参考内容:
非常详细的TensorBoard基本解释及使用简介
TensorFlow学习笔记(6):TensorBoard之Embeddings
【Python | TensorBoard】用 PCA 可视化 MNIST 手写数字识别数据集
** TensorFlow-7-TensorBoard Embedding可视化**
在线示例
在查看Embedding时,遇到如下问题:
Error: Your browser or device does not have WebGL enabled. Please enable hardware acceleration, or use a browser that supports WebGL.

error
- 首先尝试设置firefox:
在地址栏输入about:config
找到webgl.disable设置为false
找到webgl.force-enable设置为True
但设置完后刷新页面,仍提示相同错误,因此尝试方法2。 - 通过主机Chrome浏览器访问VB虚拟机提供的Web页面:
首先设置VB网络如下所示,访问方式为NAT,点击端口转发添加一条规则。其中 主机IP 169.254.155.25是在主机系统中通过查看网络连接详细信息得到的VB IP地址,主机端口 定义为想要通过浏览器访问的端口; 子系统IP 是在VB的Ubuntu中显示的IP地址, 子系统端口 是tensorboard中设置的访问端口。确认后,允许防火墙所提示的信息即可。
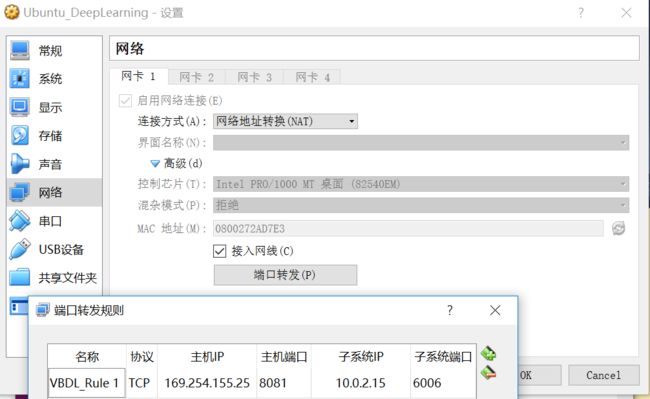 VB网络设置
VB网络设置
在主机Chrome浏览器中输入http://169.254.155.25:8081/#embeddings,即可查看embeddings信息。
PLUS:一些参数的Embedding
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import sys
import os
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.tensorboard.plugins import projector
import numpy as np
FLAGS = None
def train():
# Import data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True, fake_data=FLAGS.fake_data)
sess = tf.InteractiveSession()
# 1)
# # Create randomly initialized embedding weights which will be trained.
# D = 200 # Dimensionality of the embedding.
# embedding_var = tf.Variable(tf.random_normal([N, D]), name='word_embedding')
N = 10000 # Number of items (vocab size).
plot_array = mnist.test.images[:N] # shape: (n_observations, n_features)
np.savetxt(os.path.join(FLAGS.log_dir, 'metadata.tsv'), mnist.test.labels[:N], fmt='%d')
embedding_var = tf.Variable(plot_array, name='word_embedding')
# Create a multilayer model
# Input placeholders
with tf.name_scope('input'):
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
# We can't initialize these variables yo 0 - the network will get stuck
def weight_variable(shape):
"""Create a weight variable with appropriate initialization."""
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
"""Create a bias variable with appropriate initialization."""
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def variable_summaries(var):
"""Attach a lot of summaries to a tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses ReLU to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# Adding a name scope ensure logical grouping of grouping of the layers in the graph.
with tf.name_scope(layer_name):
# This Variable will hold the state of the weights for layer
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
with tf.name_scope('Wx_plus_b'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('pre_ativations', preactivate)
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
return activations
hidden1 = nn_layer(x, 784, 500, 'layer1')
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probalility', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)
# Do not apply softmax activation yet, see below.
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
with tf.name_scope('cross_entropy'):
# The raw formulation of cross-entropy,
#
# tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.softmax(y)), reduction_indices=[1]))
# can be numerically unstable.
#
# So here we use tf.nn.softmax_cross_entropy_with_logits on the raw outputs of the nn_layer above,
# and then average across the batch.
diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
with tf.name_scope('total'):
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('cross_entropy', cross_entropy)
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(FLAGS.learning_rate).minimize(cross_entropy)
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) # Attention: There is y_, not y
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# Merge all the summaries and write them out to /tmp/tensorflow/mnist/logs/mnist_with_summaries (by default)
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/test')
tf.global_variables_initializer().run()
# 2) Periodically save your embeddings in a LOG_DIR
saver = tf.train.Saver()
saver.save(sess, os.path.join(FLAGS.log_dir, "model.ckpt"), global_step=0)
# Train the model, and also write summaries.
# Every 10th step, measure test-set accuracy, and write test summaries
# All other steps, run train_step on training data,
def feed_dict(train):
"""Make a Tensorflow deed_dict: maps data onto Tensor placeholders."""
if train or FLAGS.fake_data:
xs, ys = mnist.train.next_batch(100, fake_data=FLAGS.fake_data)
k = FLAGS.dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k} # Attention: There is y_, not y
for i in range(FLAGS.max_steps):
if i%10 == 0: # Record summaries and test-set accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # Record train set summariess, and train
if i%100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for ', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()
# 3) Associate metadata and sprite image with your embedding
# Format: tensorflow/tensorboard/plugins/projector/projector_config.proto
config = projector.ProjectorConfig()
# You can add multiple embeddings. Here we add only one.
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
# Link this tensor to its metadata file (e.g. labels).
embedding.metadata_path = os.path.join(FLAGS.log_dir, 'metadata.tsv')
# Use the same LOG_DIR where you stored your checkpoint.
summary_writer = tf.summary.FileWriter(FLAGS.log_dir)
embedding.sprite.image_path = os.path.join(FLAGS.log_dir, 'mnist_10k_sprite.png')
embedding.sprite.single_image_dim.extend([28, 28])
# The next line writes a projector_config.pbtxt in the LOG_DIR. TensorBoard will
# read this file during startup.
projector.visualize_embeddings(summary_writer, config)
# Download img from: https://www.tensorflow.org/images/mnist_10k_sprite.png
# and put it into FLAGS.log_dir
def main(_): # Attention: There is a _ arg
if tf.gfile.Exists(FLAGS.log_dir):
tf.gfile.DeleteRecursively(FLAGS.log_dir)
tf.gfile.MakeDirs(FLAGS.log_dir)
train()
if __name__ == '__main__':
parse = argparse.ArgumentParser()
parse.add_argument('--fake_data', nargs='?', const=True, type=bool, default=False,
help='If true, uses fake data for ubit testing.')
parse.add_argument('--max_steps', type=int, default=300, #default=1000
help='Number of steps to run trainer.')
parse.add_argument('--learning_rate', type=float, default=0.01,
help='Initial learning rate')
parse.add_argument('--dropout', type=float, default=0.9,
help='Keep probability for training dropout.')
parse.add_argument(
'--data_dir',
type=str,
#default='/tmp/tensorflow/mnist/input_data',
default='MNIST_data',
help='Directory for storing input data')
parse.add_argument(
'--log_dir',
type=str,
default='/tmp/tensorflow/mnist/logs/mnist_with_summaries',
help='Summaries log directory')
FLAGS, unparsed = parse.parse_known_args()
tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
# cd --your_log_dir
# tensorboard --log_dir=yourLogDir