一瞥(You Only Look Once, YOLO),是检测Pascal VOC 2012数据集内对象/目标的系统,能够检测出20种Pascal对象:
人person
鸟bird、猫cat、牛cow、狗dog、马horse、羊sheep
飞机aeroplane、自行车bicycle、船boat、巴士bus、汽车car、摩托车motorbike、火车train
瓶子bottle、椅子chair、餐桌dining table、盆景potted plant、沙发sofa、显示器tv/monitor
补充 :有的同学报告说数据集无法下载,如果遇到这样的问题,可以用下面的方式在terminal中下载,也可以提取链接在浏览器或迅雷等软件中下载。
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
YOLO由以下参与者共同完成:Santosh、Ross和Ali,详细内容参见其paper
以下教程分为9部分(不要害怕,easy),运行系统Ubuntu 14.04。OpenCV、cuda、GPU这些依赖是可选项,如果没有也可以,就是慢点(其实是慢很多)啦。最后会添加一下官网教程中没有的安装错误和修改信息。
本篇教程内容全部翻译自官网
1.How It Works
先前的检测系统多使用分类器(classifier)或者定位器(localizer)进行检测任务,把图片的不同局部位置和多种尺度输入到模型中去,图片得分较高的区域(region)作为检测目标。
YOLO是一个全新的方法,把一整张图片一下子应用到一个神经网络中去。网络把图片分成不同的区域,然后给出每个区域的边框预测和概率,并依据概率大小对所有边框分配权重。最后,设置阈值,只输出得分(概率值)超过阈值的检测结果。
我们的模型相比于基于分类器的模型有一些优势,在测试阶段,整张图片一次输入到模型中,所以预测结果结合了图片的全局信息。同时,模型只是用一次网络计算来做预测,而在R-CNN中一张图片就需要进行上千次的网络计算!所以YOLO非常快,比R-CNN快1000倍,比Fast R-CNN快100倍。整个系统的细节见paper
2.Detection Using A Pre-Trained Model
本节内容会知道你如何使用YOLO预训练好的模型进行目标检测。在这之前,你应该安装好DarkNet,安装方法戳这里。
安装好DarkNet之后,在darknet的子目录cfg/下已经有了一些网络模型的配置文件,在使用之前,需要下载好预训练好的权重文件yolo.weights(1.0 GB).
现在,使用DarkNet的yolo命令进行一下测试吧(假设你在darknet/目录下,自己修改好yolo.weights和image的路径)
./darknet yolo test cfg/yolo.cfg
/yolo.weights
如果你没有现成的图片,不妨直接使用darknet/data/下面的某张图片。
进行上面的测试,Darknet会打印出检测到的目标对象和可信度,以及耗时。使用CPU时,每张图片耗时为6-12秒,GPU版本会快,快很多。
如果安装DarkNet的时候,没有使用OpenCV,上面的测试不会直接显示出图片结果,你需要自己手动打开predictions.png. 打开你会看到类似于下图的预测结果
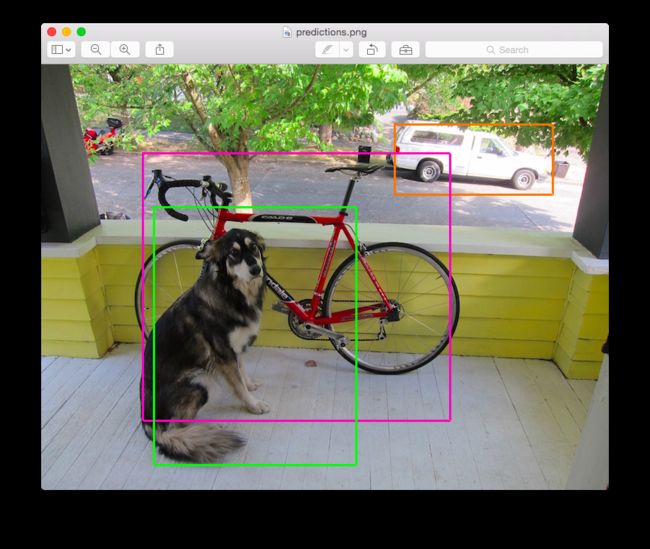
如果想运行一次DarkNet检测多张图片的话,你应该先运行以下命令载入预训练模型
./darknet yolo test cfg/yolo.cfg yolo.weights
模型载入成功后,会提示输入图片路径Enter Image Path:
键入类似于data/eagle.jpg的路径,检测这张图片,给出结果之后,会继续提示Enter Image Path。注意如果你连续输入了多张图片,之前的结果会被下一次的检测结果覆盖掉,因为预测结果都叫predictions.jpg。。。要退出/中断程序的话,直接键入Ctrl-C(自己记住这个命令,后面会再用)即可。
3.A Smaller Model
上面的YOLO模型会占用很多GPU内存,方法类似,只需要调用不同的配置文件,载入相应的权重文件即可。在这里,提供一个更小版本的模型,使用yolo-small.cfg配置文件,调用yolo-small.weights(359MB),命令如下
./darknet yolo test cfg/yolo-small.cfg yolo-small.weights
这个小版本的YOLO大概占用1.1GB的GPU内存~
4.A Tiny Model, yolo-tiny.weights(172 MB)
./darknet yolo test cfg/yolo-tiny.cfg yolo-tiny.weights
占用611MB的GPU内存,在Titan X上的速度是150 fps
5.YOLO Model Comparison
yolo.cfg,基于extraction网络,处理一张图片的速度为45fps,训练数据来源2007 train/val + 2012 train/val + 2007、2012所有数据
yolo-small.cfg,全连接层变小,占用内存变小,50fps,训练数据来源2007 train/val + 2012 train/val
yolo-tiny.cfg,更加小型的网络,基于DarkNet reference network,155fps,数据来源2007 train/val + 2012 train/val
6.Changing The Detection Threshold
YOLO默认返回可信度至少为0.2的检测结果,可以通过-thres
./darknet yolo test cfg/yolo.cfg yolo.weights data/dog.jpg -thresh 0
这将可能返回所有的检测结果。
7.Real-Time Detection On VOC 2012
如果编译时使用了CUDA,那么预测的速度回远远超过你(手动)输入图片的速度。为了更快速地检测多张图片的内容,应该使用yolo的valid子程序。
首先预备好数据并生成元数据给DarkNet。这里我们使用VOC2012的数据(需要注册一个账号才能下载),下载2012test.rar文件之后,运行以下命令
tar xf 2012test.tar
cp VOCdevkit/VOC2012/ImageSets/Main/test.txt .
sed 's?^?'`pwd`'/VOCdevkit/VOC2012/JPEGImages/?; s?$?.jpg?' test.txt > voc.2012.test
这些命令首先解压数据包,然后生成全路径的测试图像,然后把voc.2012.test移动到darknet/data子目录下
mv voc.2012.test
/darknet/data
OKAY,现在使用这些图片做检测,我们使用CUDA版本的,超级快!运行下面命令
./darknet yolo valid cfg/yolo.cfg yolo.weights
运行上面命令后,你会看到一串数字在屏幕上飞,数字表示当前处理了多少图片。VOC 2012 test数据集共有10991张图片,共耗时250秒,相当于44fps。如果你用Selective Search方法的话,要耗时6小时!相比之下,咱的方法整个pipeline才耗时4分钟,pretty cool!
预测结果在results/子目录下,其格式为Pascal VOC要求提交的特殊格式。
如果你想复现我们在Pascal挑战赛中的结果,你得使用yolo-rescore.weights才行。
8.Real-Time Detection on a Webcam
只是简单地跑一下测试数据集,而且看不到实时的结果,真的挺无趣的。所以,我们把输入改成webcam
挖个坑,后面填
9.Training YOLO
其实,你可以从头开始训练YOLO,如果你想的话。你可以尝试不同的训练方法,设置不同的超参数,以及使用自己的数据集。咱们下面尝试自己训练Pascal VOC数据集。
9.1下载Pascal VOC Data
咱们先下载2007年到2012年的VOC数据,下载之前,新建一个文件夹(比如VOC)存放这些数据,进入此文件夹,按如下方式下载数据,然后解压。
curl -O http://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
curl -O http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
curl -O http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
解压完之后,所有数据都自动存放在VOCdevkit/子目录下了。
9.2生成VOC的标注信息
接下来生成DarkNet训练所需的标签文件,该文件扩展名为.txt,文件内每一行对应一张图片的标注信息,具体格式如下
# x y 是bbox的中心坐标,width height是bbox的宽度和高度,归一化值形式
其中的x, y, width和height是对应图片上的坐标和宽、高。只要运行一下DarkNet项目中scripts/子目录下面的voc_label.py脚本,就会自动生成VOC的标注文件。如果你没找到这个文件,可以再重新下载一下。下载和脚本运行方式如下
curl -O http://pjreddie.com/media/files/voc_label.py
python voc_label.py
这个脚本大概要运行几分钟,运行结束之后,你会看到多了两个文件夹,VOCdevkit/VOC2007/labels/和VOCdevkit/VOC2012/labels/。
现在,你的VOC目录下应该是这个样子的
ls2007_test.txt VOCdevkit2007_train.txt voc_label.py2007_val.txt VOCtest_06-Nov-2007.tar2012_train.txt VOCtrainval_06-Nov-2007.tar2012_val.txt VOCtrainval_11-May-2012.tar其中的文本文件,比如2007_test.txt,包含的内容是VOC 2007年的test数据集标注信息。DarkNet需要一个txt文件提供所有标注信息,所以我们还需要把这些信息导入到一个txt文件中。本例中,我们使用2007年的train和validation数据和2012年的train数据作为训练集,2012年的validation数据作验证数据。具体使用如下命令
cat 2007_* 2012_train.txt > train.txt
OKAY,现在2007年的所有图片和2012年的train数据集的图片路径都在train.txt文件里面了。标注信息在下面两个路径中
/darknet/VOC/VOCdevkit/VOC2007/labels/
/darknet/VOC/VOCdevkit/VOC2012/labels/
上面所做的就是训练自己的数据集之前所要准备的数据信息了。
9.3重定向DarkNet到Pascal数据
进入DarkNet目录中,src/子目录里面有一个yolo.c文件,打开并编辑一下其中的18、19行(54、55行?不重要,自己确定)
18 char *train_images = "/your_path/VOC_train/train.txt";19 char *backup_directory = "/your_path/backup/";其中,train_images指向的是训练文件,backup_directory指向的是训练过程中权重的备份路径。编辑好yolo.c之后,保存,重新编译一下DarkNet。
9.4下载预训练之后的卷积权重
训练的时候使用来自Extraction模型的卷积层权重,这个模型训练时用的是Imagenet数据。从这(54MB)下载这些权重。如果你想直接用Extraction模型生成这些预训练好的权重,你得先下载预训练好的Extraction模型,运行下面的命令
./darknet partial cfg/extraction.cfg extraction.weights extraction.conv.weights 25
劝告大家直接下载权重会更简单。。。
9.5训练
运行下面命令开始训练
./darknet yolo train cfg/yolo.cfg extraction.conv.weights
运行时,屏幕会提示一下数字和任务信息。
如果你想训练更快些,同时降低提示信息频率,首先终止训练,然后在cfg/yolo.cfg中修改一下第三行的信息
3 subdivisions = 2
或修改成4,或更大,比如64。然后重新开始训练
9.6训练Checkpoints
每训练128000张图片之后,DarkNet自动保存checkpoint信息到你在src/yolo.c中指定的备份路径下。checkpoint的文件名类似于yolo_12000.weights。你可以使用这些checkpoint信息重新开始训练,避免从头开始。
40,000次迭代之后,DarkNet会保存模型的权重,然后结束训练,最后的权重会以yolo.weights命名。
恭喜,这就训练结束了~
Good Luck!!
上两张训练时的截图
下面是你安装过程中可能遇到的问题和解决办法
Q1.使用GPU=1,运行测试命令,例如
./darknet imtest data/eagle.jpg
或者
./darknet yolo demo cfg/yolo.cfg yolo.weights并键入图片地址
报以下错误
L2 Norm: 372.007568
CUDA Error:invalid device function
darknet: ./src/cuda.c:21: check_error: Assertion `0' failed.
Aborted (core dumped)
看了看./src/cuda.c的代码也没发现啥。。。
出现这个问题是因为DarkNet的配置信息Makefile文件里面的GPU架构和实际安装的GPU不对应。
ARCH= --gpu-architecture=compute_xx --gpu-code=compute_xx
经测试,k40m和k40显卡应该设置为
ARCH= --gpu-architecture=compute_35 --gpu-code=compute_35
tk1显卡的设置应该为
ARCH=--gpu-architecture=compute_20 --gpu-code=compute_20
或许这些信息对你有所帮助
