mysql简介-1
本篇将介绍备份恢复、主从、主主
4、mysql备份恢复
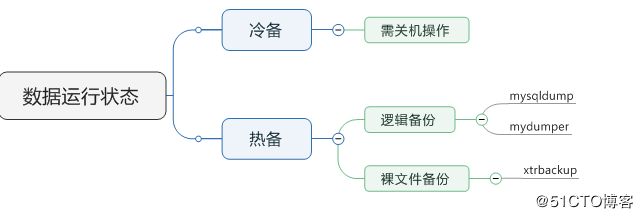
mysql备份分为冷备和热备,使用冷备需要关闭服务器,在生产绝对不建议这么操作,热备又称为逻辑备份和裸文件备份,备份文件又可以分为全备和增量备份,逻辑备份对增量备份不是特别理想。

从这里开始我们准备两台机器: 系统Cenos7.4 mysql: 5.7
4.1、mysqldump备份操作
1、全备
备份: [root@do3 tmp]# mysqldump -uroot -pxiong123 -A > 20180510.sql
恢复: [root@do3 tmp]# mysql -uroot -pxiong123 < 20180510.sql
2、备份单个库
备份: [root@do3 tmp]# mysqldump -uroot -p extmail > extmail.20180510.sql
备份文件头部: Host: localhost Database: extmail
先删除extmail这个库 mysql> drop database extmail;
恢复操作: [root@do3 tmp]# mysql -uroot -pxiong123 extmail < extmail.20180510.sql
删除数据库,直接恢复会报这个错误,我们需要先创建这个库,然后再进行恢复
ERROR 1049 (42000): Unknown database 'extmail'
完整单库恢复
mysql> create database extmail;
[root@do3 tmp]# mysql -uroot -pxiong123 extmail < extmail.20180510.sql 
3、备份库中的单个表
备份:语法: -u用户 -p密码 库名 表名
[root@do3 tmp]# mysqldump -uroot -p extmail alias > ext_alias.sql
恢复:
1、删除 mysql> drop table extmail.alias;
2、恢复 [root@do3 tmp]# mysql -uroot -pxiong123 extmail < ext_alias.sql
3、查看 mysql> use extmail;
mysql> show tables;4.2、xtrbackup
下载地址 - 点我下载 - 版本: percona-xtrabackup-24-2.4.11-1.el7.x86_64.rpm
4.2.1、功能
能实现的功能:
非阻塞备份innodb等事务引擎数据库、
备份myisam表会阻塞(需要锁)、
支持全备、增量备份、压缩备份、
快速增量备份(xtradb,原理类似于oracle:tracking 上次备份之后发生修改的page.)、
percona支持归档redo log的备份、
percona5.6+支持轻量级的backup-lock替代原来重量级的FTWRL,此时即使备份非事务引擎表也不会阻塞innodb的DML语句了、
支持加密备份、流备份(备份到远程机器)、并行本地备份、并行压缩、并行加密、并行应用备份期间产生的redo日志、并行copy-back
支持部分备份,只备份某个库,某个表
支持部分恢复
支持备份单个表分区
支持备份速度限制,指备份产生的IO速度的限制
支持point-in-time恢复
支持compat备份,也即使不备份索引数据,索引在prepare时--rebuild-indexs
支持备份buffer pool
支持单表export, import到其它库
支持 rsync 来缩短备份非事务引擎表的锁定时间4.2.1、全备
yum安装 依赖包 libev、rsync
[root@do3 tmp]# yum -y install percona-xtrabackup-24-2.4.11-1.el7.x86_64.rpm
前期准备:
1、创建一个用户备份的用户
mysql> grant replication client, reload, lock tables, process on *.* to 'xtrb'@'%' identified by 'xtrb';
mysql> flush privileges;
2、创建一个备份目录 /data/backup
[root@do3 mysql]# mkdir /data/backup
[root@do3 mysql]# chown mysql.mysql !$
3、创建一个数据库
mysql> create database test;
mysql> use test;
mysql> create table te1 (id int primary key auto_increment,name varchar(25));
mysql> insert into te1 (name) values ('xiong1'),('xddf2'),('sa3'); 
备份:
1、全备
[root@do3 mysql]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 /data/backup/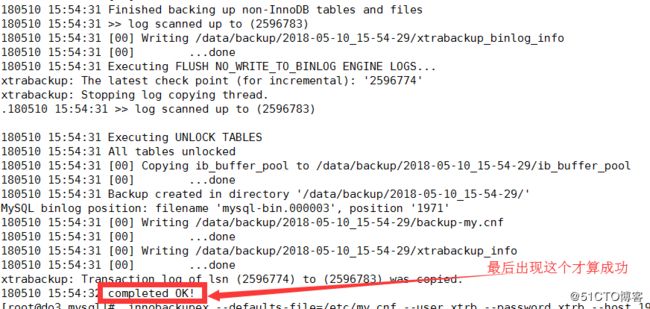
备份完成之后是直接以当前时间来命名
[root@do3 mysql]# ls /data/backup/
2018-05-10_15-54-29
以下是备份的文件,需要将属主属组设置成mysql,方便恢复
文件说明 重要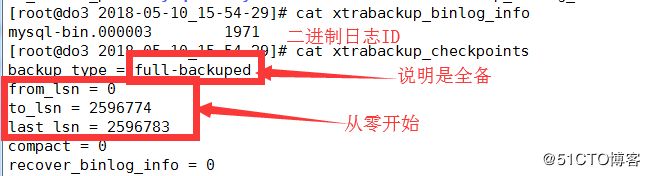

恢复操作
恢复时需要加上 --apply-log参数,它的作用是回滚未提交的事务及同步已经提交的事务至数据文件,使数据文件保持一致性;
[root@do3 2018-05-10_15-54-29]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 --apply-log /data/backup/2018-05-10_15-54-29/
出现如下信息说明成功
这时我们模拟数据挂掉了,直接干掉原先的mysql
1、先停掉它
[root@do3 2018-05-10_15-54-29]# service mysqld stop
2、弄走原先的数据文件
[root@do3 2018-05-10_15-54-29]# mv /data/mysql{,.bak}
3、恢复数据文件
[root@do3 2018-05-10_15-54-29]# pwd
/data/backup/2018-05-10_15-54-29
[root@do3 2018-05-10_15-54-29]# mkdir /data/mysql
[root@do3 2018-05-10_15-54-29]# mv * /data/mysql
[root@do3 2018-05-10_15-54-29]# chown mysql.mysql /data/mysql -R
4、启动服务
[root@do3 2018-05-10_15-54-29]# service mysqld start
5、查看数据库
mysql> show databases;
Database: test 没问题
4.2.2增量备份
1、先进行一次全备
[root@do3 backup]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 /data/backup/
2、插入新的数据
mysql> insert into test.te1 (name) values ('5sf'),('adf'),('555sf'),('3adf'),('5555sf'),('3adadf'),('55ad55sf'),('3adadaf'); 
3、增量备份
[root@do3 backup]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 --no-timestamp --incremental /data/backup/2018-05-10_16-23-27-incre-1 --incremental-basedir /data/backup/2018-05-10_16-23-27/

4、增备的恢复
4.1、先进行全备恢复
4.2、再进行增备恢复 都需要加上 --redo-only
--redo-only意味着只前滚xtrabackup日志中已经提交的事务,并不回滚那些没有提交的事务信息
4.3、最后一个过程就是对整体的全备进行恢复,这时就可以去掉--redo-only了,意味着需要回滚那些还没有提交的事务
恢复步骤:
1、全备的恢复
[root@do3 backup]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 --apply-log --redo-only /data/backup/2018-05-10_16-23-27
xtrabackup: starting shutdown with innodb_fast_shutdown = 1
InnoDB: Starting shutdown...
InnoDB: Shutdown completed; log sequence number 2597453
InnoDB: Number of pools: 1
180510 16:41:43 completed OK!
2、增备的恢复
[root@do3 backup]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 --apply-log --redo-only /data/backup/2018-05-10_16-23-27 --incremental-dir=/data/backup/2018-05-10_16-23-27-incre-1/
180510 16:42:43 [00] ...done
180510 16:42:43 [00] Copying /data/backup/2018-05-10_16-23-27-incre-1//xtrabackup_info to ./xtrabackup_info
180510 16:42:43 [00] ...done
180510 16:42:43 completed OK!
3、整体的全备恢复不加--redo-only
[root@do3 backup]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 --apply-log /data/backup/2018-05-10_16-23-27
xtrabackup: using the following InnoDB configuration for recovery:
xtrabackup: innodb_data_home_dir = .
xtrabackup: innodb_data_file_path = ibdata1:12M:autoextend
xtrabackup: innodb_log_group_home_dir = .
xtrabackup: innodb_log_files_in_group = 2 2个文件
xtrabackup: innodb_log_file_size = 50331648 可以看到日志文件大小
InnoDB: FTS optimize thread exiting.
InnoDB: Starting shutdown...
InnoDB: Shutdown completed; log sequence number 2608421
180510 16:43:51 completed OK!
4、测试恢复过程
[root@do3 data]# cd /data
[root@do3 data]# service mysqld stop
[root@do3 data]# mv mysql{,.bak}
[root@do3 data]# mkdir mysql
[root@do3 data]# mv backup/2018-05-10_16-23-27/* mysql/
[root@do3 data]# chown mysql.mysql mysql -R
[root@do3 data]# service mysqld start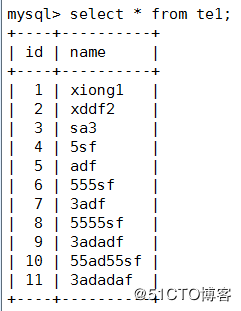
5、主从复制
主从复制有默认的异步复制,半同半复制,5.6新增的GTID复制,5.7的多源复制,基于组提交的并行复制和增强半同步复制功能
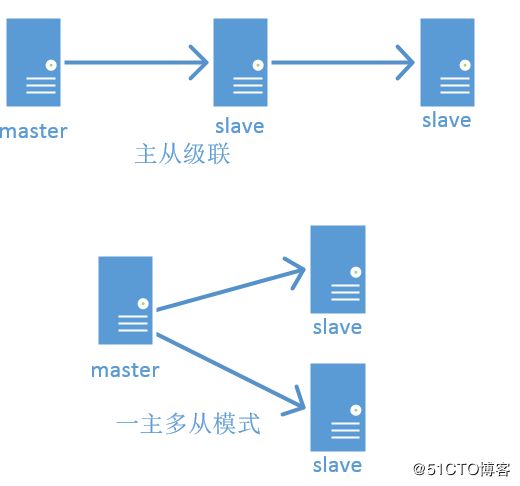
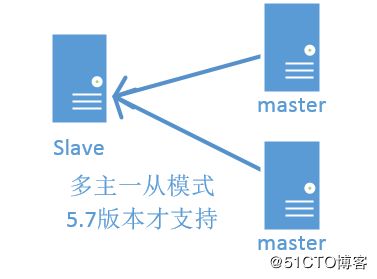
5.1、常见的主从架构模式

5.2、主从架构
基本原理:当主从建立连接后,从会生成两个线程IO Thread和sql thread , io线程会去请求主库的bin log日志, 并将得到的二进制日志会保存到自己的 中继日志中,然后sql thread会将中继日志中的sql解析成具体语句,主库会生成一个IO dump线程用于给从库IO thread发送bin log;
配置参数说明:
log-bin: 二进制日志,主从必须开启
server-id: 同一主从ID必须不一致
read-only:设置从库为只读,5.6上mysql root还是能对其进行操作,5.7上新增了一个super_read_only参数,开启后超管也没有权限进行写入操作
binlog_format:二进制日志的格式必须使用ROW模式
log_slave_updates:作用是将从master服务器上获取数据变更的信息记录到从服务器的二进制日志文件中
binlog-do-db:使用可选复制数据库 比如binlog-do-db=test,那么从库只能复制test这个库
binlog-ignore-db:忽略某个库
ralay_log_purge:清除已经执行过的relay log 建议从库开启5.3、异步复制
原理:主库写入binlog日志后即可成功返回客户端,无须等待binlog日志传递给从库的过程 ,一旦主库发生宕机就有可能出现丢失数据的情况。
前期准备:
系统:centos 7.4 mysql:5.7
IP: 192.168.9.224 (master)
192.168.9.225 (slave)
两台机器都需要开启
log_bin=mysql-bin # 二进制以及二进制日志格式
binlog_format=ROW
slow_query_log=ON # 慢日志
explicit_defaults_for_timestamp=1
log_queries_not_using_indexes=ON
主配置准备:
master server_id=111
从配置准备:
slave server_id=222
log_slave_updates=1
super_read_only=1
主库上创建一个用户
mysql> grant replication slave on *.* to 'repl'@'%' identified by 'repl';
mysql> flush privileges;
主库上使用innobackup备份数据库
[root@do3 data]# innobackupex --defaults-file=/etc/my.cnf --user xtrb --password xtrb --host 192.168.9.224 --no-timestamp /data/backup/20180510_all
[root@do3 backup]# tar zcf 20180510_all.tar.gz 20180510_all/
[root@do3 backup]# scp 20180510_all.tar.gz [email protected]:/tmp/
从库上操作
[root@do4 mysql]# mkdir /data/back
[root@do4 mysql]# chown mysql.mysql !$ -R
[root@do4 mysql]# cd /data/back/
[root@do4 back]# mv /tmp/20180510_all.tar.gz .
[root@do4 back]# tar xf 20180510_all.tar.gz
[root@do4 back]# innobackupex --defaults-file=/etc/my.cnf --user root --password xiong123 --apply-log /data/back/20180510_all
# 将初始的迁走, 因为需要跟主的position保持一致,数据库必须配置前同步
[root@do4 back]# mv /data/mysql{,.bak}
[root@do4 back]# mkdir /data/mysql
[root@do4 back]# mv 20180510_all/* /data/mysql/
[root@do4 back]# chown mysql.mysql !$ -R
chown mysql.mysql /data/mysql/ -R
[root@do4 back]# service mysqld start
查看主二进制日志ID
此时从库上配置
mysql> CHANGE MASTER TO
-> MASTER_HOST="192.168.9.224",
-> MASTER_USER='repl',
-> MASTER_PASSWORD='repl',
-> MASTER_PORT=3306,
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=589;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
插入数据测试
从库查询
mysql> select * from test.te1;
| 12 | sdd |
| 13 | sdd2 |
| 14 | sdd3 |
+----+----------+主从管理命令:
show slave status\G : 在从库上查看主从复制状态
show master status: 查看主库的binlog文件和position位置,以及开启GTID模式下记录的gid
change master to:在从库上配置主从过程
start slave:开启主从同步
stop slave:关闭主从同步
reset slave all: 清空从库的所有配置信息5.4、半同步复制
原理:mysql5.5版本之后引入了半同步复制功能,主从服务器必须同时安装半同步复制插件才能开启该功能, 确保从库接收到主库传递过来的binlog内容已经写入了自己 的relay log里面,才会通知主库上面的等待线程,该操作完毕,如果超时,超过rpl_semi_sync_master_timeout参数设置的时间,则关闭半同步,并自动切换为异步复制模式,直到至少有一台从库通知主库已经接收binlog信息为止。
半同步安装
在安装目录的/usr/local/mysql/lib/plugin中就能查看 到
semisync_master.so和semisync_slave.so
主库安装:
mysql> install plugin rpl_semi_sync_master soname "semisync_master.so"
查看安装之后多的功能
开启半同步,配置文件中也需要添加 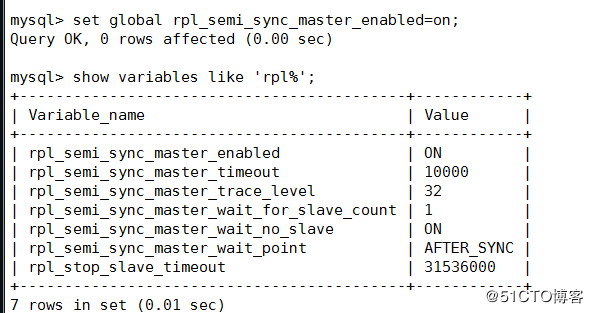
查看是否已加载半同步
从库安装
注意:安装的时候我们使用过super_read_only=1 所以需要先关闭从库,然后再配置,配置 完之后记得配置文件也要修改一下,然后再重启从库
super_read_only=1
rpl_semi_sync_slave_enabled=ON主库中查看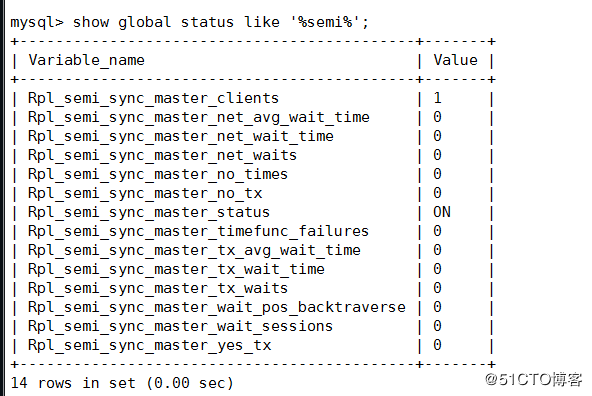
Rpl_semi_sync_master_clients: 连接客户端
Rpl_semi_sync_master_status: 主的状态为开启
Rpl_semi_sync_master_no_tx: 代表没有成功接收slave提交的次数
Rpl_semi_sync_master_yes_tx: 代表成功接收slave提交的次数插入一条数据,平均时间等待时间292毫秒,成功接收slave次数
5.5、GTID说明与配置
GTID又叫全局事务ID,是一个已提交事务的编号,并且是一个全局唯一的编号,MYSQL5.6在主从复制类型上新增的GTID复制。
GTID存在的价值
1) GTID使用 master_auto_position=1代替了基于binlog和position号的主从复制搭建方式 ,更便于主从复制的搭建;
2) GTID可以知道事务在最开始是在哪个实例上提交的;
3) GIT方便实现主从之间的failover,再也不用不断去找position和binlog了
主从复制中GTID的管理与维护
它不在利用传统复制模式的binlog文件和position号了,而是在从库" change master to "时使用 " master_auto_position=1"的方式进行搭建;
主库配置
log_bin=mysql-bin
server_id=111
slow_query_log=ON
log_queries_not_using_indexes=ON
rpl_semi_sync_master_enabled=ON
gtid_mode=on
enforce_gtid_consistency=on
从库配置
log_bin=mysql-bin
server_id=222
slow_query_log=ON
explicit_defaults_for_timestamp=1
log_queries_not_using_indexes=ON
log_slave_updates=1
super_read_only=1
rpl_semi_sync_slave_enabled=ON
gtid_mode=on
enforce_gtid_consistency=on
如果是新的主从,那么需要先将主库备份,直接利用 innobackup 这个工具备份就行重新启动会发现没有gtid信息
我们此时插入一句SQL
f1bab9f0-542e-11e8-a5af-0050568a0453:1
前一半是server_uuid 后面是 事务ID 事务ID是系统顺序分配一个不会重复的ID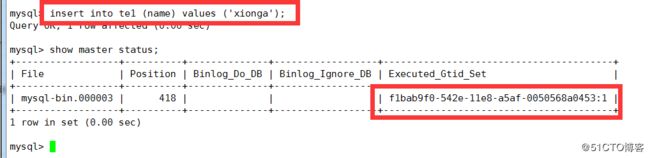
插入二条,会发现最后会跟一个 2 3,这是事务的插入条目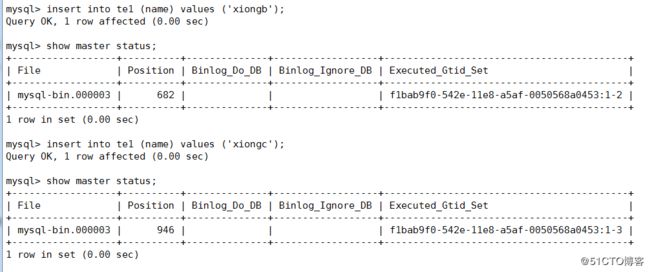
此我们在从库上进行操作
使用 show slave status可查看到接收到的gtid(Retrieved_Gtid_Set)和执行的gitd(Executed_Gtid_Set)
此时我们先停止从库的主从复制
1、停止从库的主从复制
stop slave
2、调整为传统复制模式,也就是异步模式
mysql> set global rpl_semi_sync_master_enabled=off; 这里是主
mysql> set global rpl_semi_sync_slave_enabled=0; 这里是从
3、确保从库Ongoing_anonymous_transaction_count=0 ,如果为0,意味着没有等待的事务,就可以进行下一步操作了。
mysql> show global status like 'ong%';
+-------------------------------------+-------+
| Variable_name | Value |
+-------------------------------------+-------+
| Ongoing_anonymous_transaction_count | 0 |
+-------------------------------------+-------+
1 row in set (0.00 sec)
4、在从服务器上配置
mysql> change master to MASTER_HOST="192.168.9.224",
-> MASTER_USER='repl',
-> MASTER_PASSWORD='repl',
-> MASTER_AUTO_POSITION = 1,
-> MASTER_LOG_FILE='mysql-bin.000003',
-> MASTER_LOG_POS=946;
ERROR 1776 (HY000): Parameters MASTER_LOG_FILE, MASTER_LOG_POS, RELAY_LOG_FILE and RELAY_LOG_POS cannot be set when MASTER_AUTO_POSITION is active.报这个错误是因为它的确存在,不用管它,我们直接继续
mysql> change master to master_auto_position=1;
Query OK, 0 rows affected (0.00 sec)
5、启动从服务
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
此时接收到的GTID显示为空,我们在主服务器上先插入一条数据然后再看![]()
主上操作
mysql> insert into test.te1 (name) values ('xxxa');
Query OK, 1 row affected (0.00 sec)我们在来查看从是否已经接收 show slave status\G; 切换成功。
GTID使用中的限制条件
1)GTID复制是针对事务来说的,一个事务只对应一个ID
2)不能使用 create table table_name select * from table_name
3)在一个事务中即包含事务表的操作又包含非事务表
4)不支持CREATE TEMPORARY TABLE or DROP TEMPORARY TABLE语句操作
6、MHA
6.1、组成
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。
MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
6.2、架构说明
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从
6.3、MHA原理
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;6.4、安装及环境介绍
环境说明
系统: Centos 7.4
mysql: 5.7
master 192.168.9.223 mha maser node 数据节点、主节点
slave1 192.168.9.224 mha node 数据节点
slave2 192.168.9.225 mha master node 数据节点、主节点
版本:mha4mysql-manager-0.56 mha4mysql-node-0.561、安装
3台机器安装,都直接用脚本刷 ,Mysql太大 自行从官网下载吧
[root@do3 tmp]# mkidr mysql && cd mysql
[root@do3 mysql]# cat install.sh
#!/bin/bash
#
file_path=$(cd $(dirname "$0");pwd)
mysql_version="mysql-5.7.22-linux-glibc2.12-x86_64.tar.gz"
# 创建用户并让其不能登陆系统
useradd -u 3010 mysql -s /sbin/nologin
# 如果存在,需要先卸载
[ -d /usr/local/mysql ] && echo "mysql已存在" && exit 5
# 安装
tar xf ${file_path}/${mysql_version} -C /usr/local
ln -sv /usr/local/mysql-5.7.22-linux-glibc2.12-x86_64 /usr/local/mysql
# 基础配置
mkdir /data/mysql -p
# 环境变量配置
echo "export PATH=/usr/local/mysql/bin/:\${PATH}" > /etc/profile.d/mysql.sh
source /etc/profile.d/mysql.sh
/usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql --datadir=/data/mysql/
# 将属主属组改为mysql
chown mysql.mysql /data/mysql -R
chown mysql.mysql /usr/local/mysql -R
# 生成一个四位数的server_id
num=`echo ${RANDOM} | head -c 4`
mv /etc/my.cnf{,.bak}
cp -i ${file_path}/my.cnf /etc/
cp -i ${file_path}/mysqld /etc/init.d
chmod +x /etc/init.d/mysqld
sed -i "s/server_id=SERVER_IDS/server_id=${num}/gi" /etc/my.cnf
service mysqld start
解压 复制到三台机器中,配置文件及启动文件
链接:https://pan.baidu.com/s/1EmViKfNov4l8cDjXRRT-Xw 密码:bkjt2、密码修改
安装完之后会有初始密码这行
2018-05-11T08:19:08.803853Z 1 [Note] A temporary password is generated for root@localhost: 7x,#TCgTO&if
如果出现这个是因为,配置文件中设置了只读权限
ERROR 1290 (HY000): The MySQL server is running with the --super-read-only option so it cannot execute this statement
super_read_only=1 改为0或者注释它 重启mysql
三台都是一样,实验环境
mysql> alter user 'root'@'localhost' identified by 'xiong123';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
3、双机互信
三台机器都得互相连接,223到22{4,5} , 224到22{3,5}, 225到22{3,4}
[root@do2 mysql]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
[root@do2 mysql]# cat ~/.ssh/id_dsa.pub > ~/.ssh/authorized_keys
[root@do2 mysql]# scp ~/.ssh/authorized_keys [email protected]:~/.ssh/
[root@do2 mysql]# scp ~/.ssh/authorized_keys [email protected]:~/.ssh/
[root@do2 mysql]# scp ~/.ssh/authorized_keys [email protected]:~/.ssh/4、主从配置
我们这里直接使用GTID+row方式+半同步
配置项 不在摘出,请网盘下载,server_id一定要不一致
主上配置,新增一个用于主从复制的用户
mysql> grant replication slave on *.* to 'repl'@'%' identified by 'repl';
添加一个mha的监控用户
mysql> grant all on *.* to 'mhatest'@'192.168.9.%' identified by 'mhatest';
加载半同步的功能
mysql> install plugin rpl_semi_sync_master soname "semisync_master.so"
配置文件需要加上 rpl_semi_sync_master_enabled=ON
临时让它生效不重启 set global rpl_semi_sync_master_enabled=ON
使用mysql> show variables like 'rpl%'; 查看
从上配置 加载半同步,然后开启它 注意配置文件也需要更改
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.00 sec)
mysql> set global rpl_semi_sync_slave_enabled=on;
Query OK, 0 rows affected (0.00 sec)
mysql> change master to MASTER_AUTO_POSITION = 1,
-> MASTER_HOST='192.168.9.223',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='repl',
-> MASTER_PORT=3306;
两个从还是得加上这两行:
super_read_only=1
rpl_semi_sync_slave_enabled=on
查看从状态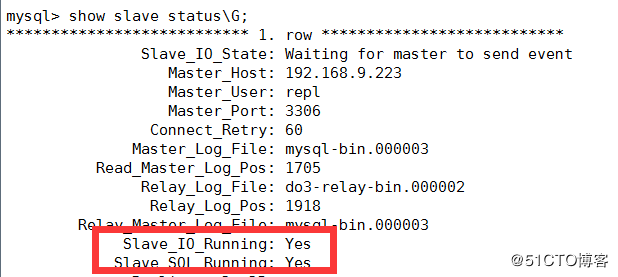
查看主连接了几台从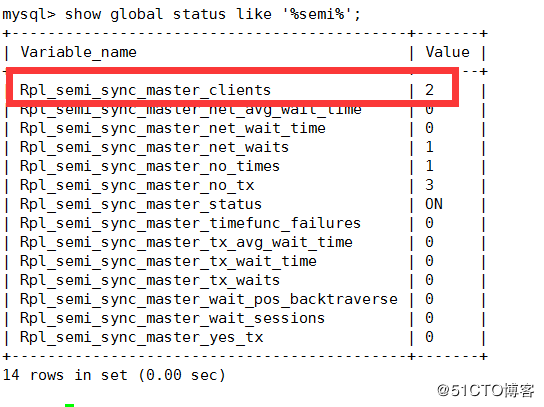
5、MHA配置
1、安装插件包
yum install perl-DBD-MySQL -y
2、安装node节点
2.1、先把文件复制过去
[root@do2 ~]# cat ssh.sh
#!/bin/bash
#
file=mha.tar.gz
ip="192.168.9"
for i in {224..225};do
scp ${file} root@${ip}.${i}:/tmp
ssh root@${ip}.${i} tar xf /tmp/${file} -C /tmp
ssh root@${ip}.${i} ls /tmp/mha
done
2.2、安装node
[root@do2 mha]# cat node_install.sh 需要重新手写三次的事,直接用脚本刷
#!/bin/bash
#
filepath=$(cd $(dirname $"0");pwd)
yum instal cpan perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker -y
node=mha4mysql-node-0.56.tar.gz
tar xf ${filepath}/${node} -C /tmp
cd /tmp/mha4mysql-node-0.56
perl Makefile.PL
make && make install
出现下方这个就说明数据节点安装成功了。
2.3、安装管理节点 数据节点上安装,懒得每台敲 直接脚本刷
[root@do4 mha]# cat manage_install.sh
#!/bin/bash
#
filepath=$(cd $(dirname $"0");pwd)
yum install perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes -y
node=mha4mysql-manager-0.56.tar.gz
tar xf ${filepath}/${node} -C /tmp
cd /tmp/mha4mysql-manager-0.56
perl Makefile.PL
make && make install
工具包位置
5、工具包功能介绍
**Manager工具包**
# masterha_check_ssh 检查MHA的SSH配置状况
# masterha_check_repl 检查MySQL复制状况
# masterha_manger 启动MHA
# masterha_check_status 检测当前MHA运行状态
# masterha_master_monitor 检测master是否宕机
# masterha_master_switch 控制故障转移(自动或者手动)
# masterha_conf_host 添加或删除配置的server信息
**Node工具包**(这些工具通常由MHA Manager的脚本触发,无需人为操作)
# save_binary_logs 保存和复制master的二进制日志
# apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
# filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
# purge_relay_logs 清除中继日志(不会阻塞SQL线程)6、配置文件
mha有提供vip地址漂移等各类
-rwxr-xr-x 1 root root 3443 Jan 8 2012 master_ip_failover #自动切换时vip管理的脚本,不是必须
-rwxr-xr-x 1 root root 9186 Jan 8 2012 master_ip_online_change #在线切换时vip的管理,不是必须,同样可以可以自行编写简单的shell完成
-rwxr-xr-x 1 root root 11867 Jan 8 2012 power_manager #故障发生后关闭主机的脚本,不是必须
-rwxr-xr-x 1 root root 1360 Jan 8 2012 send_report #因故障切换后发送报警的脚本,不是必须,可自行编写简单的shell完成。
[root@do4 bin]# ls /tmp/mha4mysql-manager-0.56/samples/conf/
app1.cnf masterha_default.cnf
# 复制配置文件
[root@do4 bin]# mkdir /etc/mya
[root@do4 bin]# cd !$
[root@do2 mha]# cp /tmp/mha4mysql-manager-0.56/samples/conf/app1.cnf /etc/mha/
配置 先弄一版本简单的 让它先跑起来
[server default]
manager_workdir=/var/log/masterha/app1.log //设置manager的工作目录
manager_log=/var/log/masterha/app1/manager.log //设置manager的日志
master_binlog_dir=/data/mysql //设置master 保存binlog的位置
user=mhatest //设置监控用户root
password=mhatest
ping_interval=1 //设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp //设置远端mysql在发生切换时binlog的保存位置
repl_password=repl //设置复制环境中的复制用户名
repl_user=repl
ssh_user=root //设置ssh的登录用户名
[server1]
hostname=192.168.9.223
port=3306
[server2]
hostname=192.168.9.224
port=3306
[server3]
hostname=192.168.9.225
port=3306
candidate_master=1
//设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
----------------------------------------------------------------------------------------------------
使用mastermha_check_ssh检查ssh连接是否正常,这里一定要双机互信,每台机器都必须能通 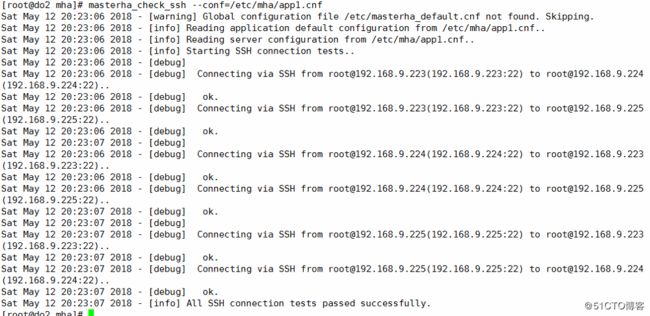
检查整个集群的状态是否OK
[root@do2 mha]# masterha_check_repl --conf=/etc/mha/app1.cnf 
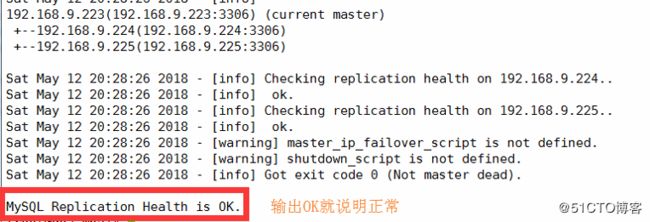
7、启动mha
只需要启动主数据节点,另一台主节点不需要启动
masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_laster_failover < /dev/null > /var/log/masterha/app1/manager.log 2>&1
--remove_dead_master_conf 该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。
--manger_log 日志存放位置
--ignore_last_failover 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。该参数代表忽略上次MHA触发切换产生的文件,\
默认情况下,MHA发生切换后会在日志目录,也就是上面我设置的/data产生app1.failover.complete文件,下次再次切换的时候如果发现该目录下存在该文件将不允许触发切换,除非在第一次切换后收到删除该文件,\
为了方便,这里设置为--ignore_last_failover。
查看日志
[root@do2 mha]# tail -f /var/log/masterha/app1/manager.log
192.168.9.223(192.168.9.223:3306) (current master)
+--192.168.9.224(192.168.9.224:3306)
+--192.168.9.225(192.168.9.225:3306)
Sat May 12 20:41:10 2018 - [warning] master_ip_failover_script is not defined.
Sat May 12 20:41:10 2018 - [warning] shutdown_script is not defined.
Sat May 12 20:41:10 2018 - [info] Set master ping interval 1 seconds.
Sat May 12 20:41:10 2018 - [warning] secondary_check_script is not defined. It is highly recommended setting it to check master reachability from two or more routes.
Sat May 12 20:41:10 2018 - [info] Starting ping health check on 192.168.9.223(192.168.9.223:3306)..
Sat May 12 20:41:10 2018 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond..
此时我们关闭这台主数据库节点
[root@do2 mha]# service mysqld stop
查看日志发现已经成功切换到 9.225上
此时我们找一台从节点,发现已经成功切换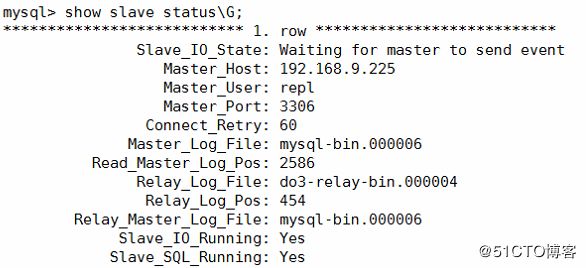
如果这台挂掉的mysql起来,
1、那么只能是手动切换连接到那台新主上;
2、将其它节点下线。