之前我们已经讲了:
SpringBoot实现Java高并发秒杀系统之Web层开发(三)
SpringBoot实现Java高并发秒杀系统之Service层开发(二)
SpringBoot实现Java高并发秒杀系统之DAO层开发(一)
今天我们来分析一下秒杀系统的难点和怎么进行并发优化。
本项目的源码请参看:springboot-seckill 如果觉得不错可以star一下哦(#.#)
秒杀系统架构的设计和优化分析,以我一个小菜鸡,目前是说不出来的o(╥﹏╥)o。
因此呢,我这里仅从本项目已经实现的优化来介绍一下:
本项目中做到了以下优化:
- 秒杀接口采用md5加密方式防刷。
- 订单表使用联合主键方式,限制一个用户只能购买该商品一次。
- 配合Spring事务控制实现简单的优化。
- 使用redis缓存优化。
Spring的事务控制
Spring的声明式事务通过:传播行为、隔离级别、只读提示、事务超时、回滚规则来进行定义。
传播行为
事务的第一个方面就是传播行为。传播行为定义了客户端与被调用方法之间的事务边界。Spring定义了7中不同的传播行为,传播规则规定了何时要创建一个事务或何时使用已有的事务:
| 传播行为 | 含义 |
|---|---|
| PROPAGATION_MANDATORY | 表示该方法必须在事务中运行。如果当前事务不存在,则会抛出一个异常 |
| PROPAGATION_NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立与当前事务进行单独的提交或回滚 |
| PROPAGATION_NEVER | 表示当前方法不应该运行在事务上下文中,如果当前正在有一个事务运行,则会抛出异常 |
| PROPAGATION_NOT_SUPPORTED | 表示该方法不应该运行在事务中。 |
| PROPAGATION_REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否者,会启动一个新的事务 |
| PROPAGATION_REQUIRES_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动 |
| PROPAGATION_SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
隔离级别
声明式事务的第二个维度就是隔离级别。隔离级别定义了一个事务可能受其他并发事务影响的程度。多个事务并发运行,经常会操作相同的数据来完成各自的任务,但是可以回导致以下问题:
- 更新丢失:当多个事务选择同一行操作,并且都是基于最初的选定的值,由于每个事务都不知道其他事务的存在,就会发生更新覆盖的问题。
- 脏读:事务A读取了事务B已经修改但为提交的数据。若事务B回滚数据,事务A的数据存在不一致的问题。
- 不可重复读:书屋A第一次读取最初数据,第二次读取事务B已经提交的修改或删除的数据。导致两次数据读取不一致。不符合事务的隔离性。
- 幻读:事务A根据相同条件第二次查询到的事务B提交的新增数据,两次数据结果不一致,不符合事务的隔离性。
理想情况下,事务之间是完全隔离的,从而可以防止这些问题的发生。但是完全的隔离会导致性能问题,因为它通常会涉及锁定数据库中的记录。侵占性的锁定会阻碍并发性,要求事务互相等待以完成各自的工作。
因此为了实现在事务隔离上有一定的灵活性。因此,就会有多重隔离级别:
| 隔离级别 | 含义 |
|---|---|
| ISOLATION_DEFAULT | 使用后端数据库默认的隔离级别 |
| SIOLATION_READ_UNCOMMITTED | 允许读取尚未提交的数据变更。可能会导致脏读、幻读或不可重复读 |
| ISOLATION_READ_COMMITTED | 允许读取并发事务提交的数据。可以阻止脏读,但是幻读或不可重复读仍可能发生 |
| ISOLATION_REPEATABLE_READ | 对同一字段的多次读取结果是一致的,除非数据是被本事务自己所修改,可以阻止脏读和不可重复读,但幻读仍可能发生 |
| ISOLATION_SERIALIZABLE | 完全服从ACID的事务隔离级别,确保阻止脏读、不可重复读、幻读。这是最慢的事务隔离级别,因为它通常是通过完全锁定事务相关的数据库来实现的 |
回滚规则
Spring的事务管理器默认是针对unchecked exception回滚,也就是默认对Error异常和RuntimeException异常以及其子类进行事务回滚。
也就是说事务只有在遇到运行期异常才会回滚,而在遇到检查型异常时不会回滚。
这也就是我们之前设计Service业务层逻辑的时候一再强调捕获try catch异常,且将编译期异常转换为运行期异常。
简单优化
这里我们还是要关注一些项目中的两个核心的业务:1.减库存;2.插入购买明细。我们以一张图来看一下这两个操作的事务执行流程:

可以看到我们的秒杀操作主要是基于Mysql的事务进行的,而基于MySQL事务的秒杀操作主要瓶颈是网络延迟和GC(Java垃圾回收机制)。执行一条update语句首先要拿到MySQL的行级锁rowLock,而我们要解决的就是如何降低update对rowLock的持有时间。
我们先了解一下MySQL的InnoDB储存引擎的行级锁(rowLock):
- 行锁的劣势:开销大;加锁慢;会出现死锁
- 行锁的优势:锁的粒度小,发生锁冲突的概率低;处理并发的能力强
- 加锁的方式:自动加锁。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁;对于普通SELECT语句,InnoDB不会加任何锁;当然我们也可以显示的加锁:
- 共享锁:select * from tableName where ... + lock in share more
- 排他锁:select * from tableName where ... + for update
- InnoDB和MyISAM的最大不同点有两个:一,InnoDB支持事务(transaction);二,默认采用行级锁。加锁可以保证事务的一致性,可谓是有人(锁)的地方,就有江湖(事务)。
详细的介绍请看博文:MySQL 表锁和行锁机制
所以在此基础上我们可以进行简单的优化:
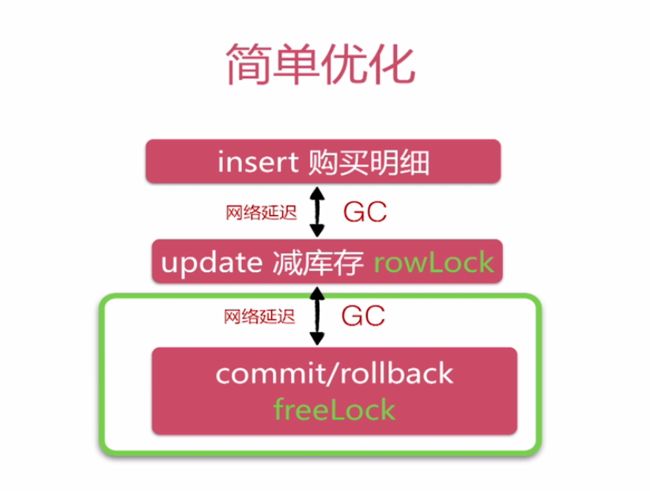
很简单,就是调整update和insert操作的执行顺序。目的就是为了缩短update对rowLock的持有时间提高性能,因为我们的查询语句使用了insert ignore into xx的方式来避免重复秒杀,那么闲执行insert语句可以在插入时就排除可能存在重复秒杀的操作,这样就不用再向下执行更新操作了。在一定程度上降低了一倍的rowLock持有时间。
下面是源码:
@Override
@Transactional
public SeckillExecution executeSeckill(long seckillId, BigDecimal money, long userPhone, String md5)
throws SeckillException, RepeatKillException, SeckillCloseException {
if (md5 == null || !md5.equals(getMD5(seckillId))) {
throw new SeckillException("seckill data rewrite");
}
//执行秒杀逻辑:1.减库存;2.储存秒杀订单
Date nowTime = new Date();
try {
//记录秒杀订单信息
int insertCount = seckillOrderMapper.insertOrder(seckillId, money, userPhone);
//唯一性:seckillId,userPhone,保证一个用户只能秒杀一件商品
if (insertCount <= 0) {
//重复秒杀
throw new RepeatKillException("seckill repeated");
} else {
//减库存
int updateCount = seckillMapper.reduceStock(seckillId, nowTime);
if (updateCount <= 0) {
//没有更新记录,秒杀结束
throw new SeckillCloseException("seckill is closed");
} else {
//秒杀成功
SeckillOrder seckillOrder = seckillOrderMapper.findById(seckillId);
return new SeckillExecution(seckillId, SeckillStatEnum.SUCCESS, seckillOrder);
}
}
} catch (SeckillCloseException e) {
throw e;
} catch (RepeatKillException e) {
throw e;
} catch (Exception e) {
logger.error(e.getMessage(), e);
//所有编译期异常,转换为运行期异常
throw new SeckillException("seckill inner error:" + e.getMessage());
}
}
Redis缓存优化
准备
如果想使用Redis缓存进行优化,首先你需要连接什么是Redis缓存,以及Spring提供的一种操作Redis缓存的框架:Spring-data-redis。最终要的是:你需要在本地电脑上安装好Redis缓存服务器:
所以呢,我推荐你看一下我的几篇文章:
Redis即Spring-data-redis入门学习
优雅的整合SSM+Shiro+Redis+Solr框架
在看了上面的文章后相信你已经初步了解了使用Spring-data-redis操作Redis缓存服务器,下面讲解针对本项目的缓存优化实现:
启动安装好的Redis缓存服务器,修改项目中的 resources/application.yml 关于Redis和Jedis的配置,
例中我使用的本地Redis服务器:host:127.0.0.1;port:6379
添加Redis、Jedis缓存配置
这里我们依赖:
org.springframework.boot
spring-boot-starter-data-redis
redis.clients
jedis
同时我们需要在application.yml中配置缓存:
#redis缓存
redis:
#redis数据库索引,默认是0
database: 0
#redis服务器地址,这里用本地的redis
host: 127.0.0.1
# Redis服务器连接密码(默认为空)
password:
#redis服务器连接端口,默认是6379
port: 6379
# 连接超时时间(毫秒)
timeout: 1000
jedis:
pool:
# 连接池最大连接数(使用负值表示没有限制)
max-active: 8
# 连接池最大阻塞等待时间(使用负值表示没有限制
max-wait: -1
# 连接池中的最大空闲连接
max-idle: 8
# 连接池中的最小空闲连接
min-idle: 0
实现Redis的序列化
1.创建JedisConfig
@Configuration
public class JedisConfig {
private Logger logger = LoggerFactory.getLogger(JedisConfig.class);
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.timeout}")
private int timeout;
@Value("${spring.redis.jedis.pool.max-active}")
private int maxActive;
@Value("${spring.redis.jedis.pool.max-idle}")
private int maxIdle;
@Value("${spring.redis.jedis.pool.min-idle}")
private int minIdle;
@Value("${spring.redis.jedis.pool.max-wait}")
private long maxWaitMillis;
@Bean
public JedisPool redisPoolFactory(){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxWaitMillis(maxWaitMillis);
jedisPoolConfig.setMaxTotal(maxActive);
jedisPoolConfig.setMinIdle(minIdle);
JedisPool jedisPool = new JedisPool(jedisPoolConfig, host, port, timeout, null);
logger.info("JedisPool注入成功");
logger.info("redis地址:" + host + ":" + port);
return jedisPool;
}
}
这里是为了将我们在application.yml中配置的参数注入到JedisPool中,使用Spring的@Value注解能读取到Spring配置文件中已经配置的参数的值
2.创建RedisTemplateConfig
@Configuration
public class RedisTemplateConfig {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
Jackson2JsonRedisSerializer 这一步才是真正实现Redis序列化的配置,当然,不实现序列化也是可以的,舍去上面两步,我们依然可以将数据放入到Redis缓存中。所以我们需要注意以下几点:
实现序列化目前而言不是必须的,因为我们使用了Spring-data-redis提供的高度封装的RedisTemplate模板类。
SpringBoot2.x实现Redis的序列化仍是由很多方案,但是我这里使用了Spring-data-redis提供的一种jackson2JsonRedisSerializer的序列化方式。
如果不实现Redis的序列化,可以往Redis中存入数据,但是存入的key都是乱码的,想要避免这一点就必须实现序列化。
这个步骤和我们之前整合SSM+Redis+Shiro+Solr框架中已经讲到了用XML实现序列化配置,这里仅是换成了Java配置而已。
优化findAll方法
秒杀列表(即查询findAll方法)也是经常被访问的,所以我们可以将商品数据放入Redis缓存中
调用findAll()方法得到的是一个List集合,而我们不能直接将一个List集合的数据放入缓存(key-value形式)中,我们必须指定key和value的为实体类中某个属性值。
所以本例中我们采用key: 秒杀商品ID值;value:秒杀商品数据(实体类)。
//设置秒杀redis缓存的key
private final String key = "seckill";
@Override
public List findAll() {
List seckillList = redisTemplate.boundHashOps("seckill").values();
if (seckillList == null || seckillList.size() == 0){
//说明缓存中没有秒杀列表数据
//查询数据库中秒杀列表数据,并将列表数据循环放入redis缓存中
seckillList = seckillMapper.findAll();
for (Seckill seckill : seckillList){
//将秒杀列表数据依次放入redis缓存中,key:秒杀表的ID值;value:秒杀商品数据
redisTemplate.boundHashOps(key).put(seckill.getSeckillId(), seckill);
logger.info("findAll -> 从数据库中读取放入缓存中");
}
}else{
logger.info("findAll -> 从缓存中读取");
}
return seckillList;
}
优化exportSeckillUrl方法
exportSeckillUrl()暴露接口的方法也是常调用的,因为其中要频繁的调用findById()方法,所以将指定ID的商品数据放入缓存中也是很必要的,当然我们在之前的findAll()方法中已经将每个ID的数据都分别放入了缓存中。
@Override
public Exposer exportSeckillUrl(long seckillId) {
Seckill seckill = (Seckill) redisTemplate.boundHashOps(key).get(seckillId);
if (seckill == null) {
//说明redis缓存中没有此key对应的value
//查询数据库,并将数据放入缓存中
seckill = seckillMapper.findById(seckillId);
if (seckill == null) {
//说明没有查询到
return new Exposer(false, seckillId);
} else {
//查询到了,存入redis缓存中。 key:秒杀表的ID值; value:秒杀表数据
redisTemplate.boundHashOps(key).put(seckill.getSeckillId(), seckill);
logger.info("RedisTemplate -> 从数据库中读取并放入缓存中");
}
} else {
logger.info("RedisTemplate -> 从缓存中读取");
}
Date startTime = seckill.getStartTime();
Date endTime = seckill.getEndTime();
//获取系统时间
Date nowTime = new Date();
if (nowTime.getTime() < startTime.getTime() || nowTime.getTime() > endTime.getTime()) {
return new Exposer(false, seckillId, nowTime.getTime(), startTime.getTime(), endTime.getTime());
}
//转换特定字符串的过程,不可逆的算法
String md5 = getMD5(seckillId);
return new Exposer(true, md5, seckillId);
}
优化executeSeckill方法
上面的两个查询操作都将商品数据放入了缓存中,key:商品ID;value:商品数据(实体类)。而对于减库存操作,用户每次抢购一件商品,商品的库存总量都需要-1,但是我们页面展示的数据都是从缓存中读取的,即使修改了数据库中的库存数量,页面上展示的数量仍是无法修改的,所以我们同时要修改缓存中的数据来保证缓存和数据库数据的一致性。
更新缓存的办法就简单了,即重新put进去数据就行了,因为Redis缓存数据库中存放的数据是key-value形式,你重新对指定key put进去新的值,就势必会覆盖掉原来的值(这也就是我们为什么设计key:商品ID;value:商品数据)。
@Override
@Transactional
public SeckillExecution executeSeckill(long seckillId, BigDecimal money, long userPhone, String md5)
throws SeckillException, RepeatKillException, SeckillCloseException {
if (md5 == null || !md5.equals(getMD5(seckillId))) {
throw new SeckillException("seckill data rewrite");
}
//执行秒杀逻辑:1.减库存;2.储存秒杀订单
Date nowTime = new Date();
try {
//记录秒杀订单信息
int insertCount = seckillOrderMapper.insertOrder(seckillId, money, userPhone);
//唯一性:seckillId,userPhone,保证一个用户只能秒杀一件商品
if (insertCount <= 0) {
//重复秒杀
throw new RepeatKillException("seckill repeated");
} else {
//减库存
int updateCount = seckillMapper.reduceStock(seckillId, nowTime);
if (updateCount <= 0) {
//没有更新记录,秒杀结束
throw new SeckillCloseException("seckill is closed");
} else {
//秒杀成功
SeckillOrder seckillOrder = seckillOrderMapper.findById(seckillId);
//更新缓存(更新库存数量)
Seckill seckill = (Seckill) redisTemplate.boundHashOps(key).get(seckillId);
seckill.setStockCount(seckill.getSeckillId() - 1);
redisTemplate.boundHashOps(key).put(seckillId, seckill);
return new SeckillExecution(seckillId, SeckillStatEnum.SUCCESS, seckillOrder);
}
}
} catch (SeckillCloseException e) {
throw e;
} catch (RepeatKillException e) {
throw e;
} catch (Exception e) {
logger.error(e.getMessage(), e);
//所有编译期异常,转换为运行期异常
throw new SeckillException("seckill inner error:" + e.getMessage());
}
}
交流
如果大家有兴趣,欢迎大家加入我的Java交流群:671017003 ,一起交流学习Java技术。博主目前一直在自学JAVA中,技术有限,如果可以,会尽力给大家提供一些帮助,或是一些学习方法,当然群里的大佬都会积极给新手答疑的。所以,别犹豫,快来加入我们吧!
联系
If you have some questions after you see this article, you can contact me or you can find some info by clicking these links.
- Blog@TyCoding's blog
- GitHub@TyCoding
- ZhiHu@TyCoding