觉得可以的话,点个赞呀!
数据来源:https://www.kaggle.com/jihyeseo/online-retail-data-set-from-uci-ml-repo
1、电商面临的问题
(1)哪些产品最受欢迎(访问量、购买量)
(2)哪些用户是最有价值的用户(特定时间内消费总额最高,并分析用户特征)
(3)哪些是最忠诚用户(复购率高、考虑怎么增加忠诚用户的消费额)
(4)用户消费习惯分析(哪些产品喜欢一起购买;或者特定购买时间顺序)
(5)促销对哪些用户最有效(用户活跃度)
2、电商运营指标
(1)整体运营指标(了解电商运营情况)
月追踪:销售数量、销售总额、月均销售额
周追踪:销售数量、销售总额、周均销售额
效率指标:
客单价=销售总额/人数
件单价=销售总额/销售总数
连带率=销售总量/成交单数
退货指标:退货金额、退货数量、退货用户数
(2)RFM: Receny、Frequency、Monetary(挖掘价值用户进行经营策略管理)
(3)价值用户行为指标:(了解价值用户消费习惯)
销量最高产品
销售金额占比最高产品
价值用户喜欢一起购买的产品
3、本次分析目的
(1)了解运营情况(分析各项指标了解经营效率与发展趋势)
(2)RFM模型对用户进行分级,找出价值用户进行经营策略管理,
进一步挖掘高价值用户的消费模式,提出个性化的销售服务提高价值用户体验,从而提高运营效率和利润
模块导入
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
一、数据说明
1、导入数据
df = pd.read_excel('Online Retail.xlsx')
2、字段含义及数据量
InvoiceNo 541909 单号 object
StockCode 541909 产品号 object
Description 540455 产品描述 object
Quantity 541909 每一笔交易中产品数量 int64
InvoiceDate 541909 交易时间 datetime64[ns]
UnitPrice 541909 产品单价 float64
CustomerID 406829 客户ID float64
Country 541909 客户所在国家 object
二、数据清洗
1、删除重复值
如果 八列值相同则删除
#备份原数据
df_copy = df.copy()
df = df.drop_duplicates()
总共删除5268条数据
2、缺失值处理
删除用户id缺失的行
df = df.dropna(subset=['CustomerID'],how=any)
总共删除135037数据
3、一致化处理
时间值处理:增加年、月、周
df['Year'] = pd.DatetimeIndex(df['InvoiceDate']).year
df['Month'] = pd.DatetimeIndex(df['InvoiceDate']).month
df['Week'] = pd.DatetimeIndex(df['InvoiceDate']).dayofweek
4、异常值处理
Quantity
plt.scatter(range(len(df)),df['Quantity'])

购买数量应该是大于0的,将小于等于0的异常值去除。有两个数据的数量达到了70000观察可知。应该也是合理的,因为进一步观察发现单价低
df = df[df['Quantity']>0]
删除了8872个异常值
UnitPrice
plt.scatter(range(len(df)),df['UnitPrice'])
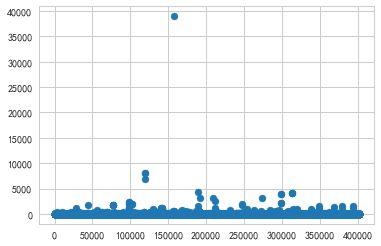
商品单价应该大于0
df = df[df['UnitPrice']>0]
删除40个异常值
原数据集的时期是2010-12-1到2011-12-09,2011年12月数据不满一个月,为了方便分析和讨论本次分析选择数据时间为:2010-12-01到2011-11-30,12个月。
df = df[df['InvoiceDate']<'2011-12-01']
三、描述统计分析
1、运营指标计算
a、月追踪指标
(1)每月销售单数(单号可能会重复)
df_InvoiceNo = df.drop_duplicates(subset=['InvoiceNo'])
month_InvoiceNo = df_InvoiceNo.groupby(['Year','Month'])['InvoiceNo'].count()
产品单数旺季集中在9月到11月,其中11月销量最高(考虑可能和双十一等活动有关),1-2月份为淡季

(2)月销售额
df['Amount'] = df['UnitPrice'] * df['Quantity']
month_amount = df.groupby(['Year','Month'])['Amount'].sum()
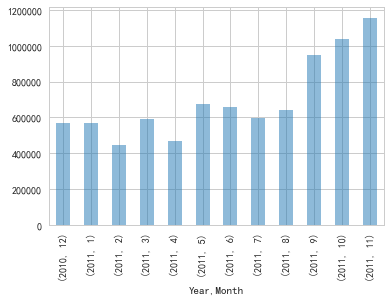
图4:销售总额来讲,9-11月份销售额最高。结合销售单数分析,11月份销售单数比9月和10月都高30%左右,而总销售额却只高了10%左右。由此可见11月份有可能进行降价促销,因此整体表现而言10月份较好。
其他几个月份销售额都在60000左右。1月份销售量最低,但是销售总额依旧表现良好。可以进一步分析1月份销售产品,比如说是否涨价,与2月份的销售产品进行比较(因为2月份与1月份销量差不多,但是销售额却差了100000左右)。从而分析产品涨价与降价对整体销售额的影响。
(3)月均销售额
month_amount_avg = month_amount.sum()/12
月均销售额为697501.5,可见9-11月份的销售总额远高于月均水平
b、周追踪指标
(1)每周销售单数
week_InvoiceNo = df_InvoiceNo.groupby('Week')['InvoiceNo'].count()
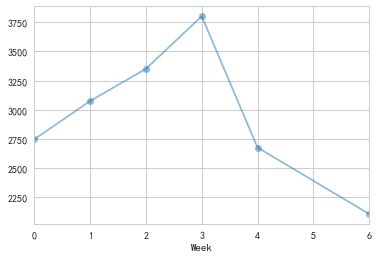
给的数据中没有周六的单数,从单数来看周二到周四销量较多,其中周四的订单量将近周日的两倍。可能在周四有某些日子购买了大量的单数。

但是进一步分析每月每周的统计结果来看,造成这个结果的应该不是由于某些日子购买大量单数所致。因为几乎每个月的周一到周四销售单数都很好。尤其是周四表现最好,需要进一步挖掘周四销量好的原因,另外也可以考虑一些促销活动安排在周四。
(2)周销售额
week_amount = df.groupby('Week')['Amount'].sum()
plt.hlines(y = week_amount_avg,xmin=0,xmax=6,color='r',linestyle='--',alpha=0.5,label='Average')
(week_amount.sum()/6).plot(kind='line',marker='o',alpha=0.6)
plt.xlabel('Week')
plt.legend()

周二到周四销售额都超过平均水平
(3)周均销售额
week_amount_avg = round(week_amount.sum()/52,2)
计算结果为160961.89,这是每周平均销售额,给运营者提供一个参考,可以初步评价每一星期的销售情况,是高于还是低于平均值。
c、效率指标
(1)客单价=销售总额/人数
customer_num = df.drop_duplicates(subset=['CustomerID'])
sales_perCustomer = round(df['Amount'].sum()/len(customer_num),2)
每位顾客在店内消费额为1947.42
(2)件单价=销售总额/销售总数
sales_perPro = round(df['Amount'].sum()/df['Quantity'].sum(),2)
件单价为:1.72,由此可见有部分顾客在店内消费很高。
(3)连带率=售出的产品总数/总的交易单数
sales_perInvoiceNo = round(df['Quantity'].sum()/len(df_InvoiceNo),2)
每笔成交单数中平均销售274.76件产品,可见在销售过程中有些单数中有大量采购的用户
d、退货金额
在原数据集说明中,订单号如果以字母c开头表示该订单为取消订单,所以在这里想看看退货的情况
cancel = df.iloc[:,0].str.startswith('c')
可知没有取消订单
2、RFM指标
a、R-Recently(用户最后一次购物距离现在几个月)
计算出最后一次购买时间距离最后一天的天数,然后再计算月分数。
Last_purchase = df.groupby('CustomerID')['InvoiceDate'].max()
Max_date=Last_purchase.max()
Recency_days=Last_purchase.map(lambda x:(x-Max_date).days)
#Recency in months
Recency_months=Recency_days.map(lambda x:round((-1*x)/30,1))
sns.distplot(Recency_months)

图8可见40%左右的顾客在一个月内都有消费,近2个月内消费的客户数占了约55%。
同样近45%的客户在2个月内没进行消费,这些客户的流失可能性很大,而且流失比例也很大。可以采取一些促销方式拉动这批顾客的消费。
b、F-Frequency(一年内用户购买数)一年里面,用户总购买次数
Frequency_Year = df_InvoiceNo.groupby('CustomerID')['InvoiceNo'].count()
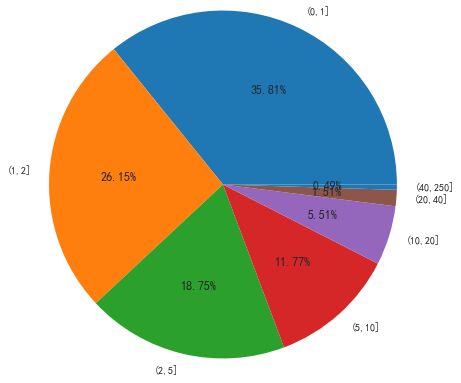
可以看到(0,5]的购买数占了近80%,只购买一次的用户占了35.81%。由此可见产品复购率表现良好。
c、M-Monetary(用户一年所花的总金额)
Monetary_Year = df.groupby('CustomerID')['Amount'].sum()
Monetary_Year.describe()
综合上面的计算,RFM的三个指标的数据区间范围分别是:
R [0.0, 12.2]
F [1.0, 201.0]
M [2.9, 268478.0]
四、建立模型
1、利用RFM挖掘价值用户
rfm = pd.DataFrame()
rfm['Recently'] = Recency_months
rfm['Frequency'] = Frequency_Year
rfm['Monetary'] = Monetary_Year
rfm.index = rfm.index.astype(int)
建立用户行为评分机制
r_labels = range(4,0,-1)
f_labels = range(1,5,1)
m_labels = range(1,5,1)
根据RFM用户三个标签对用户进行划分,并进行赋分
rfm['r_quartiles']= pd.qcut(rfm['Recently'], q=4, labels=r_labels)
rfm['f_quarities'] = pd.qcut(rfm['Frequency'].rank(method='first'), q=4, labels=f_labels)
rfm['m_quaritiles'] = pd.qcut(rfm['Monetary'], q=4, labels=m_labels)
有了RFM每个标签的评分后进行统计和算出每一位用户的最终得分,这里是把每个标签的评分相加。
rfm['score'] = rfm['r_quartiles'].astype(int)+rfm['f_quarities'].astype(int)+rfm['m_quaritiles'].astype(int)
用户根据RFM的综合评分RFM_Score分为了10个等级,实际运用中可能需要比较粗略的划分,这里把用户分为3个大的等级。'Gold''Silver''Bronze'10-12、6-9、3-5
labels = ['Bronze','Silver','Gold']
bins = [3,6,10,13]
rfm['Rank'] = pd.cut(rfm['score'],bins = bins,labels=labels,right=False)
可以找出三类客户的分界点,对后续客户等级进行划分
rfm.groupby('Rank').mean()
Recently Frequency Monetary
Bronze 6.515435 1.134037 273.283754
Silver 2.339588 2.392539 907.840998
Gold 0.690472 9.499213 5041.829701
通过RFM可以进行价值用户的划分,对不同群体用户进行不同管理,针对性提高运营效率
2、利用聚类算法挖掘价值用户
K-Means算法的应用有三个限制:(1)标签的分布是对称的,not skewed;(2)标签的平均值一样;(3)标签的方差一样。
针对对称问题,可以用对数变换(Logarithmic transformation)来解决,针对平均值和方差一样的问题,可以标准化转换(standardization)来解决,这两步的顺序是有严格要求的,因为log变换只适用于大于零的数值,而标准化会产生负值,所以必须要先进行log转换后进行standardization。
rfm_k = pd.DataFrame()
rfm_k['Frequency'] = rfm['Frequency'].apply(np.log).round(3)
rfm_k['Monetary'] = rfm['Monetary'].apply(np.log).round(3)
rfm_k['Recently'] = rfm['Recently']+0.001
rfm_k['Recently'] = -rfm_k['Recently'].apply(np.log).round(3)
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
from sklearn.pipeline import Pipeline
model = Pipeline([('sta',StandardScaler()),('kmean',KMeans(n_clusters=3,random_state=1))])
rfm_k['label'] = model.named_steps['kmean'].labels_
三个聚类0,1,2分别对应了Silver\Bronze\Gold
rfm['Ra gnk_k'] = pd.cut(rfm_k['label'],bins=3,labels=['Silver','Bronze','Gold'])
分界点
Recently Frequency Monetary
Silver 1.885546 3.764012 1469.826061
Bronze 4.969639 1.254124 332.801660
Gold 0.396073 13.510574 7904.876224
前10行结果:
Rank Rank_k
12346 Silver Silver
12347 Gold Silver
12348 Silver Silver
12349 Silver Silver
12350 Bronze Bronze
12352 Gold Silver
12353 Bronze Bronze
12354 Bronze Bronze
12355 Bronze Bronze
12356 Gold Silver