背景:
某业务系统中,同一天产生多次excel导出请求,excel数据需要通过查表获取,由于数据量过大,导致了OutOfMemoryError
事先在服务启动脚本中已设置OOM异常触发堆快照参数及GC详情打印参数:-XX:+PrintGCTimeStamps -XX:+PrintHeapAtGC -XX:+HeapDumpOnOutOfMemoryError,已知为该服务环境分配的jvm内存为6G,所以在事故发生后,我们可以得到gc.log和heapDump.hprof文件来进行分析
堆快照分析:
通过MAT(eclipse memory analyser)分析堆快照

线程http-bio-8443-exec-2的Retained Heap,即持有资源约为3.5g左右,加上jdbc结果集对象、数据库连接池对象等,占据6g左右空间,而JVM最大空间为6g,所以OOM也是情理之中

到这里我们得到的线索是:2号线程及数据查询相关对象均持有非常多的资源,那么这个资源具体对应什么内容,我们查看mat持有树便可发现
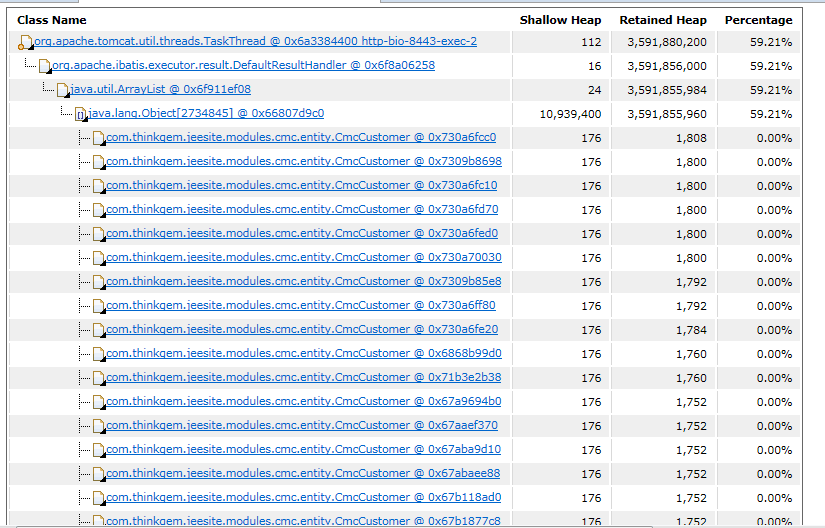
线程中存在着海量的CmcCustomer对象,每个对象占用1到2K空间,mat还为我们提供了OOM时的一些日志信息,我们可以查找一下什么方法创建了这么多对象
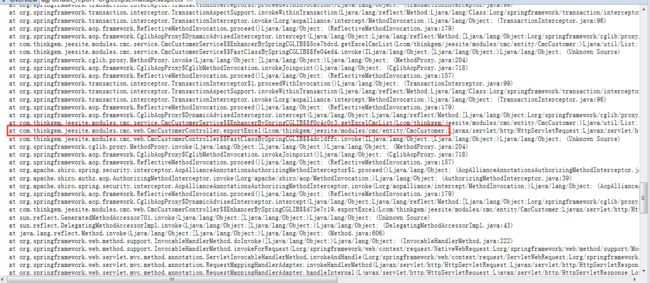
CmcCustomer对象为cmc下的一个pojo,那么我们可以初步推断:exportExcel方法需要返回一个excel,excel所需的数据需要在数据库中查询业务所需的CmcCustomer表数据,但负责此请求的2号线程持有的该对象量过大,导致在该方法执行过程中需要分配更多空间时,没有了足够空间可以分配,导致了OutOfMemoryError
至此,我们通过堆快照分析,得到了"exportExcel方法引起OOM"的初步结论,那么这个方法就是OOM的罪魁祸首吗?现场还有一条gc.log的线索,我们可以通过GC日志来分析OOM的形成原因。
GC日志分析:
在实时打印的gc日志中,我们先分析一段事故发生前的gc信息
{Heap before GC invocations=6425 (full 29):
par new generation total 699072K, used 358594K [0x0000000660000000, 0x00000006a0000000, 0x00000006a0000000)
eden space 349568K, 100% used [0x0000000660000000, 0x0000000675560000, 0x0000000675560000)
from space 349504K, 2% used [0x0000000675560000, 0x0000000675e30aa0, 0x000000068aab0000)
to space 349504K, 0% used [0x000000068aab0000, 0x000000068aab0000, 0x00000006a0000000)
137826.671: [GC137826.671: [ParNew: 358594K->9042K(699072K), 0.0174300 secs] 3006268K->2656717K(5941952K), 0.0176250 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
Heap after GC invocations=6426 (full 29):
par new generation total 699072K, used 9042K [0x0000000660000000, 0x00000006a0000000, 0x00000006a0000000)
eden space 349568K, 0% used [0x0000000660000000, 0x0000000660000000, 0x0000000675560000)
from space 349504K, 2% used [0x000000068aab0000, 0x000000068b384950, 0x00000006a0000000)
to space 349504K, 0% used [0x0000000675560000, 0x0000000675560000, 0x000000068aab0000)
concurrent mark-sweep generation total 5242880K, used 2647675K [0x00000006a0000000, 0x00000007e0000000, 0x00000007e0000000)
concurrent-mark-sweep perm gen total 524288K, used 75286K [0x00000007e0000000, 0x0000000800000000, 0x0000000800000000)
}
这是一次gc,下一次gc与其间隔500s,均是新生代并行回收,新生代分配了1G空间,eden区达到350M左右,survivor区空间均充足,回收后新生代仅剩余9M左右空间,效果明显,老年代分配了5G空间,使用空间保持在2.6G左右,永久代空间更加充裕,500M空间仅使用70M左右。
接下来我们定位到excel的导出方法
2017-08-02 18:22:40,141 INFO [jeesite.modules.cmc.web.CmcCustomerController] - 导出指定时间段内的数据到Excel
2017-08-02 18:22:40,142 DEBUG [modules.cmc.dao.CmcCustomerDao.getExcelCmcList] - ==> Preparing: SELECT 篇幅关系此处省略查询字段 WHERE a.del_flag = ? AND a.create_date > concat(?," ","00:00:00") AND a.create_date < concat(?," ","23:59:59") ORDER BY a.pid DESC
2017-08-02 18:22:40,142 DEBUG [modules.cmc.dao.CmcCustomerDao.getExcelCmcList] - ==> Parameters: 0(String), 2017-04-17(String), 2017-07-31(String)
=>18:22分,查询了2017-04-17至2017-07-31的CmcCustomer数据,开始后,gc日志如下
{Heap before GC invocations=1454 (full 192):
par new generation total 699072K, used 699071K [0x0000000660000000, 0x00000006a0000000, 0x00000006a0000000)
eden space 349568K, 100% used [0x0000000660000000, 0x0000000675560000, 0x0000000675560000)
from space 349504K, 99% used [0x0000000675560000, 0x000000068aaaffe8, 0x000000068aab0000)
to space 349504K, 0% used [0x000000068aab0000, 0x000000068aab0000, 0x00000006a0000000)
202585.700: [Full GC202585.700: [CMS202589.173: [CMS-concurrent-mark: 3.507/3.509 secs] [Times: user=3.56 sys=0.00, real=3.51 secs]
(concurrent mode failure): 5242879K->5242879K(5242880K), 14.3420460 secs] 5941951K->5936395K(5941952K), [CMS Perm : 74280K->74274K(524288K)], 14.3421470 secs] [Times: user=14.35 sys=0.00, real=14.34 secs]
Heap after GC invocations=1455 (full 193):
par new generation total 699072K, used 693515K [0x0000000660000000, 0x00000006a0000000, 0x00000006a0000000)
eden space 349568K, 99% used [0x0000000660000000, 0x000000067555ffb8, 0x0000000675560000)
from space 349504K, 98% used [0x0000000675560000, 0x000000068a542fe8, 0x000000068aab0000)
to space 349504K, 0% used [0x000000068aab0000, 0x000000068aab0000, 0x00000006a0000000)
concurrent mark-sweep generation total 5242880K, used 5242879K [0x00000006a0000000, 0x00000007e0000000, 0x00000007e0000000)
concurrent-mark-sweep perm gen total 524288K, used 74274K [0x00000007e0000000, 0x0000000800000000, 0x0000000800000000)
}
202600.077: [Full GC202600.077: [CMS: 5242879K->5242879K(5242880K), 8.9369500 secs] 5941951K->5936519K(5941952K), [CMS Perm : 74277K->74277K(524288K)], 8.9370540 secs] [Times: user=8.95 sys=0.00, real=8.93 secs]
我们可以发现:
1.两次gc间隔时间仅为5秒钟
2.gc发生时,eden区、survivor区均爆满,而且回收后仅回收了1%
3.老年代空间未见减少,停留在5242879K
4.cms收集器发生了concurrent mode failure-并发模式失败(发生的原因一般是CMS正在进行,但是由于老年代空间内存不足,需要尽快回收老年代里死的java对象,这个时候需要触发full gc,停止所有的java线程,同时终止CMS)。
篇幅原因在此不列出后续所有gc日志,本次gc是第192次,但是在OutOfMemory发生时,gc执行到了第597次,并且均为"cms回收->被阻断concurrent mode failure->full gc"的循环,而且老年代始终未见减少,直到最后一次请求分配空间,并且没有空间可分配,JVM也无法再回收,在这种情况下产生了内存溢出。
到这里,结论慢慢清晰,exportExcel方法产生太多的对象,占满了新生代、老年代空间,JVM也无法回收更多对象。但是有一点不知道有没有引起大家的好奇——老年代是什么时候变的这么大了?在之前正常回收的日志中,老年代使用空间只有2.6g左右,即使峰值也不到4g,就被JVM回收掉了,而现在使用空间已经到了阈值。下面这个图模拟了老年代已使用空间随gc次数的变动

导出excel动作在事故发生日发生多次,但时间范围为当天的查询请求中,数据量不小,但是JVM还是可以支撑,只是新生代gc频繁,效果如上图(左)所示;但发生OOM的那次请求中,时间起止范围在100天左右,数据量非常之大,新生代不断产生海量对象,survivor区瞬间达到最大值,eden区跳过survivor区进入老年代的对象非常多,即使JVM仍在gc,但是回收的效率低于对象增长的速度,那么就会产生上图(右)的现象,CMS收集器无法进行,full gc强制进行,系统停顿时间暴增,直至新生代、老年代占用空间均达到峰值,JVM再无可分配空间,游戏结束。
总结:
通过堆快照、GC日志的分析,我们得到了最终的结论:问题确实出在excel导出方法,这个方法在内存中一次性加载的数据量太过庞大,虽然不是立即发生GC,但是新对象的不断堆积最终还是压垮JVM发生了内存溢出,这是一种典型的内存溢出问题。
一、查询开始后,对象的创建过程,
解决:
1.分配更大的JVM内存空间,但不推荐,目前系统流量不大,扩大空间只是缓兵之计,假如后期推广开始,100个人同时导出excel,总不能扩大100倍的内存,这会造成资源的浪费
2.优化业务流程,每日凌晨定时生成当日excel数据,用户若有需求,可以异步推送到其用户空间,但这种方式等于修改了产品层面内容,代价比较大
3.将导出excel改为写入csv,这样就通过流输出解决了创建超大excel的问题,用户可以通过excel打开csv数据;而由于是流输出,我们也可以利用游标的思想,进行流式读取,如利用MyBatisCursorItemReader:
static void testCursor1() throws UnexpectedInputException, ParseException, Exception {
try {
Mapparam = new HashMap();
AccsDeviceInfoDAOExample accsDeviceInfoDAOExample = new
AccsDeviceInfoDAOExample();
accsDeviceInfoDAOExample.createCriteria().
andAppKeyEqualTo("12345").andAppVersionEqualTo("5.7.2.4.5").
andPackageNameEqualTo("com.test.zlx");
param.put("oredCriteria", accsDeviceInfoDAOExample.getOredCriteria()); // 设置参数
myMyBatisCursorItemReader.setParameterValues(param); // 创建游标
myMyBatisCursorItemReader.open(new ExecutionContext()); //使用游标迭代获取每个记录
Long count = 0L;
AccsDeviceInfoDAO accsDeviceInfoDAO;
while ((accsDeviceInfoDAO = myMyBatisCursorItemReader.read()) != null) {
System.out.println(JSON.toJSONString(accsDeviceInfoDAO));
++count;
System.out.println(count);
}
} catch (Exception e) {
System.out.println("error:" + e.getLocalizedMessage());
} finally { // do some
myMyBatisCursorItemReader.close();
}
}
MyBatisCursorItemReader注入:
mapper.xml中再手动为sql加入fetchSize=-2147483648来配置JDBC的流式抓取,对这个配置感兴趣的同学可以参考此文章, 这种方式返回了操作ResultSet的游标让用户自己迭代获取数据,我们也可以使用Mybatis的ResultHandler,内部直接操作ResultSet逐条获取数据并调用回调handler的handleResult方法进行处理
static void testCursor2() {
SqlSession session = sqlSessionFactory.openSession(); Mapparam = new HashMap();
AccsDeviceInfoDAOExample accsDeviceInfoDAOExample = new AccsDeviceInfoDAOExample();
accsDeviceInfoDAOExample.createCriteria().andAppKeyEqualTo("12345").
andAppVersionEqualTo("1.2.3.4").andPackageNameEqualTo("com.hello.test");
param.put("oredCriteria", accsDeviceInfoDAOExample.getOredCriteria());
session.select("com.taobao.accs.mass.petadata.dal.sqlmap.
AccsDeviceInfoDAOMapper.selectByExampleForPetaData", param, new
ResultHandler() {
@Override
public void handleResult(ResultContext resultContext) {
AccsDeviceInfoDAO accsDeviceInfoDAO = (AccsDeviceInfoDAO) resultContext.getResultObject();
System.out.println(resultContext.getResultCount());
System.out.println(JSON.toJSONString(accsDeviceInfoDAO));
}
}
);
}
本次事故复盘结束,解决方案不尽完善,希望对遇到类似问题的同学有所帮助。