MySQL 原理篇
MySQL 索引机制
MySQL 体系结构及存储引擎
MySQL 语句执行过程详解
MySQL 执行计划详解
MySQL InnoDB 缓冲池
MySQL InnoDB 事务
MySQL InnoDB 锁
MySQL InnoDB MVCC
MySQL InnoDB 实现高并发原理
MySQL InnoDB 快照读在RR和RC下有何差异
数据准备:
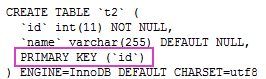
/* SQLyog Ultimate v12.09 (64 bit) MySQL - 5.6.17 : Database - test ********************************************************************* */ /*!40101 SET NAMES utf8 */; /*!40101 SET SQL_MODE=''*/; /*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */; /*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */; /*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */; /*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */; CREATE DATABASE /*!32312 IF NOT EXISTS*/`test` /*!40100 DEFAULT CHARACTER SET utf8 */; USE `test`; /*Table structure for table `t2` */ DROP TABLE IF EXISTS `t2`; CREATE TABLE `t2` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; /*Data for the table `t2` */ insert into `t2`(`id`,`name`) values (1,'1'),(4,'4'),(7,'7'),(10,'10'); /*Table structure for table `teacher` */ DROP TABLE IF EXISTS `teacher`; CREATE TABLE `teacher` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(32) NOT NULL, `age` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4; /*Data for the table `teacher` */ insert into `teacher`(`id`,`name`,`age`) values (1,'seven11124',18),(2,'qingshan',18); /*Table structure for table `user_account` */ DROP TABLE IF EXISTS `user_account`; CREATE TABLE `user_account` ( `id` int(11) NOT NULL DEFAULT '0', `balance` int(11) NOT NULL, `lastUpdate` datetime NOT NULL, `userID` int(11) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; /*Data for the table `user_account` */ insert into `user_account`(`id`,`balance`,`lastUpdate`,`userID`) values (1,3200,'2018-12-06 13:27:57',1),(2,50,'2018-12-06 13:28:08',2),(3,1000,'2018-12-06 13:28:22',3); /*Table structure for table `users` */ DROP TABLE IF EXISTS `users`; CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(32) NOT NULL, `age` int(11) NOT NULL, `phoneNum` varchar(32) NOT NULL, `lastUpdate` datetime NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `idx_eq_name` (`name`) ) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8mb4; /*Data for the table `users` */ insert into `users`(`id`,`name`,`age`,`phoneNum`,`lastUpdate`) values (1,'seven',26,'13666666666','2018-12-07 19:22:51'),(2,'qingshan',19,'13777777777','2018-12-08 21:01:12'),(3,'james',20,'13888888888','2018-12-08 20:59:39'),(4,'tom',99,'13444444444','2018-12-06 20:34:10'),(6,'jack',91,'13444444544','2018-12-06 20:35:07'),(11,'jack1',33,'13441444544','2018-12-06 20:36:19'),(15,'tom2',30,'1344444444','2018-12-08 15:08:24'),(19,'iiii',30,'1344444444','2018-12-08 21:21:47'); /*!40101 SET SQL_MODE=@OLD_SQL_MODE */; /*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */; /*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */; /*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
在运行下面的演示案例之前,先把表和数据准备好。
理解表锁和行锁
锁是用于管理不同事务对共享资源的并发访问。
表锁与行锁的区别:
- 锁定粒度:表锁 > 行锁
- 加锁效率:表锁 > 行锁
- 冲突概率:表锁 > 行锁
- 并发性能:表锁 < 行锁
InnoDB 存储引擎支持行锁和表锁(另类的行锁),InnoDB 的表锁是通过对所有行加行锁实现的。
锁的类型
- 共享锁(行锁):Shared Locks
- 排他锁(行锁):Exclusive Locks
- 意向锁共享锁(表锁):Intention Shared Locks
- 意向锁排它锁(表锁):Intention Exclusive Locks
- 自增锁:AUTO-INC Locks
行锁的算法
- 记录锁:Record Locks
- 间隙锁:Gap Locks
- 临键锁:Next-key Locks
官网文档:https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html
共享锁(Shared Locks)
定义
共享锁:又称为读锁,简称 S 锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
通过如下代码,加锁和释放锁:
-- 加锁 select * from users WHERE id=1 LOCK IN SHARE MODE; -- 释放锁:提交事务 or 回滚事务 commit; rollback;
演示案例
-- 共享锁 -- 事务A执行 BEGIN; SELECT * FROM users WHERE id=1 LOCK IN SHARE MODE; ROLLBACK; COMMIT; -- 事务B执行 SELECT * FROM users WHERE id=1; UPDATE users SET age=19 WHERE id=1;
- 事务A手动开启事务,执行语句获取共享锁,注意这里没有提交事务
- 事务B分别执行 SELECT 和 UPDATE 语句,查看执行效果
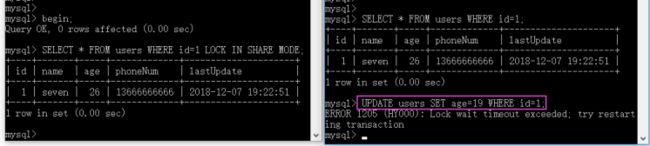
结论:UPDATE 语句被锁住了,不能执行。在事务A获得共享锁的情况下,事务B可以执行查询操作,但是不能执行更新操作。
排他锁(Exclusive Locks)
定义
排它锁:又称为写锁,简称 X 锁,排他锁不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的锁(共享锁、排他锁),只有该获取了排他锁的事务是可以对数据行进行读取和修改。(其他事务要读取数据可来自于快照)
通过如下代码,加锁和释放锁:
-- 加锁 -- delete / update / insert 默认加上X锁 -- SELECT * FROM table_name WHERE ... FOR UPDATE -- 释放锁:提交事务 or 回滚事务 commit; rollback;
演示案例
-- 排它锁 -- 事务A执行 BEGIN; UPDATE users SET age=23 WHERE id=1; COMMIT; ROLLBACK; -- 事务B执行 SELECT * FROM users WHERE id=1 LOCK IN SHARE MODE; SELECT * FROM users WHERE id=1 FOR UPDATE; -- SELECT 可以执行,数据来自于快照 SELECT * FROM users WHERE id=1;
- 事务A手动开启事务,执行 UPDATE 语句,获取排它锁,注意这里没有提交事务
- 事务B分别执行三条语句,查看执行效果
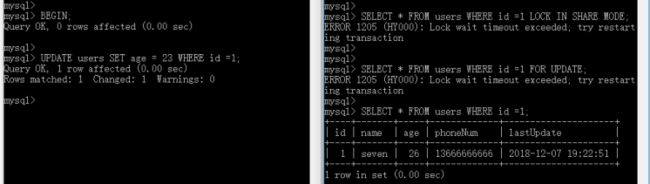
结论:事务B的第一条 SQL 和第二条 SQL 语句都不能执行,都已经被锁住了,第三条 SQL 可以执行,数据来自于快照,关于这点后面会讲到。
行锁到底锁了什么
InnoDB 的行锁是通过给索引上的索引项加锁来实现的。
只有通过索引条件进行数据检索,InnoDB 才使用行级锁,否则,InnoDB 将使用表锁(锁住索引的所有记录)
通过普通索引进行数据检索,比如通过下面例子中 UPDATE users SET lastUpdate=NOW() WHERE `name`='seven';该 SQL 会在 name 字段的唯一索引上面加一把行锁,同时会在该唯一索引对应的主键索引上面也会加上一把行锁,总共会加两把行锁。
演示案例
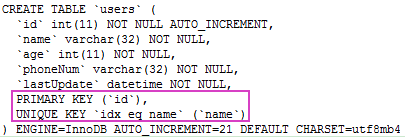
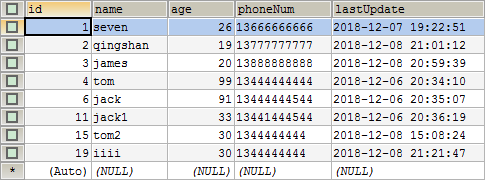
演示之前,先看一下 users 表的结构和数据内容。
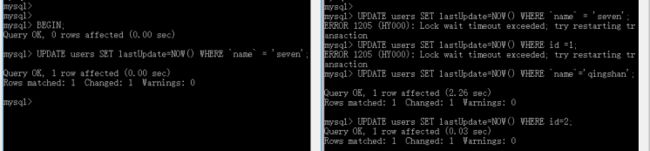
-- 案例1 -- 事务A执行 BEGIN; UPDATE users SET lastUpdate=NOW() WHERE phoneNum='13666666666'; ROLLBACK; -- 事务B执行 UPDATE users SET lastUpdate=NOW() WHERE id=2; UPDATE users SET lastUpdate=NOW() WHERE id=1; -- 案例2 -- 事务A执行 BEGIN; UPDATE users SET lastUpdate=NOW() WHERE id=1; ROLLBACK; -- 事务B执行 UPDATE users SET lastUpdate=NOW() WHERE id=2; UPDATE users SET lastUpdate=NOW() WHERE id=1; -- 案例3 -- 事务A执行 BEGIN; UPDATE users SET lastUpdate=NOW() WHERE `name`='seven'; ROLLBACK; -- 事务B执行 UPDATE users SET lastUpdate=NOW() WHERE `name`='seven'; UPDATE users SET lastUpdate=NOW() WHERE id=1; UPDATE users SET lastUpdate=NOW() WHERE `name`='qingshan'; UPDATE users SET lastUpdate=NOW() WHERE id=2;
注意:这里演示的案例都是在事务A没有提交之前,执行事务B的语句。
案例1执行结果如下图所示:

案例2执行结果如下图所示:

案例3执行结果如下图所示:
意向共享锁(Intention Shared Locks)& 意向排它锁(Intention Exclusive Locks)
意向共享锁(IS)
表示事务准备给数据行加入共享锁,即一个数据行加共享锁前必须先取得该表的 IS 锁,意向共享锁之间是可以相互兼容的。
意向排它锁(IX)
表示事务准备给数据行加入排他锁,即一个数据行加排他锁前必须先取得该表的 IX 锁,意向排它锁之间是可以相互兼容的
意向锁(IS 、IX)是 InnoDB 数据操作之前自动加的,不需要用户干预。
意义:当事务想去进行锁表时,可以先判断意向锁是否存在,存在时则可快速返回该表不能启用表锁。
演示案例
-- IS锁的意义 -- 事务A执行 BEGIN; UPDATE users SET lastUpdate=NOW() WHERE id=1; ROLLBACK; -- 事务B执行 -- 因为没有通过索引条件进行数据检索,所以这里加的是表锁 UPDATE users SET lastUpdate=NOW() WHERE phoneNum='13777777777';
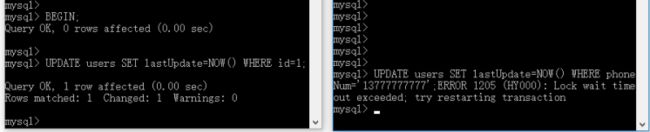
结论:事务B的 SQL 因为没有通过索引条件进行数据检索,所以这里加的是表锁,在对表加锁之前会查看该表是否已经存在了意向锁,因为事务A已经获得了该表的意向锁了,所以事务B不需要判断每一行数据是否已经加锁,可以快速通过意向锁阻塞当前 SQL 的更新操作。
自增锁(AUTO-INC Locks)
定义
针对自增列自增长的一个特殊的表级别锁。
通过如下命令查看自增锁的默认等级:
SHOW VARIABLES LIKE 'innodb_autoinc_lock_mode';
默认取值1,代表连续,事务未提交 ID 永久丢失。
演示案例
-- 事务A执行 BEGIN; INSERT INTO users(NAME , age ,phoneNum ,lastUpdate ) VALUES ('tom2',30,'1344444444',NOW()); ROLLBACK; BEGIN; INSERT INTO users(NAME , age ,phoneNum ,lastUpdate ) VALUES ('xxx',30,'13444444444',NOW()); ROLLBACK; -- 事务B执行 INSERT INTO users(NAME , age ,phoneNum ,lastUpdate ) VALUES ('yyy',30,'13444444444',NOW());
事务A执行完后,在执行事务B的语句,发现插入的 ID 数据不再连续,因为事务A获取的 ID 数据在 ROLLBACK 之后被丢弃了。
临键锁(Next-Key Locks)
定义
当 SQL 执行按照索引进行数据的检索时,查询条件为范围查找(between and、<、>等)并有数据命中,则此时 SQL 语句加上的锁为 Next-key locks,锁住索引的记录 + 区间(左开右闭)。
演示案例
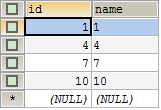
演示之前,先看一下 t2 表的结构和数据内容。
临键锁(Next-key Locks):InnoDB 默认的行锁算法。

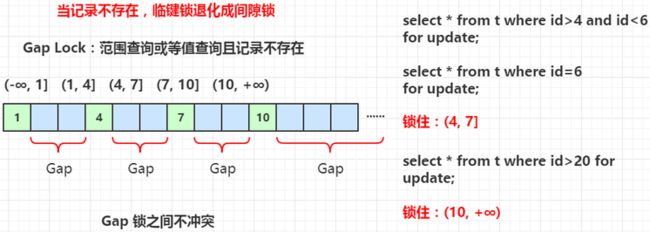
t2 表中的数据行有4条数据:1,4,7,10,InnoDB 引擎会将表中的数据划分为:(-∞, 1] (1, 4] (4, 7] (7, 10] (10, +∞),执行如下 SQL 语句:
-- 临键锁 -- 事务A执行 BEGIN; SELECT * FROM t2 WHERE id>5 AND id<9 FOR UPDATE; ROLLBACK -- 事务B执行 BEGIN; SELECT * FROM t2 WHERE id=4 FOR UPDATE; -- 可以执行 SELECT * FROM t2 WHERE id=7 FOR UPDATE; -- 锁住 SELECT * FROM t2 WHERE id=10 FOR UPDATE; -- 锁住 INSERT INTO `t2` (`id`, `name`) VALUES (9, '9'); -- 锁住
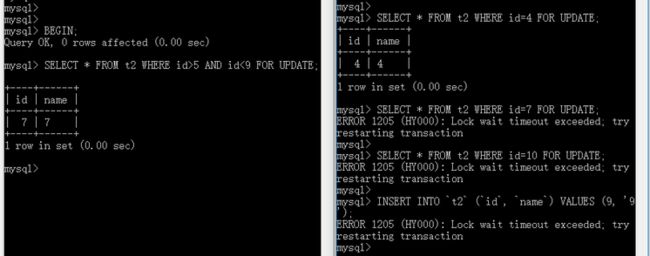
SELECT * FROM t2 WHERE id>5 AND id<9 FOR UPDATE; 这条查询语句命中了7这条数据,它会锁住 (4, 7] 这个区间,同时还会锁住下一个区间 (7, 10]。
为什么 InnoDB 选择临键锁作为行锁的默认算法?
防止幻读。当我们把下一个区间也锁住的时候,这个时候我们要新增数据,就会被锁住,这样就可以防止幻读。
间隙锁(Gap Locks)
定义
当 SQL 执行按照索引进行数据的检索时,查询条件的数据不存在,这时 SQL 语句加上的锁即为 Gap locks,锁住数据不存在的区间(左开右开)
Gap 只在 RR 事务隔离级别存在。因为幻读问题是在 RR 事务通过临键锁和 MVCC 解决的,而临键锁=间隙锁+记录锁,所以间隙锁只在 RR 事务隔离级别存在。
演示案例
-- 间隙锁 -- 事务A执行 BEGIN; SELECT * FROM t2 WHERE id>4 AND id <6 FOR UPDATE; -- 或者 SELECT * FROM t2 WHERE id=6 FOR UPDATE; ROLLBACK; -- 事务B执行 INSERT INTO `t2` (`id`, `name`) VALUES (5, '5'); INSERT INTO `t2` (`id`, `name`) VALUES (6, '6');
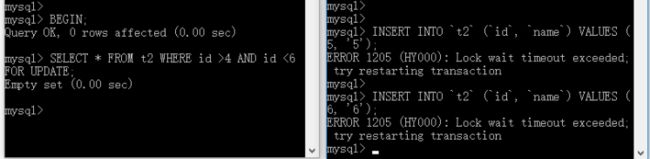
SELECT * FROM t2 WHERE id>4 AND id <6 FOR UPDATE; 这条查询语句不能命中数据,它会锁住 (4, 7] 这个区间。
记录锁(Record Locks)
定义
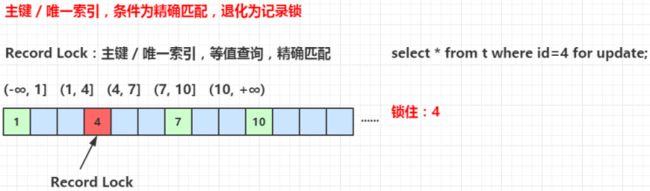
当 SQL 执行按照唯一性(Primary key、Unique key)索引进行数据的检索时,查询条件等值匹配且查询的数据是存在,这时 SQL 语句加上的锁即为记录锁 Record Locks,锁住具体的索引项。
演示案例
-- 记录锁 -- 事务A执行 BEGIN; SELECT * FROM t2 WHERE id=4 FOR UPDATE; ROLLBACK; -- 事务B执行 SELECT * FROM t2 WHERE id=7 FOR UPDATE; SELECT * FROM t2 WHERE id=4 FOR UPDATE;
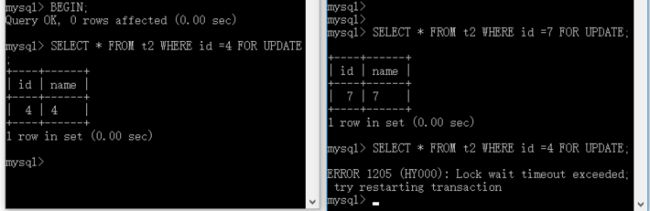
事务A执行 SELECT * FROM t2 WHERE id=4 FOR UPDATE; 把 id=4 的数据行锁住。
当 SQL 执行按照普通索引进行数据的检索时,查询条件等值匹配且查询的数据是存在,这时 SQL 语句锁住数据存在区间(左开右开)
利用锁解决事务并发带来的问题
InnoDB 真正处理事务并发带来的问题不仅仅是依赖锁,还有其他的机制,下篇文章会讲到,所以这里只是演示利用锁是如何解决事务并发带来的问题,并不是 InnoDB 真实的处理方式。
利用锁怎么解决脏读
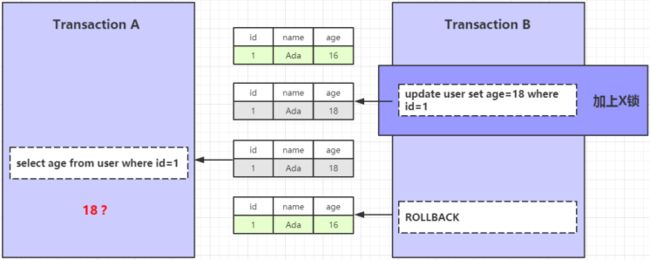
在事务B的更新语句上面加上一把 X 锁,这样就可以有效的解决脏读问题。
利用锁怎么解决不可重复读
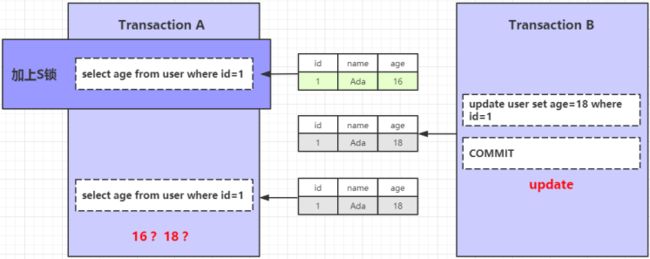
在事务A的查询语句上面加上一把 S 锁,事务B的更新操作将会被阻塞,这样就可以有效的解决不可重复读的问题。
利用锁怎么解决幻读
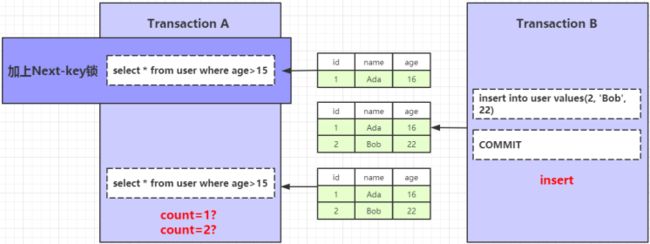
在事务A的查询语句上面加上一把 Next-key 锁,通过临键锁的定义,可以知道这个时候,事务A会把 (-∞,+∞) 的区间数据都锁住,事务B的新增操作将会被阻塞,这样就可以有效的解决幻读的问题。
死锁
死锁的介绍
- 多个并发事务(2个或者以上);
- 每个事务都持有锁(或者是已经在等待锁);
- 每个事务都需要再继续持有锁;
- 事务之间产生加锁的循环等待,形成死锁。
演示案例
-- 事务A执行 BEGIN; UPDATE users SET lastUpdate = NOW() WHERE id =1; UPDATE t2 SET `name`='test' WHERE id =1; ROLLBACK; -- 事务B执行 BEGIN; UPDATE t2 SET `name`='test' WHERE id =1; UPDATE users SET lastUpdate = NOW() WHERE id =1; ROLLBACK;
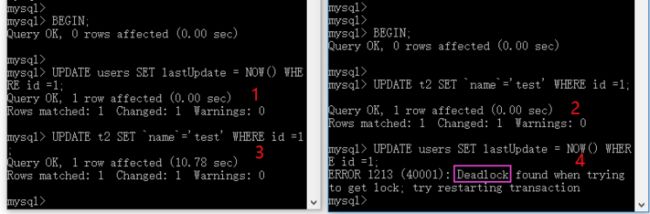
事务A和事务B按照上面的执行步骤,最后因为存在相互等待的情况,所以 MySQL 判断出现死锁了。
死锁的避免
- 类似的业务逻辑以固定的顺序访问表和行。
- 大事务拆小。大事务更倾向于死锁,如果业务允许,将大事务拆小。
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率。
- 降低隔离级别,如果业务允许,将隔离级别调低也是较好的选择
- 为表添加合理的索引。可以看到如果不走索引将会为表的每一行记录添加上锁(或者说是表锁)