再次了解kubernetes的基本概念和术语
1、kubernetes整体概要
在Kubernetes中,Service(服务)是分布式集群架构的一个核心,一个Service对象拥有如下特征。
- 拥有一个唯一指定的名字(如mysql-server)。
- 拥有一个虚拟IP(Cluster IP、Service IP或VIP)。
- 能够提供某个远程服务的能力。
- 被印射到了提供这种服务能力的一组容器应用之上。
Service的服务进程目前都是居于Socker通信方式对外提供服务,如Redis、Memcache、Mysql、Web Service,或是实现了某个具体业务的一个特定的TCP Server进程。虽然一个Service通常由多个相关的服务进程来提供服务,每个服务进程都有一个Endpoint(ip+port)访问点,但kubernetes能够让我们通过Service(虚拟Cluster IP + Service Port)连接到指定的Service上面。
kubernetes内建的透明负载均衡、故障恢复机制及service创建后ip不变化,基于此可以向用户提供稳定的服务。
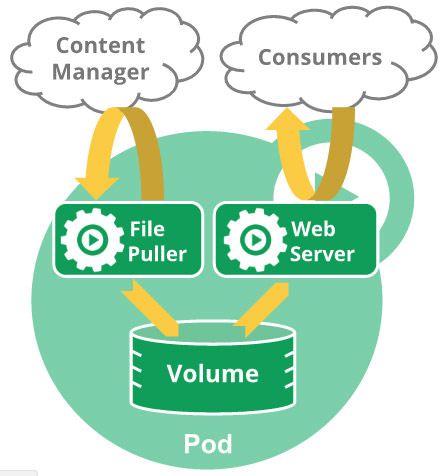
容器提供了强大的隔离功能,所以有必要把Service提供服务的这组进程放到容器中进行隔离。为此,kubernetes设计了Pod对象,将每个服务进程包装到相应的Pod中,使其成为Pod中运行的一个容器(Container)。为了建立Service和Pod间的关联联系,kubernetes首先给每个Pod贴上一个标签(Label),如给运行mysql的Pod贴上name=mysql的标签,然后给相应的Service定义标签选择器(Label Selector),如mysql的Service的标签选择器的选择条件为name=mysql,意为Service下所有包含name-=mysql的Label的Pod上。
说到Pod,简单介绍其概念。首先,Pod运行在一个我们称之为节点(Node)的环境中,这个节点可能是物理机或虚拟机,通常一个节点上上面运行几百个Pod;其次每个Pod运行着一个特殊的被称之为Pause的容器,其它的容器被称为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此它们之间的通信和数据交换效率更为高效。在设计时我们可以充分利用这一特性将一组密切相关的服务进程放到同一个Pod中。最后需要注意的是并不是每一个Pod和它里面运行的容器都能映射到一个Service上,只有那些提供服务的一组Pod才会被映射成一个服务。
在集群管理方面,kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)。其中Master节点运行着集群管理的一组进程kube-apiserver、kube-controller-manage、kube-scheduler。这些进程实现了整个集群的资源管理、Pod调度、弹性收缩、安全控制、系统控制和纠错等管理功能,并且全是自动完成的。Node作为一个集群中的工作节点,运行真正的应用程序,在Node上kubernetes管理的最小单元是Pod。Node运行着kubernetes的kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启和销毁,以及实现软件模式的均衡负载。
解决传统的服务扩容和服务升级两个难题里,kubernetes集群中,我们只需要为扩容的service关联的Pod创建一个Replication Controller(简称RC),在这个RC定义文件中写好下面几个关键信息:
- 目标Pod的定义。
- 目标Pod需要运行的副本数量(Replicas)。
- 要监控目标Pod的标签(Label)。
在创建好RC(系统将自动创建好Pod)后,kubernetes会通过RC中定义的Label筛选出对应的Pod实例并全自动实时监控其状态和数量。
2、基本概念和术语
kubernetes中大部分概念如Node、Pod、Replication Controller、Service等都可以被看作一种资源对象,几乎所有的资源对象都可以通过kubernetes提供的kubectl工具(或API编程调用)执行增删改查等操作,并将其保存在etcd中持久化存储。从这个角度来看,kubernetes其实是一个高度自动化的资源控制系统,它通过跟踪对比保存在etcd库里的“资源期望状态”和当前环境中的“实际资源状态”的差异来实现自动控制和自动纠错的高级功能。
2.1 Master
kubernetes里的Master指的是集群控制节点。每个kubernetes集群里都需要一个Master节点来负责整个集群的管理和控制,基本上kubernetes所有的控制命令都是发给它,它来负责具体的执行过程,我们后面所有的执行的命令基本上都是在Master节点上运行的。Master节点通常会占据一个独立的服务器或虚拟机,就是它的重要性体现,一个集群的大脑,如果它宕机,那么整个集群将无法响应控制命令。
Master节点上运行着以下几组关键进程:
- Kubernetes API Server(kube-apiserver):提供了HTTP rest接口的关进服务进程,是Kubernetes里所有资源增删改查等操作的唯一入口,也是集群管理的入口进程。
- Kubernetes Controller Manage(kube-controller-manage):Kubernetes里所有资源对象的自动化控制中心,可以理解为资源对象的“大总管”。
- Kubernetes Scheduler(kube-scheduler):负责资源的调度(Pod调度)的进程。
Master还启动了一个etcd server进程,因为kubernetes里所有的资源对象的数据都是保存在etcd中的。
2.2 Node
除了Master,kubernetes集群的其它机器也被称为Node节点,在较早的版本也被称为Monion。同样的它也是一台物理机或是虚拟机。Node节点才是Kubernetes集群中工作负载节点,每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机之后,其上的工作负载会被Master自动转移到其它节点上面去。
每个Node节点运行着以下几个关键进程:
- kubelet:负责pod对应的同期创建、启动停止等任务,同时与Master节点密切协作,实现集群管理的基本功能。
- kube-proxy:实现Kubernetes Service的通信与负载均衡的重要组件。
- Docker-Engine(docker):docker引擎,负责本机容器的创建和管理工作。
Node节点可以在运行期间动态增加到Kubernetes集群中,前提是这个节点已经正确安装、配置和启动的上述关键进程。在默认情况下kubenet会向Master注册自己,这也是kubernetes推荐的管理方式。一旦Node被纳入集群管理范围,kubelet进程就会定时向Master节点汇报自身的情况,包括操作系统、Docker版本、机器cpu和内存情况及有哪些pod在运行。这样Master可以获知Node的资源使用情况并实现高效均衡的资源调度策略。而某个Node超过时间不进行上报信息时,master将会将其标记为失联(Not Ready),随后会触发资源转移的自动流程。
2.3 Pod
Pod是Kubernets最重要也是最基础的概念,其由下图示意组成:
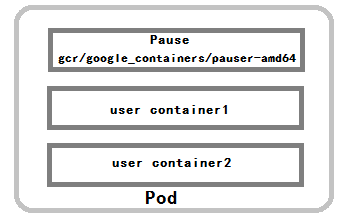
需求推动发展,下面解释为何会有pod的设计和其如此特殊的结构。
- 一组容器作为单元的情况下,难以去对“整体”进行简单判断并采取有效的行动。如一个容器挂了,是算整体服务挂了,还是算N/M的死亡率。引入业务无关并且不易挂掉的
Pause容器作为Pod的根容器,以它的状态作为整体容器组的状态,就简单巧妙的解决了这个问题。 - Pod多个业务容器共享Pause容器的IP,共享Pause容器挂接的Volume卷。这样既简化了密切关联业务容器之间的通信问题,还很好地解决了它们之间文件共享的问题。
k8s为每个Pod都都分配了唯一的ip,称之为Pod IP,一个Pod里的多个容器共享Pod IP地址。k8s要求底层网络支持集群内任意两个Pod之间的TCP/IP直接通信,这通常采用虚拟二层网络技术来实现,如Flannel、Openswith等,牢记在k8s中,一个Pod容器与另外主机上的Pod容器能够直接通信。
Pod其实有两种类型:普通的Pod及静态的Pod(static Pod),后者比较特殊,并不存放在k8s的etcd里面存储,而是存放在某一个具体的Node上的一个文件中,并且只在此Node上启动运行。而普通的Pod一旦被创建,就会被放入到etcd中存储,随后会被k8s Master调度到某个具体的Node上面进行绑定(Binding),随后该Pod被对应的Node上的kubblet进程实例化成一组的Docker容器并启动起来。默认情况下,当Pod里的某个容器停止时,k8s会自动检测这个问题并重启启动这个Pod(Pod里面的所有容器),如果Pod所在的Node宕机,则会将这个Node上的所有Pod重新调度到其它节点上。Pod、容器与Node的关系如下:

k8s里的所有的资源对象都可以采用yaml或JSON格式的文件定义或描述,下面是某个Pod文件的资源定义文件。
apiSerdion: v1
kind: Pod
matadata:
name: myweb
labels:
name: myweb
spec:
containers:
- name: myweb
image: kubeguide/tomcat-app:v1
ports:
- containerPort: 8080
env:
- name: MYSQL_SERVICE_HOST
value: 'mysql'
- name: MYSQL_SERVICE_PORT
value: '3306'
kind为Pod表明这是一个Pod的定义;matadata的name属性为Pod的名字,还能定义资源对象的标签Label,这里声明myweb拥有一个name=myweb的标签。Pod里面所包含的容器组的定义则在spec中声明,这里定义一个名字为myweb,镜像为kubeguide/tomcat-app:v1的容器,该容器注入了名为MYSQL_SERVICE_HOST='mysql'和MYSQL_SERVICE_PORT='3306'的环境变量(env关键字)。Pod的IP加上这里的容器端口(containerPort)就组成了一个新的概念Endpoint(端口),它代表Pod的一个服务进程对外的通信地址。一个Pod也存在着具有多个Endpoint的情况,比如tomcat定义pod时候,可以暴露管理端口和服务端口两个Endpoint。
我们所熟悉的Docker Volume在k8s中也有相应的概念 - Pod Volume,后者有一些幻化,比如可以用分布式系统GlusterFS实现后端存储功能;Pod Volume是定义在Pod之上,然后被各个容器挂载到自己的文件系统中的。
最后是k8s中Event的概念,Event是一个事件的记录,记录了时间的最早产生时间、最后重现时间、重复次数、发起者、类型及导致此次事件的原因等总舵信息。Event通常会关联到某个具体的资源对象上,是排查故障的重要信息参考信息。Node描述信息包含Event,而Pod同样有Event记录。当我们发现某个Pod迟迟无法创建时,可以用kubectl describe pod name来查看它的信息,用来定位问题的原因。
每个Pod都可以对其能使用的服务器上的计算资源设置限额,当前可以设置的限额的计算资源有CPU和Memory两种,其中CPU的资源单位为CPU(core)核数,一个绝对值。
一个cpu的配额对绝大多数容器去是一个相当大的资源配额,所以在k8s中,通常以千分之一的cpu配额为最小单位,用m来表示,即一个容器的限额为100-300m,即占用0.1-0.3个cpu限额。由于它是绝对值,所以无论在1个cpu的机器还是多个cpu的机器,这个100m的配额都是一样的。类似的Memory配额也是一个绝对值,单位是内存字节数。
在k8s中,一个计算资源进行配额限定需要设定下面两个参数:
- Request;该资源的最小申请量,系统必须满足要求。
- Limits:该资源允许最大的使用量,不能被突破,当容器视图使用超出这个量的资源时,可能会被k8s杀死并重启。
通常会把Request设置为一个比较小的数值,符合同期平时的工作负载情况下的资源要求,而把Limit设置为峰值负载情况下资源占用的最大量。如下面的设定:
spec:
containers:
- name: db
image: mysql
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
即表明mysql容器在申请最少0.25个cpu及64Mib的内存,在运行过程中mysql容器所能使用的资源配额为0.5个cpu及128Mib的内存。

2.4 Label(标签)
Label是k8s系统中另一个核心的概念。一个Label是一个key=value的键值对,其中key和value由用户自己指定。Label对象可以附加到各种资源对象上面,如Node、Pod、Service、RC等,一个资源对象可以定义任意数量的Label,同一个Label也可以被添加到任意资源对象上去,Label通常在资源对象定义时确定,也可以通过对象创建之后动态添加或删除。
我们可以通过给指定的资源对象捆绑一个或多个不同的Label来实现多维度的资源分组管理功能,以便于灵活、方便地进行资源分配、调度、配置和布署等管理工作。一些常用的label如下:
- 版本控制:"release": "stable", "release": "canary"
- 环境标签:"environment": "dev", "environment": "qa", "environment": "production"
- 架构标签:"tier": "frontend", "release": "backend", "release": "middkeware"
- 分区标签:"partition": "customerA"
- 质量管控标签:"track": "daily", "track": "weekly"
给某个资源对象定义一个Label,随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,k8s通过这种方式实现了类是SQL的简单通用的对象查询方式。
当前有两种Label Selector的表达式:基于等式的(Equality-based)和基于集合(Set-based)。
基于等式的表达式匹配标签实例:
- name=redis-slave:匹配所有具有标签name=redis-slave的资源对象。
- env!=production: 匹配不具有标签name=production的资源对象。
基于集合方式的表达式匹配标签实例:
- name in (redis-slave, redis-master):匹配所有具有标签name=redis-slave或name=redis-master的资源对象。
- name not in (php-frontend):匹配不具有标签name=php-frontend的资源对象。
可以通过多个Label Selector表达式的组合实现复杂的条件选择,多个表达式之间用“,”分隔即可,几个条件是and的关系,即同时满足多个条件,如:
- name=redis-slave, env!=production
- name not in (php-frontend), env!=production
Label Selector在k8s中重要使用场景有下面几处:
- kube-controller-manage进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本的数量。
- kube-proxy进程通过Service的Label Selector来选择对于那个的Pod,自动建立起Service对应每个Pod的请求转发路由表,从而实现Service的智能负载均衡机制。
- 通过对某些Node定义特定的Label,并且Pod定义文件中使用NodeSelector这种标签调度策略,kube-schedule进程可以实现Pod“定向调度”的特性。
总结:使用Label可以给资源对象创建多组标签,Label和Label Selector共同构成了k8s系统中最核心的应用模型,使得被管理对象能够被精细地分组管理,同时实现了整个集群的高可用性。
2.5 Replication Controller(RC)
前面部分对Replication Controller(简称RC)的定义和作用做了一些说明,本节对RC的概念再进行深入研究下。
RC是k8s系统中的核心概念之一,简单来说,它是定义了一个期望的场景。即声明某种Pod的副本数量在任意时刻都符合某个预期值,所以RC的定义包含如下几个部分:
- Pod期待的副本数(replicas)。
- 用于筛选目标Pod的Label Selector。
- 当Pod的副本数量小于预期数量的时候,用于创建新Pod的Pod模版(templates)。
下面是一个完整的RC定义的例子,即确保拥有tier=frontend标签的这个Pod(运行Tomcat容器)在整个集群中始终只有一个副本。
apiVersion: v1
kind: ReplicationController
metadata:
name: frontend
spec:
replicas: 1
selector:
tier: frontend
templete:
metadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat
imagePullPolicy: IfNotPresent
env:
- name: GET_HOSTS_FROM
value: dns
ports:
- containerPort: 80
当我们定义了一个RC并提交到k8s集群中以后,Master节点上的Controller Manager组件就得到了通知,定期巡检系统中当前存活目标的Pod,并确保目标Pod实例的数量刚好等于此RC的期望值。如果有过多的Pod副本在进行,系统就会停掉一些Pod,否则系统会自动创建一些Pod。可以说,通过RC,k8s实现了用户应用集群的高可用性,并且大大减少了系统管理员在传统环境中完成许多的运维工作(主机监控、应用监控、故障恢复)。
需要注意的有几点:删除RC并不会影响已经通过该RC创建好的Pod。为了删除所有的Pod,可以设置replicas为0,然后更新RC。另外,kubectl提供了stop和delete命令来一次性删除RC和RC控制的全部Pod。
当我们应用升级时,通常会通过Build一个新的Docker镜像,并用新的镜像版本来代替旧的版本方式达到目的。在系统升级的过程中,我们希望是平滑的方式,如系统中10个对应旧版本的Pod,最佳的方式就是就旧版本的Pod每次停止一个,同时创建一个新版本的Pod,在整个升级的过程中,此消彼长,而运行中的Pod始终是10个,几分钟后,当所有的Pod都是新版本之后,升级过程完成。通过RC的机制,k8s很容易就实现这种高级实用的特性,被称为“滚动升级”(Rolling Update)。
由于Replication Controller与k8s代码中的模块Replication Controller同名,同时这个词又无法准确表达它的本意,所以在k8s1.2的时候,它就升级成了另外一个新的概念 - Replica Set,官网解释为“下一代的RC”。与当前RC区别在于:Replica Sets支持基于集合的Label Selector(Set-based selector),而当前RC只支持基于等式的Label Selector(equality-based selector)。
当前我们很少使用Replica Set,它主要被Deployment这个更高层的资源对象使用,从而形成一整套Pod的创建、删除、更新的编排机制。当我们使用Deployment时,无需关系它是如何创建和维护Replica Set,都是自动完成的。
Replica Set与Deployment这两个重要的资源对象逐步替换了之前RC的作用,是k8s1.3 Pod自动扩容(伸缩)这个告警功能实现的基础。
最后总结RC(Replica Set)的的一些特性与作用:
- 多数情况下,我们通过定义一个RC实现Pod的创建过程及副本数量的自动控制,可以实现Pod的弹性收缩。
- RC里包括完整的Pod定义模版。
- RC通过Label Selector机制实现对Pod的自动控制。
- 通过改变RC里Pod模版的镜像版本,可以实现Pod的滚动升级功能。
2.6 Deployment
Deployment是k8s 1.2之后引入的新概念,引入的目的就是为了更好的解决Pod的编排问题。为此,Deployment在内部使用了Replica Set来实现目的,可以看作是RC的一次升级。
Deployment典型使用场景有以下几个:
- 创建一个Deployment对象来生成对应的Replica Set并完成Pod副本的创建过程。
- 检查Deployment的状态来看布署动作是否完成(Pod副本的数量是否达到预期值)。
- 更新Deployment以创建新的Pod(如镜像升级)。
- 如果当前Deployment不稳定,则回滚到早先的Deployment版本。
- 挂起或恢复一个Deployment。
下面是一个实例,文件名为tomcat-deployment.yaml:
apiVersion: extension/v1beta1
kind: Deployment
matadata:
name: frontend
spec:
replica: 1
selector:
matchLabels:
tier: frontend
matchExpressions:
- {key: tier, operator: In, values: [frontend]}
template:
matadata:
labels:
app: app-demo
tier: frontend
spec:
containers:
- name: tomcat-demo
image: tomcat
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
命令kubectl create -f tomcat-deployment.yaml,命令以后再尝试。
2.7 Horizontal Pod Autoscaler(HPA)
之前提到过,通过手工执行kubectl scale的命令,我们可以实现Pod扩容或缩容,但谷歌对k8s的定位是自动化、智能化,即分布式系统要能根据当前负载情况变化自动触发水平扩展或缩容的行为,因为这过程是频繁发生、不可预料的。
k8s 1.1版本中首次发布这一特性:Horizontal Pod Autoscaling,随后在1
2版本中HPA被升级为稳定版本(apiVersion: autoscaling/v1),但同时仍保留旧版本(apiVersion: extension/v1beta1),官方计划是1.3移除旧版本,1.4彻底移除旧版本的支持。
Horizontal Pod Autoscaling(HPA),意味Pod的横向自动扩容,与之前RC、Deployment一样,也是k8s资源对象的一种。通过分析RC控制的所有目标Pod的负载变化情况,来确定是否需要针对性地调整目标Pod的副本数,即HPA的实现原理。当前有下两种方式作为Pod负载的度量指标。
- CPU Utilization Percentage。
- 应用程序自定义度量指标,如服务每秒内相应的请求数(TPS或QPS)。
CPU Utilization Percentage是一个算术平均值,即目标Pod所有副本的CPU利用率的平均值。一个Pod自身的CPU利用率是该Pod当前CPU的使用量除以它的Pod Resquest的值。如我们定义一个Pod的Pod Resquest为0.4,而当前Pod的CPU使用量是0.2,即它的CPU使用率是50%,如此我们就可以算出一个RC所控制的所有Pod副本的CPU利用率的算术平均值了。某一时刻,CPU Utilization Percentage的值超过80%,则意味着当前Pod副本数量可能不支持接下来所有的请求,需要进行动态扩容,而请求高峰时段过去后,Pod利用率又会降下来,对应Pod副本也会减少数量。
CPU Utilization Percentage 计算过程中使用到的Pod的COU的量通常是1分钟的平均值,目前通过查询Heapster扩展组件来得到这个值,所以需要安装布署Heapster,这样便增加了系统的复杂度和实施HPA特性的复杂度。未来的计划是实现一个自身性能数据采集的模块。
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
matadata:
name: php-apache
namespace: default
spec:
maxReplica: 10
minReplica: 1
scaleTargetRef:
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 90
2.8 Service(服务)
2.8.1 概述
Service同样也是k8s核心资源对象之一,它即是我们常提起微服务构架的一个“微服务”,之前我们说的Pod、RC等资源对象其实都是为这节所说的Service(服务)做准备的。

k8s的Service定义了一个服务的访问入口地址,前端的应用(Pod)通过这个入口地址访问其背后由Pod副本组成的集群实例,Service和其后端Pod副本集群之间则是通过Label Selector来实现无缝对接的;RC的作用实际是保证Service的服务能力与服务质量始终处于预期的标准。
通过分析、识别并建模系统中的所有服务为微服务 - kubernetes Service,最终系统由多个提供不同业务能力而又彼此独立的微服务单元所组成,服务之间通过TCP/IP进行通信,从而形成强大而又灵活的弹性网络,拥有了强大的分布式能力、弹性扩展能力、容错能力,同时程序架构也变得灵活很多。
既然每个Pod都会被分配一个单独的IP地址,而且每个Pod都提供了一个独立Endpoint(Pod IP+ContainerPort)以被客户端访问,现在多个Pod副本组成了一个集群来提供服务,一般的做法都是布署一个负载局衡器(软件或硬件),为这组Pod开启一个对外的服务端口8000,并将这些Pod的Endpoint列表加入8000端口的转发列表中,客户端就可以通过负载均衡器的对外IP地址+服务器端口来访问此服务,而客户端的请求最后会被转发到那个Pod,则由负载均衡器的算法决定。
k8s也遵循了上述做法,运行在每个Node上的kube-proxy进程其实就是只能的软件负载均衡器,它负责把对Service的请求转发到后端的某个Pod上面,并在内部实现服务的负载均衡和会话保持机制。但k8s发明了一种巧妙影响深远的设计:Service不是共用一个负载均衡器的IP地址,而是每个Service分配了一个全局唯一的虚拟IP地址,这个IP地址又被称为Cluster IP。这样的话,虽然Pod的Endpoint会随着Pod的创建和销毁而发生改变,但是Cluster IP会伴随Service的整个生命周期,只要通过Service的Name和Cluster IP进行DNS域名映射,Pod的服务发现通过访问Service即可解决。
2.8.2 k8s的服务发现机制
任何分布式系统都会有服务发现的基础问题,大部分的分布式系统通过提供特定的API接口,但这增加了系统的可侵入性。
最早k8s采用Linux环境变量去解决这个问题,即每个Service生成一些对应的Linux变量(ENV),并在每个Pod容器在启动时,自动注入这些环境变量。后来k8s通过Add-On增值包的方式引入了DNS系统,把服务名作为DNS域名,这样程序就可以直接使用服务名来建立通信连接。
2.8.3 外部系统访问Service的问题
为了更加深入的理解和掌握k8s,我们要弄明白k8s的三个IP的关键问题:
- Node IP:Node节点的IP地址。
- Pod IP:Pod的IP地址。
- Cluster IP:Service的IP地址。
Node IP是k8s集群中每个节点物理网卡的IP地址,这是一个真是存在的物理网络,所有属于这个网络的服务器之间都能通过这个网络直接通信,不管它们中是否有部分节点不属于这个k8s集群。这也表明了k8s集群之外的节点访问的k8s集群内的某个节点或者TCP/IP服务的时候,必须通过Node IP进行通信。
Pod IP是每个Pod的IP地址,它是Docker Engine根据docker0网桥的IP地址段进行分配的,通常是一个虚拟的二层网络。前面说过,k8s要求Pod里的容器访问另一个Pod的容器时,就是通过Pod IP所在的虚拟二层网络进行通信的,而真实的TCP/IP流量则是通过Node IP所在的物理网卡流出的。这个参考docker通信相关的细节。
最后看Service的Cluster IP,它也是一个虚拟的IP。更像一个假的IP:
- Cluster IP仅仅作用域k8s Service这个对象,并由k8s管理和分配IP地址(来源Cluster IP地址池)。
- Cluster IP无法被ping,因为没有一个“网络实体对象”来响应。
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备TCP/IP通信的基础,并且它们属于k8s集群这样一个封闭的空间,集群之外节点若想访问这个通信端口,需要做额外的操作。
- 在k8s集群之内,Node IP网、Pod IP网与Cluster IP网之间的通信,采用的是k8s自己设计的一种编程方式的特殊的路由规则,和我们熟知的IP路由有很大的不同。
那么基于上述,我们知道:Service的Cluster IP属于k8s集群内部的地址,无法在集群外部直接使用这个地址。那么矛盾在实际中就是开发的业务肯定是一部分提供给k8s集群外部的应用或用户使用的,典型的就是web,那用户如何访问。
采用NodePort是解决上述最直接、最常用、最有效的方法。
apiVersion: v1
kind: Service
metadata:
name: tomcat-service
spec:
type: NodePort
ports:
- port: 8080
nodePort: 31002
selector:
tier: frontend
nodePort: 31002这个属性表名我们手动指定tomcat-service的NodePort为31002,否则k8s就会自动分配一个可用的端口,这个端口我们可以直接在浏览器中访问:http://。
NodePort的实现方式就是在k8s集群里每个Node上为外部访问的Service开启一个对应的TCP监听端口,外部系统只要用任意一个Node的IP地址和具体的NodePort端口号就能访问这个服务。在任意的Node上运行netstat命令,我们就能看到NodePort端口被监听。
但NodePort并没有完全解决Service的所有问题,如负载均衡的问题。假如我们的集群中10个Node,则此时最好有一个均衡负载器,外部的请求只需要访问此负载均衡器的IP地址,则负载均衡器负责转发流量到后面某个Node的NodePort上面。
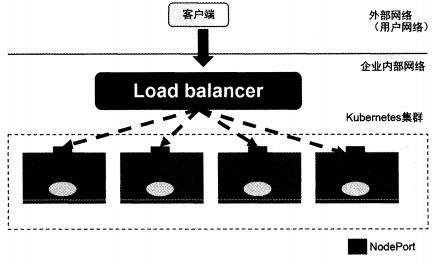
Load Balance组件独立于k8s集群之外,通常是一个硬件的负载均衡器或是软件方式实现的,如HAProxy或Nginx。对每个Service,我们通常配置一个对应的Load Balance的实例来转发流量到后端的Node上,这增加了工作量即出错的概率。
未完、待续……