个二维张量:(批量数,序列长度),输出数据为一个三维张量:(批量数,序列长度,致密向量的维度)。
其选项如下。
输入维度:这是词典的大小,一般是最大标号数+1,必须是正整数。
output_dim:输出维度,这是需要映射到致密的低维向量中的维度,为大于或等于0 的整数。
embeddings_initializer:嵌入矩阵的初始化方法,请参考前面的关于网络层对象中对初始化方法的介绍。
embeddings_regularizer::嵌入矩阵的正则化方法,请参考前面的关于网络层对象中正则项的介绍。
embeddings_constraint:嵌入层的约束方法,请参考前面的关于网络层对象中约束项的介绍。
mask_zero:是否屏蔽0 值。通常输入值里的0 是通过补齐策略对不同长度输入补齐的结果,如果为0,则需要将其屏蔽。如果输入张量在该时间步上都等于0,则该时间步对应的数据将在模型接下来的所有支持屏蔽的网络层被跳过,即被屏蔽。如果模型接下来的一些层不支持屏蔽,却接收到屏蔽过的数据,则抛出异常。如果设定了屏蔽0 值,则词典不能从0 开始做索引标号,因为这时候0 值已经具有特殊含义了。
input_length:输入序列长度。当需要连接扁平化和全连接层时,需要指定该选项;否则无法计算全连接层输出的维度。
合并层
合并层是指将多个网络产生的张量通过一定方法合并在一起,可以参看下一节中的奇异值分解的例子。合并层支持不同的合并方法,包括:元素相加(merge.Add)、元素相乘(merge.Multiply)、元素取平均(merge.Average)、元素取最大(merge.Maximum)、叠加(merge.Concatenate)、矩阵相乘(merge.Dot)。
其中,元素相加、元素相乘、元素取平均、元素取最大方法要求进行合并的张量的维度大小完全一致。叠加方法要求指定按照哪个维度(axis)进行叠加,除了叠加的维度,其他维度的大小必须一致。矩阵相乘方法是对两个张量采用矩阵乘法的形式来合并,因为张量是高维矩阵,因此需要指定沿着哪个维度(axis)进行乘法操作。同时可以指定是否标准化(Normalize),如果是的话(Normalize=True),则先将两个张量归一化以后再相乘,这时得到的是余弦相似度。
来自于MITTechnology Review 的图4.9很好地展示了网络合并结构。
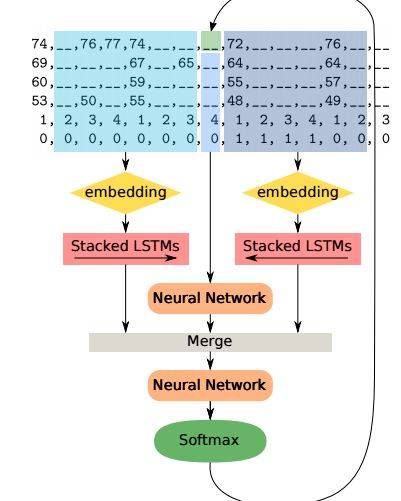
图4.9 网络合并结构
以上就是4.5小节的全部内容,想要阅读更多内容,请在评论区留言,分享你的Keras学习经验,评论点赞数前五名可获得本书。时间截止周五(8月11日)晚22点。