Scrapy-Redis分布式爬虫组件
Scrapy是一个框架,他本身是不支持分布式的。如果我们想要做分布式的爬虫。就需要借助一个组件叫做Scrapy-Redis。这个组件正式利用了Redis可以分布式的功能,继承到Scrapy框架中,使得爬虫可以进行分布式,可以充分的利用资源(多个ip,更多带宽,同步爬取)来提高爬虫的爬取效率。
-分布式爬虫组件的优点:
1.可以充分利用多台机器的带宽
2.可以充分利用多台机器的ip地址
3.多台机器工作,io频率提高,爬取效率更高
-分布式爬虫需要解决的问题:
1.分布式爬虫是好几个台式机器在同时运行,保证不同的机器爬取页面的时候不会出现重复爬取的问题。
2.同样,分布式爬虫在不同的机器上运行,在把数据爬取完后如何保存在同一个地方。
Scrapy 框架图
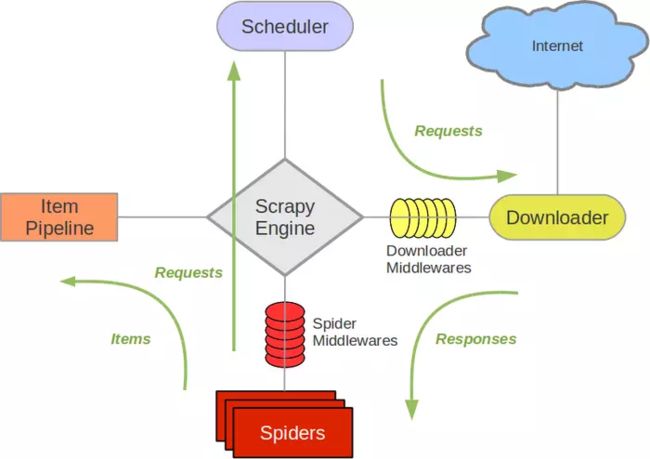
Scrapy-Redis
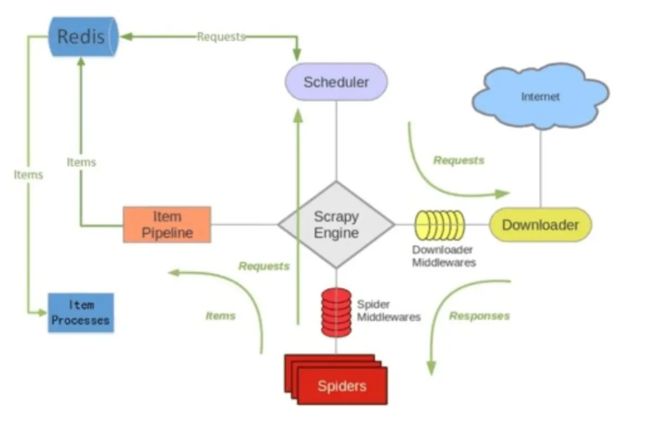
-分布式架构图:

Redis教程:
概述
redis是一种支持分布式的nosql数据库,他的数据是深存在内存中,同时可以将数据持久化,并且他比memcached 支持更多的数据结构(string,list,set,sorted set(有序集合),hash(hash)
redis使用的场景:
1.登录会话存储在redis中。memcached(缓存)
2.作为消息队列,‘celary’使用redis作为中间人(消息队列)
3.排行版/计数器:比如一些秀场类的项目,经常会有一些钱多少名的主播排名,或者点赞数之类的(计数器)
4. 当前在线人数,会显示当前系统多少在线人数。
5.一些常用的数据缓存:一些论坛,模块不会经常变化。但是每次访问首页都要从MySQL中获取,可以在redis中缓存起来,不用每次请求数据库。
6.把前200篇文章缓存或者评论缓存;一般用户浏览网站,只会浏览前面一部分文章或者评论,那么可以把前面200篇文章和对应的评论缓存起来,用户访问超时的,就访问数据库,并且以后文章超过200篇,则把之前的文章删除。
7.好友关系,微博的好友关系使用redis实现。
8.发布和订阅功能,可以用来聊天软件
具体分布式区别:https://www.cnblogs.com/457248499-qq-com/p/7392653.html