会议介绍:CCF TF 12期 语言认知与知识计算研讨会
CCF简介
CCF,全称为 中国计算机学会(China Computer Federation)。成立于1962年,全国一级学会,独立社团法人,中国科学技术协会成员。
CCF的主要品牌活动(会议)有:
- CNCC(中国计算机大会):计算领域的科技“大集”;每年一届,已举办14届,单届参与者已超过6000人。
- ADL(学科前沿讲习班):全球顶尖产业与学界专家授课;每年10次,每次2-3天,每次参与人数200-400人。
- TF(技术前沿):企业技术一线精英实践和交流;每年10次。多数参会者为互联网企业技术团队。
- 其他各项品牌活动:CCF官方活动介绍
本次所参加的会议即为TF系列,---CCF TF第12期研讨会 ---《语言认知与知识计算》。
报告一:《在知识图谱工程中如何进行规则建模》- 鲍捷
背景介绍:鲍捷,博士,文因互联 CEO,联合创始人。他曾是三星美国研发中心研究员,伦斯勒理工学院(RPI)博士后,麻省理工学院(MIT)分布式信息组(DIG)访问研究员,以及雷神 BBN 技术公司访问科学家。
报告主要讲述了一些 知识图谱的基本概念知识 和 常用建模推理工具。
知识图谱层级
知识图谱由顶层的 Schema 以及底层的 实例数据 构成。
Schema又分为三个层次:
- 实体的Schema:可类比数据库模式。
数据库schema 就是数据库对象的集合。数据库对象即表,索引,视图,存储过程等。
实体的Schema 主要就是领域中所包含的概念以及其属性的描述。 - 本体(Ontology):分类树和概念的描述。主要描述概念层次和关系。
- 规则(Rule):if....then....else。
构建Schema 相当于为其建立本体(Ontology)。最基本的本体包括概念(Class)、概念层次、属性(Property)、属性值类型、关系、关系定义域(Domain)概念集、关系值域(Range)概念集以及推理规则(Rules)。
本体和规则
常用的本体和规则建模语言/规范:
- OWL RL(OWL2的规则子集)
- RIF(严谨的规则语言)
- SWRL(不太严谨的规则语言)
- SPIN(用SPARQL写规则) ---工程上较为常用
- Jena Rules(Jena的规则语言)
本体 (ontology) 和规则 (rules) 的核心区别:
- 本体以刻画理念和关系为核心
- 规则面向推理和过程
规则的定义:
规则就是在图谱的边上加的一些约定。
知识图谱在图中由点(实例)和边(关系)构成。
而规则就是通过约定,将不相邻的点建立连接。
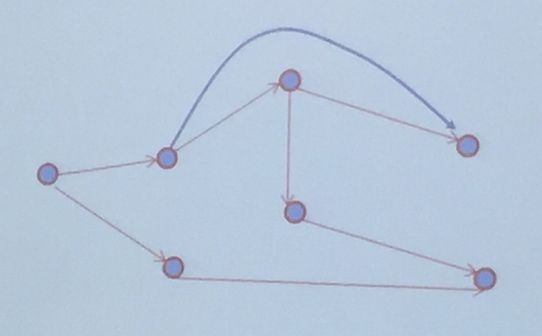
规则的描述语言
可以用逻辑语言来描述规则:
- FOL一阶逻辑:应用于需要特别丰富表达力的场景下
- DL描述逻辑:需要保证可判定性(“不死机”)的场景下
- Logic program/ASP:类似于数据库的封闭数据场景下
- Production rules生成式规则(最常用) (产生式规则介绍) :不需要结果完备、简单易维护的场景下
可以用编程语言来描述规则:
- Prolog:严谨的大型AI项目场景下,可以考虑用Prolog建模。
- Lisp:同上
规则推理引擎及算法:
推理:由已知的已知 发现 未知的已知 的过程。
算法:
- 前向链:通过已有数据开始寻找结果。如Rete算法 (最常用)。
大部分商用规则引擎如drool,jess等,采用rete算法。 - 反向链:通过结果进行反推。如Resolution
规则本身是一种数据
规则是提升智能复用的最佳实践,把智能放到数据里,而非代码里。

常用规则工具
- Bussiness rule管理系统 BRMS:Drools(最常用),JBoss
- LP推理机:XSB、DLV
- 语义网推理机:RDFox、stardog
- python规则工具:Pydatalog(轻量级)、 rdfQuery 、PySWIP 、Pylog、 FLiP seth
成本控制
构造一个知识图谱模型需要考虑如下成本:
构造成本
管理成本
推理成本
调试成本
项目落地的关键就是降低全周期的成本。
报告二:《阿里机器翻译》- 陈博兴
背景介绍:陈博兴,阿里巴巴集团达摩院,机器智能技术实验室资深算法专家。他的研究方向是机器翻译,自然语言处理和机器学习。在加入阿里之前,他是加拿大国家研究委员会(NRC)的终身研究员,意大利FBK-IRST和法国格勒诺布尔大学的博士后。领导的机器翻译团队在WMT 2018中获五个语项第一名。
报告内容链接:阿里巴巴陈博兴:单天翻译词量超过千亿的秘密
阿里机器翻译市场需求
跨境贸易:每年双十一期间,俄罗斯物流系统就会崩溃!因为俄罗斯人民通过 AliExpress 从中国买了太多的东西,俄罗斯人民看不懂中文,中国的卖家也不懂俄罗斯语,那么是如何实现的?这得益于阿里巴巴翻译系统。
阿里使命:让天下没有难做的生意。
阿里机器翻译:让天下的生意没有语言障碍。
阿里达摩院
阿里在2016年的11月份成立了达摩院。首先,达摩院有个顾问委员会,分别会在亚洲,美洲和欧洲成立分院。然后,阿里集团内部会有四大实验室,其中第一个实验室是机器智能技术实验室(MIT Lab),后续还有成立三个实验室。
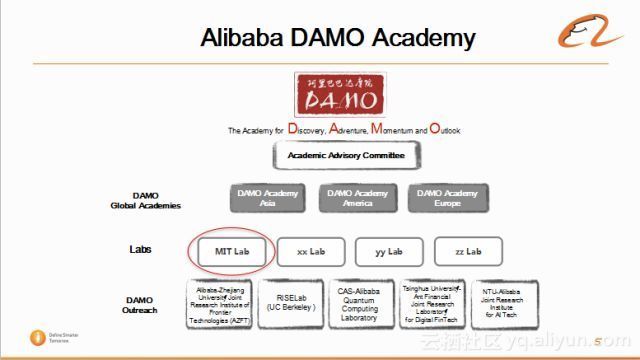
MIT实验室主要是做 人工智能领域 内的基础方面的研究。MIT实验室主要有四个团队:
语音技术团队(Speech Technologies);
自然语言处理团队(NLP):其中包括问答,情感分析,机器翻译等小团队;
图像与视频技术;
深度学习与优化技术

电商机器翻译挑战
翻译流畅度要高
如果翻译的磕磕绊绊,用户会对没有耐心看完该产品的相关信息,便查看另外的商品。如今得益于 神经网络机器翻译 的出现,使得翻译的流畅度得到飞跃式的提升,所以目标语言可读性高这项要求基本达到了满足。
关键信息翻译准确
如产品名,品牌名,购买数量及数字等信息都非常重要。如果品牌名翻译错误,便会得到商家投诉,如果商品数量错误,也会造成买家与卖家的纠纷。前段时间有一则相关新闻,挪威体育代表团想买15个鸡蛋,但是商家送来了15000个鸡蛋。
翻译速度要快
比如在高峰期,双11时期流量非常庞大,阿里翻译要求20-30词语的句子的翻译时间不能超过100毫秒的级别。假设,翻译速度达不到要求,2秒钟才出来翻译结果,买家会没有耐心等到结果出来,可能看一条同样类型的商品。导致的结果就是即使翻译准确,但是翻译还是无法给商家带来价值。
阿里采取的策略
A.数据策略
1.语料数据获取
- 从网上爬取很多平行语料数据(主要为 通用 领域数据、新闻 材料数据)
- 阿里有自己的 人工翻译 平台。收集 电商领域 数据。
人工翻译平台实际上是阿里通过 众包翻译平台 将需求放上去,外面的译员通过平台进行翻译,并获得一定的报酬。 - 商业购买数据/语料库资源交换。从学术机构单位、做翻译的单位购买/交换。
因为商业需求,目前阿里已搜集20多项语言对。中英语言对达到亿级,中法等达到千万级,一些小语种达到百万级。例如LANADA是阿里目前收购的重要东南亚电商,主要对印尼,泰国提供服务。因此翻译团队也在东南亚语言方面提供大量支持。
2.数据质量打分
打分:阿里翻译采取学术界通用的方法,如IBM model,以及基于神经网络的循环神经网络的force decoding等方法对数据进行打分。
挑选:阿里翻译同样也在使用学术界目前使用的数据挑选方法,来挑选领域相关数据,提升电商领域的翻译水平。方法包括来自数据源的信息,基于主题模型挑选方法,基于语音模型的数据挑选方法以及基于卷积神经网络的数据挑选方法。
3.多语知识图谱
因为阿里翻译需要精确翻译商品品牌名,数量等信息,所以需要建立多语言的知识图谱。阿里翻译基于阿里的知识图谱(目前大概有100亿的词条),正在进行多语言化,主要是电商领域的信息翻译成中文,英语,俄语等。这项工作正在进行过程中,还没有完全运用到系统当中。
陈博兴评价知识图谱:“目前知识图谱对于机器翻译的效果提升,没有任何帮助。”
B.模型策略
1.基于规则的机器翻译模型(RBMT)
基于规则即制订好翻译规则,根据对应,直接匹配给出输出。
优点:准确度高。
应用:在翻译数字,翻译日期,翻译地址以及翻译商品相关信息时,使用简单的规则加上cover的词典,效果非常好。
2.统计机器翻译模型(SMT)
统计机器翻译是通过对大量的平行语料进行统计分析,构建统计翻译模型,进而使用此模型进行翻译。
应用:产品标题、标签等短语/词语(各短语之间没语序,也不存在逻辑性)、产品搜索
3.神经网络机器翻译模型(NMT)
阿里翻译实现了基于循环神经网络的seq-seq模型(RNN-based seq-seq model),以及2017年刚刚推出的Transformer模型(google)。
优点:流畅高,翻译语序很好,逻辑性强。
应用:使用在20-30词语的句子的场景翻译,像产品描述,消息(买家与卖家的交流),买家的评论。
C.其他工作
1.词尾预测(Neural Inflection Prediction)
中文当中没有单复数变化,没有时态变化,但是英文里有。英语的词法还相对简单,俄罗斯语则不然,语法相当相当复杂,同一个名词,开头的词干不变,后面的词缀可以有几十种变化。这时,从中文或英文翻译成俄语,因为源语言词语没有这些词缀变化,翻译的结果同样没办法生成这些词缀变化。那俄罗斯人经常从阿里平台买东西,中文-俄语,英文-俄语的翻译需求非常大。为了解决这个问题,阿里翻译做了词尾预测这个工作,就是将俄语做词法分析,切分成词干和词尾。源语言有一个Seq,目标语言有两个Seq,预测完词干(下图模型左边),再预测词尾,这时会利用三个信息,首先是源语言的信息,然后是当前词语的词干信息,以及前面词语的词尾信息,这样就可以提高词尾预测的信息率。该项工作已经在2018年的AAAI上面发表了文章。
2.机器翻译的干预(Translation Intervention)
另一个工作是机器翻译的干预,前面提到机器翻译对于关键信息翻译准确。但是在神经网络做干预非常难,因为它不是按每个词翻译,而是将这句读下来,理解之后在用目标语言复述一遍,这时有些信息会翻译不到,因为这项技术还是有些弊端。阿里翻译将一句话的关键信息提取出来翻译,之后在目标语言中copy。Copy这项操作很简单有效,但只能解决80%的问题,而在电商领域需要解决99%的问题,甚至更高。目前阿里翻译通过与外面的大学的科研机构合作,大概解决了95%的问题,希望继续做研究,干预成功率达到99%以上。
3.分布式模型平均训练(Distributed Training with Model Average)
在上面提到过,训练语料已经达到十亿的级别,如果单用一个GPU训练无法高效地完成。这时需要使用多机多卡,将数据切分为多个块,每个GPU单独训练完得到一个模型,然后给模型做平均,再继续训练。如此,利用多机多卡就可以将训练速度得到提高。
4.解码速度优化(Inference Optimization)
阿里翻译的要求是达到(20-30词语的句子)百毫秒级别,则目前很多开源平台可能需要1到2秒的时间。与Google类似,因为阿里翻译使用的是TensorFlow,有Python代码和TensorFlow代码,前者计算在CPU中,后者在GPU中计算,阿里的策略比较简单粗暴,是将代码全部在GPU中进行计算,虽然降低了GPU使用效率,但是提高了解码速度。
5.内存优化(Memory Optimization)
还有一些内存优化工作,主要是工程方面的策略。
6. 知识库接口(Knowledge Base Enhanced NMT)
另外,前面提高利用知识库进行翻译,所以在系统中给知识库留了一个接口。因为知识库还在建设当中,目前主要用到的是术语表和双语词典等信息。这项工作是跟中科院的自动化研究团队合作的项目,如果后续有进一步的改进,会通过下面的结果加入到系统中。
WMT比赛所采用的方案
- 数据清洗和选择(Data Cleaning and Selection)
- Single system
- Weighted transformer
- Relative position for transformer
- Neural Inflection Prediction
- Translation Intervention
- Distributed Training
- Finetuning
- Ensembling
- Reranking
报告三:《小米智能问答成长之路》- 刘作鹏
背景介绍: 刘作鹏,小米AI Lab智能问答技术总监,有10多年人工智能相关工作经验。耗时一年多,从零开始为小米搭建出知识问答、知识图谱、智能客服三个系统,核心指标国内领先。2009年到2015年,任职于雅虎全球(北京)研发中心,作为雅虎&微软搜索联盟技术负责人,所承担的项目曾为雅虎带来数十亿美金的收入增长。在百度工作时间,设计并实现了凤巢的广告选择平台,成为了国内第一个日请求数突破20亿的互联网服务。
小米的智能问答服务从一个原型系统开始,经过一年多的持续演进,总结出一套面向变化的、易扩展的系统架构,很好地应对了知识规模指数级扩大、用户请求急剧增长、技术复杂度迅速提升等挑战。通过引入知识图谱和机器学习相关技术,明显提升了知识构建、问题理解、答案匹配等关键环节的效果。目前小米的智能问答分三个子系统 ,分别基于KBQA、FAQ 问答和阅读理解技术构建而成,三个子系统相互补充,也都在迅速地进化的过程中。
小米智能问答背景
起源于小米智能音箱的市场需求。
V0.1 原型
任务:一周 - 200行代码 - 能回答100个问题
收益:熟悉环境、理解问题
V0.2 模仿 - 搜索技术
任务:了解目前主流问答系统的实现方案。业界比较好的产品有哪些?如何做技术选型?
结果:形成以搜索为基础的技术方案。
主流的问答系统实现方案:
- 基于模板/规则的匹配技术
- 基于信息检索的匹配技术
- 基于深度学习模型的匹配技术
- 基于机器翻译模型的匹配技术
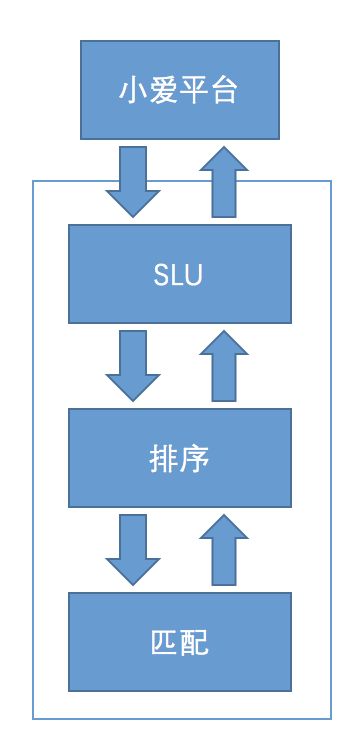
SLU:“理解”用户Query;
排序:根据NER的结果和LAT过滤,根据Jaccard相似度排序;
匹配:利用ES能力,做Lexical层面上的召回。FAQ库达到上万规模。
V0.3 借鉴 - 数据挖掘
任务:处理用户问句的多样性
举例如下:
在小米金融中,用户常用问句有:
“信用卡如何提升额度?”
“提高额度怎么办?”
“怎么提额度?”
“我想提额?”
方法:模版挖掘、同义词挖掘等
收益:挖掘的结果持续提升效果

V0.4 扩展 + 百科知识图谱
问题:除了FAQ外,还有哪些形式的知识库可以使用?
方法:构建基于百科的知识图谱
收益:开启了认知计算之路

V0.4中加入了Entity Linking:
核心任务:面向短文本的语义理解;
Rank排序:结合实体描述中的信息,与用户Mention的 上下文的综合信息判断。
V0.5 细化 + 垂域图谱
问题:人物的Query较多,如何进一步提升效果?
方法:基于百科的人物明星构建人物图谱
收益:进一步加深了对图谱能力的了解
垂域图谱的构建:
- 人物Schema构建
- 知识融合:维基百科和互动百科。类型的融合、谓词的融合、实体的融合。
- 推理与清洗:
引入TransE、TransH等基于分布式向量的表示方法;
开始尝试简单的符号推理 - 引入Neo4j:
支持更复杂的查询:“姚明的女儿有多高”
属性的查询仍然用MogoDB
工作变化:
细化了图谱的技术体系,拆分出知识图谱小组,提炼出知识图谱构建流程。
V0.6 增强 + 深度学习
问题:深度学习会起多大作用?
方法:在核心环节尝试引入深度学习,逐步验证效果
收益:全面提升了系统的问答能力
V0.7 增强 + 更多NLP
问题:如何利用到NLP领域更多更新的成果?
方法:从NLP角度理解关键问题
收益:初步确定了待突破的技术难题
主要应用:
- 复述:将问句复述,解决问句多样性
- 摘要:用 文本摘要技术 去除互联网中获得的FAQ答案中的冗余信息
- NLG:NLG即自然语言生成,来生成个性化的回复
- 情感分析:过滤考FAQ库中消极的答案
- 情绪检测:针对用户的情绪。调整回复方式
V0.8 跟踪 + 阅读理解
问题:SQuAD比赛中,机器再一次胜出,如何利用该技术?
方法:ES选段落,RNet找答案
收益:对长尾问题的回答更加准确。
V0.9 实践 + 多轮问答
确定了结合知识图谱研发新的多轮框架的思路
V1.0 发布
核心任务:以知识图谱和人机对话为基础的“海量知识”服务平台。
报告四:《自然语言处理在医疗领域的应用》 - 倪渊
背景介绍: 倪渊,博士。2003年毕业于复旦大学计算机科学与技术专业,2007年毕业于新加坡国立大学计算机系。之后加入IBM中国研究院,从事自然语言处理,知识图谱等相关领域的研究。在IBM期间,倪渊参与过著名人工智能项目沃森机器人的开发。2018年,倪渊加入平安医疗科技研究院,带领医疗文本处理团队。倪渊博士在著名国际会议,比如SIGMOD, WWW, ISWC等上,发表过20多篇文本,并且获得20多项国际专利。
医疗领域有大量需要自然语言交互的工作,耗费了大量的人力。比如诊前对于患者就诊科室以及就医流程相关问题,医院往往需要有专业的人员在门诊大厅,回答相关问题;诊后对于患者的健康咨询和随访,需要家庭医生定期上门或者电话来进行。在中国医生资源缺乏的情况下,导致医生的工作负担重而患者的管理质量低。平安医疗科技通过构建医疗知识图谱来打造医疗人工智能的大脑,并通过对话问答技术,来和患者智能交互,为患者提供智能分诊/导诊服务以及智能患教问答和随访服务。本次报告将主要介绍平安如何运用自然语言处理技术来打造智能的患者服务。
知识图谱可以非常方便的在医疗领域构建垂域的知识图谱,来明确医学知识结构,辅助医疗。
医疗知识图谱
用图谱支撑上层服务:疾病预测、智能预诊、辅助诊断、智能随访追踪
知识图谱应用从上而下,从应用出发而非从数据出发。通过结构化的形式描述客观世界中的概念以及关系。
应用
- 自然语言查询内容、医患教育、结构化标准化、决策支持
- 诊断前:通过症状、Entity linking 找到图谱中对应概念、再根据节点的权重和概率,推测可能的疾病列表
- 诊中辅助:基于患者主诉。选择相关疾病,并按节点权重进行排序
报告五:《知性会话-基于知识图谱的人机对话系统方法和实践》 - 刘升平
背景介绍: 刘升平,前IBM中国研究院资深研究员,中文信息学会语言与知识计算专委会,医疗健康与生物信息处理专委会委员。2005年获得北京大学数学学院信息科学系博士。曾在语义网,机器学习、信息检索,医学信息学等领域发表过20多篇论文。在IBM中国研究院信息与知识组工作期间,多次获得过IBM研究成就奖。目前在云知声领导NLP和智慧医疗团队,主要从事要从事自然语言理解和生成,人机对话系统,聊天机器人,知识图谱,临床辅助诊断等研发工作。
内容参考链接:
https://edu.csdn.net/huiyiCourse/detail/847?utm_source=edu_bbs_autocreate
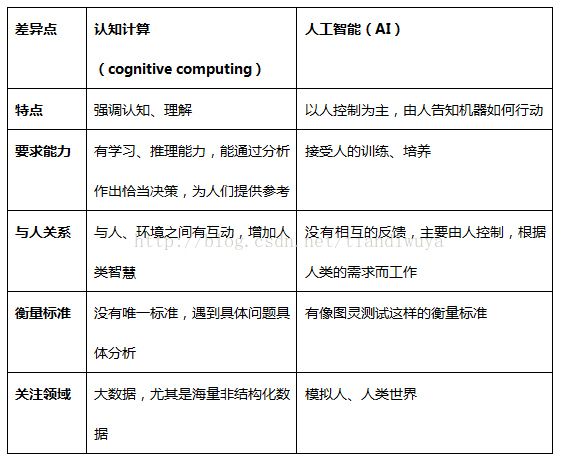
什么是认知计算?
Cognnitive computing refers to systems that learn at scale, reason with purpose and interact with humans nautally.
认知计算是一种学习系统,有规模、有原因、有目的地学会和人类交互。
与人工智能的区别:
认知计算 更强调机器的主动学习、推理、感知、理解,并与人类、环境进行交互的反应。机器通过学习形成自己的认知和理解,从而为人类决策提供建议。
人工智能 由人的控制为主,由人提供数据,告知机器如何行动,让机器系统表现得更像人,近似于人。
什么是知性会话?
知性会话是以知识图谱为中心,通过实体链接技术,融合多元知识,实现跨领域、跨交互形式的多轮对话。
特点:
1.聊天和问答交替进行,跨交互形式,共享上下文。
2.操控、聊天、问答均能体现现有领域知识,并可以基于知识驱动发起会话
参考链接:
openKG : http://openkg.cn/home
NLP : https://blog.csdn.net/Irving_zhang/article/details/69396923
TensorFLow : https://www.jianshu.com/p/2ea7a0632239