1. 论文相关
2018

2.摘要
2.1 摘要
小样本学习的一个根本问题是训练中数据的缺乏。缓解这种稀缺性的一个自然解决方案是增加每个训练类的现有图像。然而,在图像空间中直接增加样本可能不一定,也不足以探索类内变化(intra-class variation)。为此,我们建议通过利用每个类的语义直接合成实例特征。本质上,提出了一种新的用于特征增强的自动编码网络对偶三元组(auto-encoder network dual TriNet)。编码器TriNet(encoder TriNet)将深层CNN的多层视觉特征投射到语义空间中。在该空间中,引入数据增强(data augmentation is induced),并通过解码器三元组将增强的实例表示投影回图像特征空间。本文探讨了语义空间中的两种数据增强策略,特别是语义空间中看似简单的增广导致了图像特征空间中复杂的增广特征分布,从而大大提高了性能。本文的代码和模型将发表在:https://github.com/tankche1/Semantic-Feature-Augmentation-in-Few-shot-Learning。
2.2 主要贡献
为了利用这种语义空间,我们提出了一种双三元结构(dual TriNet architecture)来学习多层图像特征与语义空间之间的转换。双三元组与18层残差网络(ResNet-18)[16]配对;它有编码器三元组和解码器三元组。具体来说,给定一个训练实例,我们可以使用ResNet-18来提取不同层次的特征。有效地将这些特征映射到语义空间中。在语义空间中,投影的实例特征可以被高斯噪声所破坏,也可以被其最近的语义词向量所代替。我们假设语义空间中特征值的微小变化将允许我们在扩展(spanning)潜在的类变化的同时维持语义信息。然后采用译码器TriNet()将语义实例特征映射回多层(ResNet-18)特征空间。值得注意的是,语义空间中的高斯增强/扰动(Gaussian augmentations/perturbations)最终导致原始特征空间中的高度非高斯增强。这是语义空间扩充的核心好处。通过使用三个经典的有监督分类器,我们证明了增强的实例特征可以提高小样本分类的性能。
总的来说,我们的贡献如下:
首先,我们提出了一个简单而优雅的深度学习体系结构:ResNet-18+dual TriNet,它具有一个高效的端到端训练,用于小样本分类。第二,提出的双三元网络(dual TriNet)可以有效地增强ResNet-18的多层视觉特征。第三,有趣的是,我们证明了我们可以利用各种类型的语义空间,包括语义属性空间、语义词向量空间,甚至由类的语义关系定义的子空间。最后,通过对四个数据集的大量实验,验证了该方法在解决小样本图像识别任务中的有效性。
2.3 相关工作
(1) Generally, these approaches can be roughly categorized as meta-learning algorithms (including MAML [38], Meta-SGD [39], DEML+Meta-SGD [40],META-LEARN LSTM [41], Meta-Net[42]) and Metric-learning algorithms (including Matching Nets [36], PROTO-NET [37], RELATION NET [43] and MACO [44]).
(2) Previous approaches can be categorized into six classes of methods: (1) Learning one-shot models by utilizing the manifold information of large amount of unlabelled data in a semi-supervised or transductive setting [3]; (2) Adaptively learning the one-shot classfiers from off-shelf trained models [4,5,6]; (3) Borrowing examples from relevant categories[7] or semantic vocabularies [49,50] to augment the training set; (4) Synthesiz-ing new labelled training data by rendering virtual examples [8,9,10,11,51] or composing synthesized representations [12,13,52,53,54,55] or distorting existing training examples [2]; (5) Generating new examples using Generative Adversarial Networks (GANs) [56,57,58,59,60,61,62,63]; (6) Attribute-guided augmentation(AGA) [14] to synthesize samples at desired values or strength.
linguistic model:语言模型
3. 用于语义数据扩充的双三元网络(Dual TriNet Network for Semantic Data Augmentation)
3.1 问题设置(Problem setup)
在迁移学习情境中,我们设计了小样本学习任务。假设源数据集,有N个样本。表示原始图像i。是一个类标签,其中是源类集;是实例在其类标签方面的语义向量。语义向量可以是语义属性[32)、语义词向量[15]或由类的语义关系推断出的任何子空间。
我们考虑目标数据集和每一类(),总类别标签设置为。特别是在小样本学习设置中,每个类只给出少量的训练实例。基于迁移的小样本学习的标准设置首先使用源数据集Ds来训练L层深层神经网络,其中是L层输出特征向量。在目标数据集上,我们使用经过训练的网络来提取第l级特征。这些目标数据集特征被用于以监督的方式训练分类器,并在测试时应用。通常,不同的层特征可用于各种单样本学习任务。例如,如[2],全连接层的特征可用于单样本图像分类;完全卷积层的输出特征可优选用于单样本图像分割任务[74、75、76]。

3.2 概述(Overview)
3.2.1 目的(Objective)
我们寻求直接增加每个目标类的训练实例特征。给定目标数据集的一个训练实例,特征提取网络可以输出实例特征;增强网络可以生成一组合成特征。这样的合成特征可以作为单样本学习任务的附加训练实例。如图1所示,我们使用ResNet-18[16]和提出了一个双三元网络作为特征提取网络和增强网络。整个体系结构通过结合两个网络的损失函数进行端到端的训练:
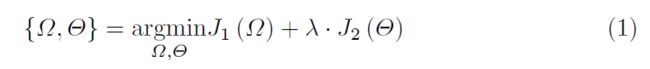
其中,和分别是ResNet-18[16]和双三元网的损失函数;Ω和Θ表示相应的参数。交叉熵损失用于,如[16]所示。公式(1)使用源数据集优化。
3.2.2 特征提取器网络
我们从头开始训练ResNet-18[16]将原始图像转换为图像特征向量。ResNet-18具有4个连续的残差层(4 sequential residual layers),即第1层、第2层、第3层和第4层,如图1所示。每个残差层输出对应的特征图。如果我们将每个特征图作为一个图像特征空间,ResNet-18实际上学习了多级图像特征(Multi-level Image Feature ,M-IF)表示。
3.2.3 增强网络(Augmentation network)
我们提出了一种编码器-解码器三元组结构-双三元组。如图1所示,我们的双三角网可以分为编码器三元组和解码器三元组。编码器TriNet将视觉特征空间映射到语义空间。这就是增强发生的地方。解码器TriNet将扩展的语义空间表示投影回特征空间。由于ResNet-18有四层,不同层产生的视觉特征空间可以使用相同的编解码三元组进行数据扩充。
3.3 双三元网络(Dual TriNet Network)
双三元网络与ResNet-18配对。从如此深的CNN体系结构的不同层获得的特征表示是分层的,从一般的(底层)到更具体的(顶层)[77]。例如,前几层产生的特征类似于Gabor滤波器[48],因此与任务无关的;相反,高层特定于特定任务,例如图像分类。ResNet-18生成的特征空间具有不同层次的抽象语义信息。因此,一个自然的问题是,我们是否可以在不同的层上增广特征?直接学习每一层的编解码器并不能充分利用不同层之间的关系,因而可能无法有效地学习特征空间和语义空间之间的映射。为此,我们提出了双三元网络。
双三元网络学习多级图像特征空间(MIF)和语义空间(Sem)之间的映射。语义空间可以是语义属性空间,也可以是3.1节中引入的语义词向量空间。语义属性可以由人类专家预先定义[14]。 语义词向量是每个词汇实体的投影,其中词汇表由word2vec[15]在大规模语料库中学习。此外,类间语义关系的奇异值分解(Singular Value Decomposition,SVD)可以扩展子空间。具体来说,我们可以使用用余弦相似度来计算类之间的语义关系。我们用SVD算法分解。是一个酉矩阵(unitary matrix),定义了一个新的语义空间。的每一行都作为一个类的新语义向量。
编码器TriNet由四层组成,对应于ResNet-18的每一层。它的目的是学习函数来映射实例的所有层特征尽可能得接近语义向量。子网的结构设计类似于河内塔(tower of Hanoi),如图1所示。这种结构可以有效地利用多层编码信息的差异性和互补性(differences and complementarity)。通过合并和组合不同层的输出,训练编码器TriNet来匹配ResNet-18的四个层。译码器TriNet具有完全相同的架构,将语义空间的特征映射到特征空间。我们通过优化以下损失来学习TriNet:
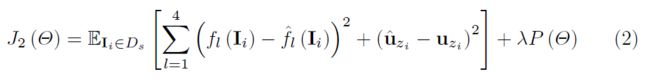
其中Θ表示双三元网络的参数集,是L2-正则项。双三元网络在上训练,在上测试。
3.4 双三元网络特征增强(Feature Augmentation by Dual TriNet)
通过学习对偶三元网络,我们有两种方法来增强训练实例的特征。
3.4.1 语义高斯(Semantic Gaussian,SG)
一种自然的特征增强方法是从高斯分布中抽取实例。特别是,对于通过ResNet-18提取的特征集,编码器TriNet可以投射到语义空间中。在这样的空间里,我们假设被随机高斯噪声破坏,语义标签不会改变。这可以用来扩充数据。具体地说,我们从语义高斯中采样语义向量,如下所示:

其中σ∈R是每个维度的方差;E是恒等矩阵(identity matrix;);σ控制所添加噪声的偏差(deviation)。为了使增强特征向量在类中仍然具有足够的代表性,我们经验地将σ设置为与其最近的其他类实例之间距离的15%,因为这提供了最佳性能。解码器三元网络生成与输入图像共享同一类标签的虚拟合成样本。通过稍微破坏语义向量的某些维度的值,我们期望采样向量仍然具有与相同的语义意义。
3.4.2 语义邻域(Semantic Neighbourhood ,SN)
受最近词汇学习(vocabulary-informed learning)的启发[49],语义词向量空间中的大量词汇(如word2vec[15])也可用于增强。尤其是这些词汇的分布反映了语料库中普遍存在的语义关系。例如,在词向量空间中,“truck”的向量比“dog”的向量更接近“car”的向量。考虑到训练实例的特征,可以从的邻域中抽取扩充数据,即:

表示的最近邻词汇集,W表示word2vec在大规模语料库中学习的词汇集[15]。这些邻居对应于与我们的训练实例语义最相似的示例。虚拟合成样本的特征可以通过解码。
我们要强调几点。(1)一个训练实例,我们使用等式(3)中的高斯平均值或等式(4)中的邻域中心,而不是它的基本真值向量。这是因为表示类的语义中心,而不是实例i的语义中心。实验上,在minimagenet数据集上,使用增强特征而不是的结果,将导致1-shot/5-shot分类的平均性能下降3∼5%。(2)公式(3)中加入语义高斯噪声或公式(4)中使用的语义邻域,由于解码器TriNet 和ResNet-18()的非线性,导致每个类的合成训练特征都是高度非线性(非高斯)的。(3)直接在中加入高斯噪声是另一种简单的增强特征的方法。然而,在minimagenet数据集中,这种策略并没有给我们在单样本分类中带来任何显著的改进。
3.5 单样本分类(One-shot Classication)
给定一幅训练图像,ResNet-18可以提取特征,对偶三元网络可以增强对应层的特征。因此,我们使用增强特征进行单样本分类。
与之前的工作一样[2,16],最后一层生成的特征用于单样本分类任务。增强的可以作为ResNet-18的第层输出。因此,通过使用作为第层的输入,我们可以计算增广的最终层表示。最后,将原始图像和增强特征的最后一层输出用于单样本分类。特别地,本文使用了三种经典的分类器,即K近邻(KNN)、支持向量机(SVM)和Logistic回归(LR),以说明我们的扩展框架可以帮助各种分类器。
4. 实验
4.1 数据集
我们在四个数据集上进行了实验。请注意(1)在所有数据集上,ResNet18仅在以前工作的指定拆分中在源数据集上进行训练。(2)所有数据集使用相同的网络和参数设置(包括输入图像的大小);因此所有图像的大小都调整为224*224。
4.1.1 miniImageNet
最初在[36]中提出,这个数据集有来自100个类的60000个图像。因此,每个类都有大约600个示例。为了使我们的结果比以前的工作更为准确,我们使用了[41]中的splits,分别使用64、16、20个类作为训练验证和测试集。
4.1.1 Cifar-100
它包含来自100个细粒度类别和20个粗级别类别的60000个图像[78]。与[79]相同的数据分割,以便与以前的方法进行比较。其中64、16、20个类分别作为训练验证和测试集。
4.1.1 Caltech-UCSD Birds 200-2011 (CUB-200)
这是一个细粒度的数据集,共有来自200种鸟类的11788幅图像[80]。在[44]中,我们使用100、50、50个类进行训练、验证和测试集。该数据集还提供312维向量中每个类的语义属性。
4.1.1 Caltech-256
它有来自256个类的30607个图像[81]。如[79]所示,我们将其分为150、56和50个类,分别用于训练、验证和测试。
4.2 网络结构和设置
所有四个数据集都使用相同的ResNet-18和dual Trinet。
4.2.1 参数(Parameters)
自动编码器网络的dropout rate和学习率分别设置为0.5和1e-3,以防止过拟合。每完成10个epoch,学习速率除以2。批大小设置为64。这个网络由Adam训练,通常会在300个epoch收敛。为了防止由于训练集太小而产生的随机性,所有的实验都作为每个数据集上的实验设置重复进行。准确度结果以95%的置信区间报告,并在多个测试集上平均,与之前的工作相同。部分训练代码和基线作为补充材料附在附件中。更多的源代码将在接受后发布。
4.2.2 设置
我们使用从[49]中发布的词汇词典中提取的100维语义词向量。类名作为向量或投影到空间中。 语义属性空间由专家预先定义为[32,80]。在所有的实验中,在一类语义空间中给定一个训练实例,双三元组将增加每一层的4个合成实例。除非另有说明,否则我们使用所有层生成的合成实例。
4.3 竞争对手和分类模型(Competitors and Classication models)
4.3.1 竞争对手
以前的方法与我们的源/目标和训练/测试设置相同。这些方法是匹配网络[36]、MAML[38]、Meta-SGD[39]、DEML+Meta-SGD[40]、PROTO-NET[37]、RELATION-NET[43]、Meta-LEARN LSTM[41]、Meta-NET[42]和MACO[44]。
4.3.2 分类模型
采用KNN、支持向量机和LR作为分类模型,验证了增强数据的有效性。在目标数据集上交叉验证分类模型的超参数。
4.4 ImageNet和CUB-200数据集的实验结果

4.4.1 设置
在minimagenet数据集上,我们只有语义词空间。给出了一个训练实例,分别对语义高斯(SG)和语义邻域(SN)的16个合成实例进行了扩充。在CUB-200数据集上,我们同时使用语义词向量和语义属性空间。因此,对于一个训练实例,我们在语义词向量空间中增加了16个和16个SG和SN的合成实例;另外,我们在语义属性空间中为语义高斯(SG)生成了16个虚拟实例(在所有四层中),称为属性高斯(AG)。
4.4.2 结果
如表所示。1、竞争对手可分为两类:元学习算法(包括MAML、元SGD、DEML+元SGD、元学习LSTM和元网络)和度量学习算法(包括匹配网、原型网、关系网和MACO)。我们报告ResNet-18(不增加数据)的结果,以提取训练实例的特征。并对框架(ResNet-18+Dual-TriNet)的精度进行了比较。双三分相合成ResNet-18的每一层特征,如果给定任何训练实例,如秒。3.4条。我们使用支持向量机对ResNet-18和ResNet-18+表中的双TriNet进行分类。一。特别是,我们发现,
(1)我们的框架可以达到最好的性能(Our framework can achieve the best performance)
如表所示。1.我们框架的结果,即ResNet-18+Dual TriNet可以达到最佳性能,并且我们可以在两个数据集上显示出明显的高于所有其他基线的差距。这验证了我们的框架在解决一次性学习任务方面的有效性。注意,Resnet-18非常有利于学习残差,它是一个非常好的用于一次性学习任务的特征抽取器。实际上,ResNet-18在两个数据集上的几次拍摄结果几乎超过了所有其他基线。注意DEML+Meta-SGD[40]使用ResNet-50作为基线模型,因此比ResNet-18有更好的一次性学习结果。尽管如此,利用DualTriNet的增强数据,我们可以观察到ResNet-18基线的明显改善。这进一步验证了我们的框架能够有效地解决一次性学习问题,具有很好的性能。

(2)我们的框架可以有效地增强多层特征(Our framework can e�ectively augment multiple layer features)
我们分析了每一层增强特征的有效性,如图(2-a)所示。在CUB-200和minimagenet上,我们报告了一次学习的结果。我们得到了几个结论:(1)仅使用一个单一层(如图(2-a)中的第1层-第4层)的增强特征,也有助于提高单发学习结果的性能。这验证了我们在一个框架中合成不同层特性的双重三元组的有效性。(2)使用所有层(Multi-L)的合成实例的结果甚至高于每个单层的结果。这表明不同层的增强特征在本质上是互补的。
(3)增强特征可以提高不同监督分类器的性能(Augmented features can boost the performance of different supervised classfiers)
我们的增强特征不是为一个特定的监督分类器设计的。为了显示这一点,如图(2-A)所示,三个经典监督分类器(即,图x(2-a)的x轴中的KNN、SVM和LR)。结果表明,我们的增强特征可以提高三个有监督分类器在一次分类情况下的性能。这进一步显示了我们的增强框架的有效性。
(4)The augmented features by SG, SN and AG can also improve few-shot learning results
我们比较了图(2-b)中不同语义空间中不同类型的特征增强方法。具体来说,我们比较了语义词向量空间中的SG和SN,以及语义属性空间中的AG。在CUB-200数据集上,SG、SN和AG的增强效果优于未经论证的结果。将SG、SN和AG中任意两种生成的合成实例特征相结合的精度可以比仅用SG、SN或AG生成的实例特征的精度进一步提高。这意味着SG、SN和AG的增强特征实例是互补的。最后,我们观察到,结合所有SG、SN和AG的增广实例,一次学习的准确性最高。

设置
在Caltech-256和CIFAR-100数据集上,我们还使用了语义词向量空间。在一个训练实例中,我们从ResNet-18的四个层分别合成了SG和SN的16个和16个实例特征。在这两个数据集上,竞争者的结果在[40]中得到了实现和报告。我们报告的结果是通过使用所有层的增强特征实例生成的,SG和SN都是这样。采用支持向量机分类器作为分类模型。
(5)即使是从类的语义关系中推断出的语义空间也能在我们的框架中很好地工作(Even the semantic space inferred from semantic relationship of classes can also work well in our framework)
为了说明这一点,我们再次比较图(2-b)中的结果。特别是利用语义词向量计算了minimagenet中类的相似度矩阵。利用奇异值分解法对相似度矩阵进行分解,将奇异值分解的左奇异向量扩展到一个新的语义空间。这样一个新的空间就被用来学习对偶三元组。采用语义高斯(SG)对新扩展空间中的实例特征进行扩展,实现了一次分类,并将结果表示为SVD-G。我们在图(2-b)中报告了在minimagenet数据集中这种SVD-G增强的结果。我们强调了几个有趣的观察结果。(1)SVD-G特征增强的结果仍优于未增强的结果。(2)SVD-G的准确度实际上比SG稍差,因为新的跨空间是从原来的语义词空间派生出来的。(3)SVD-G与SG之间的增广特征几乎没有互补信息,部分原因是语义词空间上存在新的空间。(4)如图(2-b)所示,SVD-G生成的增强特征也与SN生成的增强特征非常互补。这是因为在推导新的语义空间时没有使用额外的邻域词汇信息。我们在CUB-200上得到了类似的实验结论,结果见补充材料。
4.5 Experimental results on Caltech-256 and CIFAR-100 datasets
结果
Caltech-256和CIFAR-100的结果在表中进行了比较。2。我们发现(1)我们的方法仍然可以达到最好的结果超过最新的算法,仍然要感谢扩充的特征实例提出的框架。(2)ResNet-18仍然是一个很强的基线,除DEML+Meta-SGD使用ResNet50作为基线结构外,它几乎可以击败所有其他基线。(3)与仅使用ResNet-18相比,使用我们的扩展实例功能有明显的改进余地。这进一步验证了拟议框架的有效性。
5 进一步分析
5.1双三元结构
我们提出了双三元组结构,它本质上来源于编码器-解码器结构。因此,我们进一步分析了用于特征增强的其他可选网络结构。具体地说,增强网络的替代选择可以是每一层的自动编码器[82]或U-net[83]。结果在表中进行比较。三。我们可以证明,我们的双三分集能够很好地探索不同层的互补信息,因此我们的结果比不增强(ResNet-18)、U-net增强(ResNet-18+U-net)和自动编码器增强(ResNet18+auto-encoder)的结果要好。这证明了我们的对偶三元网能够有效地融合和利用多层信息进行特征增强。
5.2 可视化
利用文献[84]中的技术,我们可以可视化生成ResNet-18中的增强特征f(Ii)=g(fl(Ii))的图像。我们首先随机生成一个图像Ii。然后,我们通过减小fl(Ii)和f(Ii)之间的距离来优化Ii(两者都是ResNet-18的输出):

其中R(·)是用于图像平滑度的总变化正则化器;当差值足够小时,λ=1e−2,ii应是能够生成相应增强特征的图像。
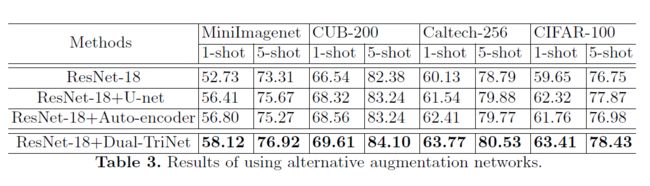
通过使用SN和上面的可视化算法,我们将图3中的原始特征和增强特征可视化。最上面一行显示了两只鸟,一个屋顶和一只狗的输入图像。蓝色圆圈和红色圆圈分别表示第一层和第四层的原始特征和增强特征的可视化。增强特征的可视化是相似的,但不同于原始特征的可视化。例如,前两列显示了增强特征的可视化实际上稍微改变了鸟的头部姿势。在最后两列中,增强的特征清楚地显示了一只与输入图像相似但外观不同的狗。这直观地说明了我们的框架工作的原因。
6. 结论
这项工作的目的是为特征增强提供一个端到端的框架。提出的对偶三元结构可以有效地直接增强多层视觉特征,提高小样本分类的效率。我们证明我们的框架可以有效地解决四个数据集上的小样本分类问题。我们主要对分类任务进行评估,这也是一项有趣的工作,也是将来在其他相关任务中利用增强特征的工作,例如单样本图像/视频分割[75,76]。另外,虽然这里的dual TriNet与ResNet18配对,但是我们可以很容易地将其扩展到其他特征抽取器网络,例如ResNet-50。因此被视为未来的另一项工作。
参考资料
[1]
[2]
[3]
论文下载
[1] Semantic feature augmentation in few-shot learning
在线测试链接
[1] https://nvlabs.github.io/FUNIT/petswap.html
代码
[1] # tankche1/Semantic-Feature-Augmentation-in-Few-shot-Learning