本文主要讨论netty的实现以及其在rpc(hsf)的使用,同时探讨下多线程下下文切换对系统的影响。
本文主要内容:
- netty的结构和线程模型
- 线程切换、context switch、mode switch对系统的影响
- netty高性能,以及在hsf中的实现
1、总体结构
netty的总体结构如图:
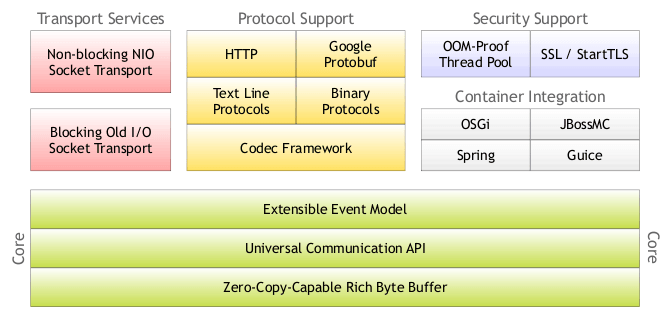
netty中主要的部分:
- 传输:Java nio
- 线程:reactor线程模型-nioEventLoop
- 通道:Channel、ChannelPipeline、ChannelHandler、ChannelHandlerContext
- 缓冲:ByteBuf
- 编解码:Codec框架
- 引导器:Bootstrap
- 协议支持:http、spy、memcache
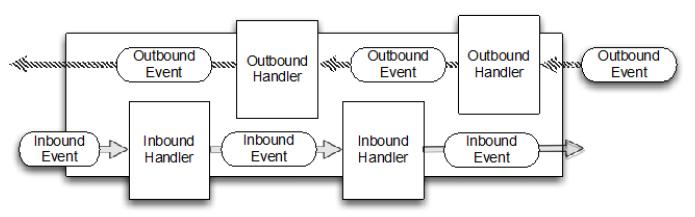
1、线程模型
1.1 reactor线程模型
1.1.1 reactor模型
reactor:反应堆
The reactor design pattern is an event handling pattern for handling service requests delivered concurrently by one or more inputs. The service handler then demultiplexes the incoming requests and dispatches them synchronously to associated request handlers.
Reactor模式首先是事件驱动的,有一个或多个并发输入源,有一个Service Handler,有多个Request Handlers;这个Service Handler会同步的将输入的请求(Event)多路复用的分发给相应的Request Handler。
从结构上有点类似生产者消费者模式,即有一个或多个生产者将事件放入一个Queue中,而一个或多个消费者主动的从这个Queue中Poll事件来处理;而Reactor模式则并没有Queue来做缓冲,每当一个Event输入到Service Handler之后,该Service Handler会主动的根据不同的Event类型将其分发给对应的Request Handler来处理。
1.1.2 reactor单线程模型
Reactor单线程模型,指的是所有的IO操作都在同一个NIO线程上面完成,NIO线程的职责如下:
- 作为NIO服务端,接收客户端的TCP连接;
- 作为NIO客户端,向服务端发起TCP连接;
- 读取通信对端的请求或者应答消息;
- 向通信对端发送消息请求或者应答消息。

1.1.3 reactor多线程模型
Rector多线程模型与单线程模型最大的区别就是有一组NIO线程处理IO操作。
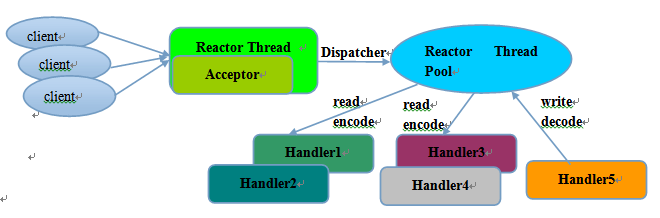
- 有专门一个NIO线程-Acceptor线程用于监听服务端,接收客户端的TCP连接请求;
- 网络IO操作-读、写等由一个NIO线程池负责,线程池可以采用标准的JDK线程池实现,它包含一个任务队列和N个可用的线程,由这些NIO线程负责消息的读取、解码、编码和发送;
- 1个NIO线程可以同时处理N条链路,但是1个链路只对应1个NIO线程,防止发生并发操作问题。
1.1.4 主从多线程模型
服务端用于接收客户端连接的不再是个1个单独的NIO线程,而是一个独立的NIO线程池。Acceptor接收到客户端TCP连接请求处理完成后(可能包含接入认证等),将新创建的SocketChannel注册到IO线程池(sub reactor线程池)的某个IO线程上,由它负责SocketChannel的读写和编解码工作。Acceptor线程池仅仅只用于客户端的登陆、握手和安全认证,一旦链路建立成功,就将链路注册到后端subReactor线程池的IO线程上,由IO线程负责后续的IO操作。

利用主从NIO线程模型,可以解决1个服务端监听线程无法有效处理所有客户端连接的性能不足问题。
它的工作流程总结如下:
- 从主线程池中随机选择一个Reactor线程作为Acceptor线程,用于绑定监听端口,接收客户端连接;
- Acceptor线程接收客户端连接请求之后创建新的SocketChannel,将其注册到主线程池的其它Reactor线程上,由其负责接入认证、IP黑白名单过滤、握手等操作;
- 之后,业务层的链路正式建立,将SocketChannel从主线程池的Reactor线程的多路复用器上摘除,重新注册到Sub线程池的线程上,用于处理I/O的读写操作。
2 netty中的reactor线程
2.1 NioEventLoop.run
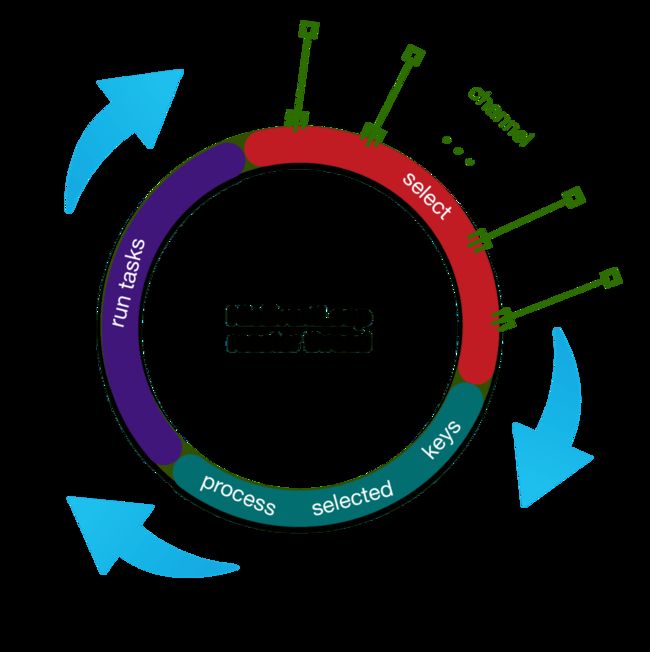
netty中的reactor线程(NioEventLoop)主要是轮询做以下三件事:
- 轮询io事件
- 处理轮询到事件
- 执行任务队列中的任务
NioEventLoop中的run方法:
protected void run() {
boolean oldWakenUp = wakenUp.getAndSet(false);
try {
if (hasTasks()) {
selectNow();
} else {
select(oldWakenUp);
if (wakenUp.get()) {
selector.wakeup();
}
}
cancelledKeys = 0;
needsToSelectAgain = false;
final int ioRatio = this.ioRatio;
if (ioRatio == 100) {
processSelectedKeys();
runAllTasks();
} else {
final long ioStartTime = System.nanoTime();
processSelectedKeys();
final long ioTime = System.nanoTime() - ioStartTime;
runAllTasks(ioTime * (100 - ioRatio) / ioRatio);
}
if (isShuttingDown()) {
closeAll();
if (confirmShutdown()) {
cleanupAndTerminate(true);
return;
}
}
} catch (Throwable t) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// Ignore.
}
}
scheduleExecution();
}
1)、首先轮询注册到reactor线程对用的selector上的所有的channel的IO事件
if (hasTasks()) {
selectNow();
} else {
select(oldWakenUp);
if (wakenUp.get()) {
selector.wakeup();
}
}
2)、处理产生网络IO事件的channel
private static void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
if (!k.isValid()) {
unsafe.close(unsafe.voidPromise());
return;
}
try {
int readyOps = k.readyOps()
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
if (!ch.isOpen()) {
// Connection already closed - no need to handle write.
return;
}
}
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
ch.unsafe().forceFlush();
}
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
int ops = k.interestOps();
ops &= ~SelectionKey.OP_CONNECT;
k.interestOps(ops);
unsafe.finishConnect();
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
3)、处理任务队列
protected boolean runAllTasks(long timeoutNanos) {
fetchFromScheduledTaskQueue();
Runnable task = pollTask();
if (task == null) {
return false;
}
final long deadline = ScheduledFutureTask.nanoTime() + timeoutNanos;
long runTasks = 0;
long lastExecutionTime;
for (;;) {
try {
task.run();
} catch (Throwable t) {
logger.warn("A task raised an exception.", t);
}
runTasks ++;
// Check timeout every 64 tasks because nanoTime() is relatively expensive.
// XXX: Hard-coded value - will make it configurable if it is really a problem.
if ((runTasks & 0x3F) == 0) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
if (lastExecutionTime >= deadline) {
break;
}
}
task = pollTask();
if (task == null) {
lastExecutionTime = ScheduledFutureTask.nanoTime();
break;
}
}
this.lastExecutionTime = lastExecutionTime;
return true;
}
2.3. NioEventLoop设计原理
2.3.1 串行化设计避免线程竞争
系统运行过程中如果频繁的进行线程上下文切换,会带来额外的性能损耗,多线程并发执行某个业务流程,业务开发者还需要时刻对线程安全保持警惕,哪些数据可能会被并发修改,如何保护,这不仅降低了开发效率,也会带来额外的性能损耗。
串行执行Handler链
ntLoop负责,这就意外着整个流程不会进行线程上下文的切换,数据也不会面临被并发修改的风险,对于用户而言,甚至不需要了解Netty的线程细节,这确实是个非常好的设计理念。
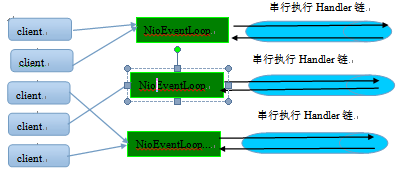
一个NioEventLoop聚合了一个多路复用器Selector,因此可以处理成百上千的客户端连接,Netty的处理策略是每当有一个新的客户端接入,则从NioEventLoop线程组中顺序获取一个可用的NioEventLoop,当到达数组上限之后,重新返回到0,通过这种方式,可以基本保证各个NioEventLoop的负载均衡。一个客户端连接只注册到一个NioEventLoop上,这样就避免了多个IO线程去并发操作它。
Netty通过串行化设计理念降低了用户的开发难度,提升了处理性能。利用线程组实现了多个串行化线程水平并行执行,线程之间并没有交集,这样既可以充分利用多核提升并行处理能力,同时避免了线程上下文的切换和并发保护带来的额外性能损耗。
2.3.2 定时任务与时间轮算法
在Netty中,有很多功能依赖定时任务,比较典型的有两种:
- 客户端连接超时控制
- 链路空闲检测
一种比较常用的设计理念是在NioEventLoop中聚合JDK的定时任务线程池ScheduledExecutorService,通过它来执行定时任务。这样做单纯从性能角度看不是最优:
- 在IO线程中聚合了一个独立的定时任务线程池,这样在处理过程中会存在线程上下文切换问题,这就打破了Netty的串行化设计理念
- 存在多线程并发操作问题,因为定时任务Task和IO线程NioEventLoop可能同时访问并修改同一份数据
- JDK的ScheduledExecutorService从性能角度看,存在性能优化空间
最早面临上述问题的是操作系统和协议栈,例如TCP协议栈,其可靠传输依赖超时重传机制,因此每个通过TCP传输的 packet 都需要一个 timer来调度 timeout 事件。这类超时可能是海量的,如果为每个超时都创建一个定时器,从性能和资源消耗角度看都是不合理的。
根据George Varghese和Tony Lauck 1996年的论文《Hashed and Hierarchical Timing Wheels: data structures to efficiently implement a timer facility》提出了一种定时轮的方式来管理和维护大量的timer调度。Netty的定时任务调度就是基于时间轮算法调度,下面我们一起来看下Netty的实现。
定时轮是一种数据结构,其主体是一个循环列表,每个列表中包含一个称之为slot的结构,它的原理图如下:
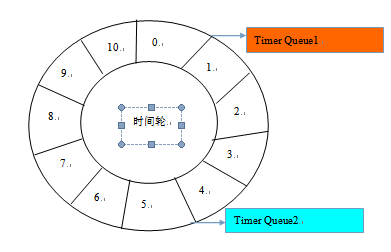
Netty的时间轮是由单线程调度,因此在时间调度过程中不适合做耗时的操作,在配一个调度周期内最多只会执行10w个任务。
private void transferTimeoutsToBuckets() {
for (int i = 0; i < 100000; i++) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
// all processed
break;
}
if (timeout.state() == HashedWheelTimeout.ST_CANCELLED) {
// Was cancelled in the meantime.
continue;
}
long calculated = timeout.deadline / tickDuration;
timeout.remainingRounds = (calculated - tick) / wheel.length;
final long ticks = Math.max(calculated, tick); // Ensure we don't schedule for past.
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
bucket.addTimeout(timeout);
}
}
注:每次调度结束之后HashedWheelTimeout任务会被删除,所以如果要周期性的执行某一任务,则需要在每次调度之后再将其加入调度队列。
Boss Group每个端口平时好像就只占1条线程,无论配了多少。
2、context switch & mode switch
2.1 context switch
进程/线程发生上下文切换的原因有:
- I/O等待:在多任务系统中,进程主动发起I/O请求,但I/O设备还没有准备好,所以会发生I/O阻塞,进程进入Wait状态。
- 时间片耗尽:在多任务分时系统中,内核分配给进程的时间片已经耗尽了,进程进入Ready状态,等待内核重新分配时间片后的执行机会。
- 硬件中断:在抢占式的多任务分时系统中,I/O设备可以在任意时刻发生中断,CPU会停下当前正在执行的进程去处理中断,因此进程进入Ready状态。
The main distinction between a thread switch and a process switch is that during a thread switch, the virtual memory space remains the same, while it does not during a process switch. Both types involve handing control over to the operating system kernel to perform the context switch. The process of switching in and out of the OS kernel along with the cost of switching out the registers is the largest fixed cost of performing a context switch.
A more fuzzy cost is that a context switch messes with the processors cacheing mechanisms. Basically, when you context switch, all of the memory addresses that the processor "remembers" in it's cache effectively become useless. The one big distinction here is that when you change virtual memory spaces, the processor's Translation Lookaside Buffer (TLB) or equivalent gets flushed making memory accesses much more expensive for a while. This does not happen during a thread switch
进程和线程的上下文切换都涉及进出系统内核和寄存器的保存和还原,这是它们的最大开销。但与进程的上下文切换相比,线程还是要轻量一些,最大的区别是线程上下文切换时虚拟内存地址保持不变,所以像TLB等CPU缓存不会失效。
Context Switch必须在内核中完成,原理简单说就是主动触发一个软中断,所以一般Context Switch都会伴随Mode Switch。
2.2 mode switch
用户态:Ring3运行于用户态的代码则要受到处理器的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中I/O许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问。
内核态:Ring0在处理器的存储保护中,核心态,或者特权态(与之相对应的是用户态),是操作系统内核所运行的模式。运行在该模式的代码,可以无限制地对系统存储、外部设备进行访问。
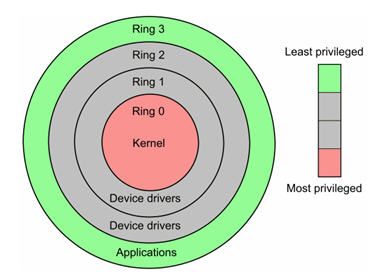
用户态切换到内核态的3种方式
- 系统调用:这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断。
- 异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常。
- 外围设备的中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的。
进程通常运行在用户态,只有触发CPU的exception才能进入内核态。此时用户的控制流被挂起,内核接管程序的运行;exception处理完毕后回到用户态,(如果需要的话)在原先的断点处继续执行。

Exception的分类
- interrupt,硬件发起,异步(即独立于CPU),下面3种都是同步的(必须由CPU执行某条指令触发)。
- fault,可能可以恢复,处理后返回引起错误的指令,如Page Fault。
- abort,无法恢复,不返回。
- trap / system call,程序主动发起,调用操作系统服务的方式,handler 执行完毕后返回下一条指令
System Call 和 普通函数调用 的区别
System Call通过寄存器传递异常号和参数,System Call的处理流程(其他Exception类似):
- 修改CPU的特权模式,进入内核态
- 根据异常号查表(Interrupt Descriptor Table, IDT)找处理程序入口
- 保存现场(如EIP/ESP/通用寄存器等)
- 切换到内核栈
- 执行处理程序
- 恢复现场
- 修改CPU的特权模式,回到用户态
步骤更多(CPU mode切换 / 查表 / 现场的保存和恢复 / 切到内核栈),因此比普通的函数调用开销更大。
syscall目前的主要overhead在进了kernel后所有参数使用前都要先过安检,各种descriptor都要查owner查权限,内存的权限不同架构和实现不太一样,但一般x86也要查一遍pte。因为在kernel mode下什么都是可以访问的,但是syscall是kernel代理user程序做privileged访问,所以每次都要仔细检查user的权限够不够。 syscall的实现代码一般都有明显的两层结构,外面一层就是在查权限,里面一层才干实事儿。这层安检是syscall这种简单的分层架构下恐怕永远没办法省的。
2.3 context switch & mode switch的区别和联系
context switch happens only in kernel mode. If context switching happens between two user mode processes, first cpu has to change to kernel mode, perform context switch, return back to user mode and so on. So there has to be a mode switch associated with a context switch.
Mode Switch - When a single process mode is switched from user-level to kernel-level or the other way around. It happens through the system calls. When a process call the system call, the process mode will change to kernel-mode and the kernel will start acting on behalf of the user process. And once the system call returns the process mode will change from kernel-mode to user-mode. "Mode" is a property associated with the process. So, a mode switch is switch of the mode of a single process.
Context Switch - It is when the running process current state is stored some place and a new process is chosen for running and its already stored state is loaded in the CPU registers. And now the new process starts running. This whole "context switch" procedure is done by the "Process Scheduler".
3、netty高性能之道
- 线程数控制:高并发下如果线程较多时,Context Switch会非常明显,超过CPU核心数的线程不会带来任何好处。不是特别耗时的操作的话,业务线程池也是有害无益的。Netty 5为我们提供了指定底层线程池的机会,这样能更好的控制整个中间件的线程数和调度策略。
- 非阻塞I/O操作:要想线程少还多做事,避免阻塞是一定要做的。
- 减少系统调用:虽然Mode Switch比Context Switch的开销要小得多,但我们还是要尽量减少频繁的syscall。
- 数据零拷贝:从内核空间的Direct Buffer拷贝到用户空间,每次透传都拷贝的话累积起来是个不小的开销。
- 共享状态保护:中间件内部的并发处理也是决定性能的关键。
4、复杂网络编程——hsf基于Netty的网络可靠性设计
4.1 可靠长连接
TCP提供维持长连接的机制:开启SO_KEEPALIVE。
如果要使用TCP提供的keep-alive机制,需要修改tcp_keepalive_time, tcp_keepalive_intvl,tcp_keepalive_probs为更小一些的值。
但是真实的网络很复杂,可能会有各种原因使tcp keep-alive失效,KeepAlive本质上来说,是用来检测长时间不活跃的连接的。所以,不适合用来及时检测连接的状态。采用应用层心跳包的机制会更灵活可靠。
4.2 HSF consumer对provider是否存活的感知
当客户端与服务端建立长连接之后,采用心跳检测机制,一旦发现网络故障则立即关闭链路。
客户端第一次与服务端建立链接后,就会周期性(27s)发送心跳包的callback调用
如果连续三次收不到服务端的心跳包回应,客户端主动关闭链接,调用io.netty.channel.AbstractChannel#close()
在服务端心跳包的处理方法中打上断点进行验证,模拟服务端高负荷,比如full gc中,处理不了心跳包的callback调用(或者对方网络不可用),即会出现超时。

4.3 服务端断网
1)、在断网的情况下,如果客户端还没有跟该服务端建立连接,ConfigServer收不到该服务端的心跳包,会将更新过后的服务地址推送到客户端,这样就保证客户端内存中的地址列表是可用的。
2)、如果已经建立连接,心跳包请求或者正常调用时socket会抛出异常,这时HSF会关闭该连接,客户端会对该连接上的请求返回网络异常。
private void doWrite(Object response, ChannelFutureListener listener) {
if (response != null) {
if (channel.isWritable()) {
ChannelFuture wf = channel.writeAndFlush(response);
wf.addListener(listener);
}
}
}
private class CloseOnFailureListener implements ChannelFutureListener {
public void operationComplete(ChannelFuture future) throws Exception {
if (!future.isSuccess()) {
LOGGER.error("", LogConstants.PREFIX_IMPORTANT + "server write response error: " + channel + " , remote ip is [ " + NettyConnection.this.getPeerIP() + "]"
+ ((null != future.cause()) ? ", cause:" + future.cause() : ""));
// need response or not under this condition?
// this.sendErrorResponse(NettyConnection.this, request);
if (!channel.isActive()) {
channel.close();
}
}
}
}
可以通过请求发送,服务端业务线程打上断点,然后关闭服务端进程进行模拟,客户端执行io.netty.channel.ChannelInboundHandlerAdapter#channelInactive,此时客户端会处理所有已发出的请求,返回异常,会打出该日志。这种在网络闪断或者服务端重启时会出现。
invalid call is removed because of connection closed
4.4 客户端缓存连接
如果经过27分钟没有使用(使用Guava Cache,cacheClients.get),释放掉连接,环境内存和服务器连接压力;不适合推送场景。会打出以下日志:
[Remoting] removed from cache

注意:这里是指client端在27分钟内没有使用连接,也就是27分钟内没有新的rpc请求,而client自身的心跳还是在继续,两者不要搞混。
4.5 服务端主动关闭连接
服务端定时扫描,当连接59s没有调用(对方网络不可用,或者full gc太久),相当于两次(2*27s)收不到心跳包的时间,或者客户端load过高,则会主动关闭连接。
WARN [HSF-Remoting-Timer-9-thread-1:t.hsf] [] [] [] L:/30.9.76.252:12202,R:/30.9.76.252:49616 is closed by server's scanRunner

4.6 客户端宕机
客户端建连后,服务端Reactor线程断点,模拟服务端阻塞,客户端会返回超时异常,客户端进程退出后,此时的服务端tcp状态为CLOSE_WAIT,释放不了文件句柄,很容易出现too many open files的异常。
释放断点后,netty成功释放链接,Netty是可以感知到链路关闭异常并进行正确处理的。
Netty在读写失败的时候都会抛出IOException,在捕获IOException之后都会主动close()。
outBound,写失败

inBound,读失败

4.7 客户端连接超时
Netty client 创建连接时的超时时间设置默认4000ms,在configserver推下来的ip创建连接不成功时,会打出下面日志。
com.ali.com.google.common.util.concurrent.UncheckedExecutionException: com.taobao.hsf.remoting.exception.RemotingUncheckedException: Create connection to 10.178.2.160:12200 timeout (4000)
4.8 优雅退出
HSF中netty的优雅退出

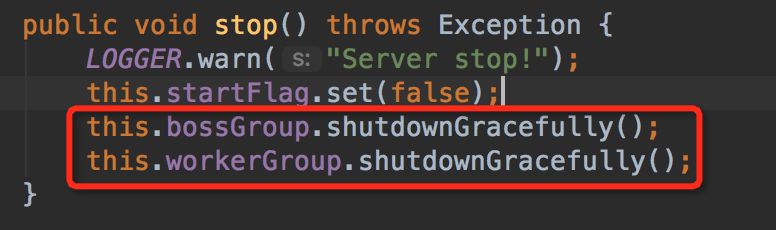
总结
在客户端和服务端正常通信过程中,如果发生网络闪断、对方进程突然宕机或者其它非正常关闭链路事件时,TCP链路就会发生异常。由于TCP是全双工的,通信双方都需要关闭和释放Socket句柄才不会发生句柄的泄漏。Netty的channel在写操作时,可以感知链路网络异常,这时客户端定时的心跳包发送可以保证在客户端及时检测到链接的不可用,然后HSF进行关闭连接操作。服务端也对连接做异常检测,及时关闭不可以用连接。