上了数据挖掘的课,要写结课论文了。于是选择了Spark作为自己的课程主题,也是为自己之后的毕业论文打下知识基础,这里将自己的第一试验记录下来,以便之后的回顾。
1.环境配置
这是我的开发环境:
- Windows 10
- 阿里云(Centos 7.3)
- spark-2.2.0-bin-hadoop2.7(scala-compiler-2.11.8.jar)
- Scala 2.12.4(这个需要跟spark-2.2.0-bin-hadoop2.7中Scala的编译版本一样才会执行成功,之后会看到报错,所以这个改为Scala 2.11.8)
2.配置Spark的运行环境(Linux)
重点:Spark的版本一定要注意和Scala的版本相对应,不然出现的错误会千奇百怪的,请谨慎安装,具体的对应安装版本无法详细,在这里只能给出自己尝试过的安装版本
安装的环境的前提是要安装JDK(建议是1.8),因为Spark程序是运行在JVM上的,安装Spark只需要将压缩包解压即可。(这是我见过的最简单的安装啦啦啦)下面的是安装后的Spark目录:
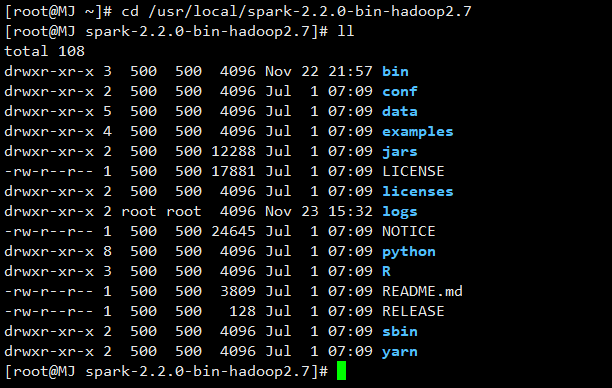
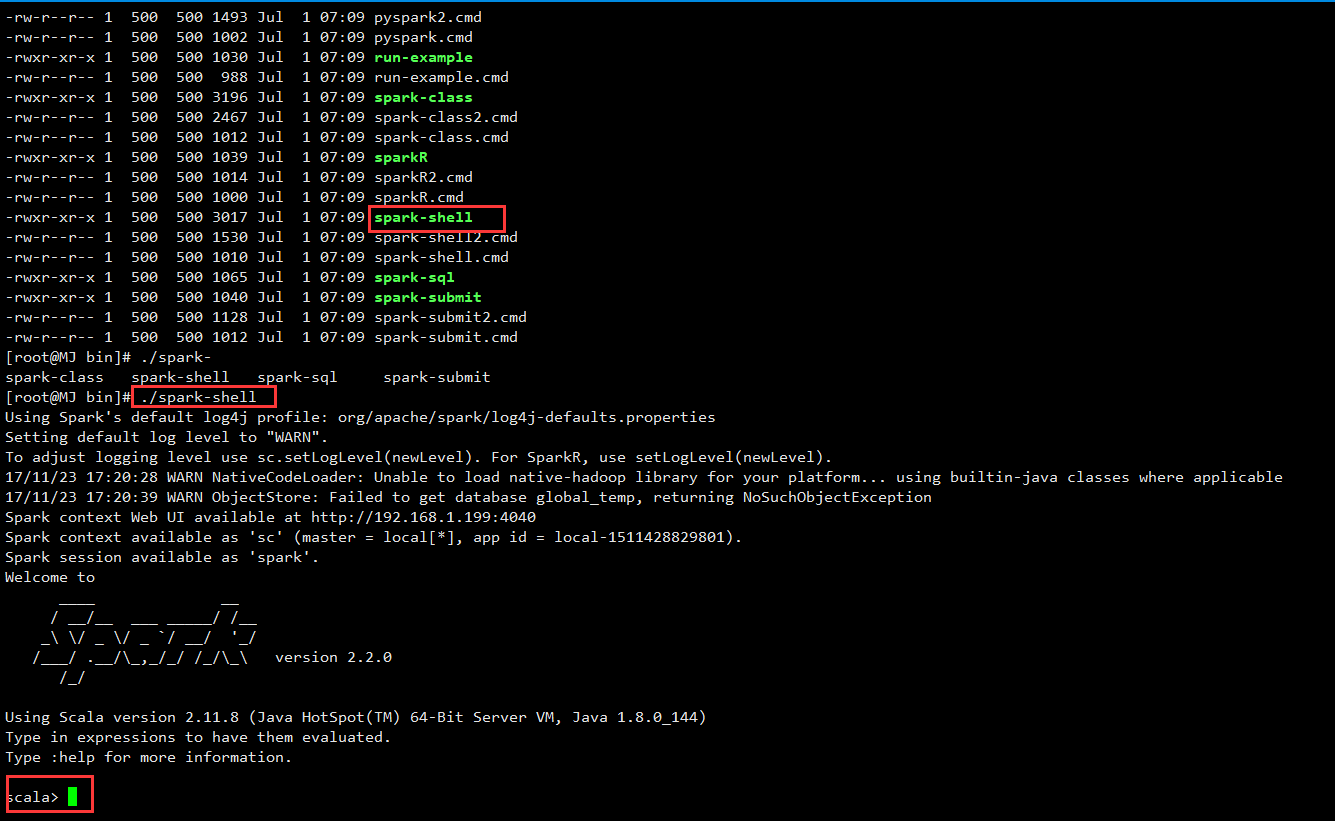
可以利用命令行写Spark项目,可以利用Python和Scala语言写(建议使用Scala),使用./spark-shell 进入编写的入口:
配置免密钥登录
第一步:使用下面的命令生成密钥
$ ssh-keygen -t rsa
如果之前的生成的密钥的话,在这里可以不用生成。
第二步:复制公钥文件
进入/root/.ssh/ 目录,如果没有authorized_keys 文件,可以先创建一个此文件。
$ cat id_rsa.pub >> authorized_keys
第三步:修改authorized_keys文件的权限
$ chmod 600 authorized_keys
第四步:验证ssh服务
$ ssh localhost
执行上述命令如果没有输入密码就可以登录就说明成功了!
3.Intellij IDEA上安装Scala插件和新建项目(Windows)
下面是网友项目的插件安装方法和新建简单的Scala项目,搬过来给大家看看,链接如下:
不会停的蜗牛
下面是我新建Scala项目的目录结构图:
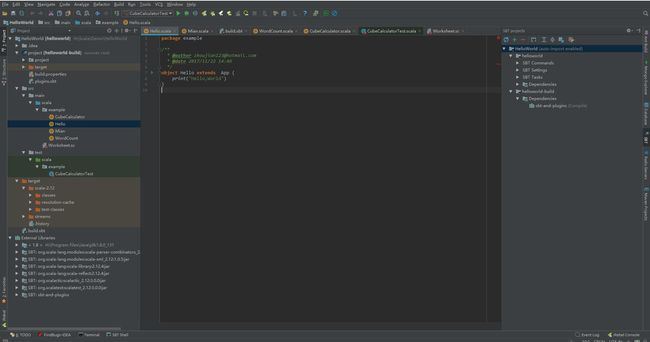
重点:在
build.sbt文件中添加libraryDependencies的版本问题,这也是依赖版本要对应的问题,后面会介绍利用Maven管理依赖,这样会方便多了。
4.编写第一个Spark程序
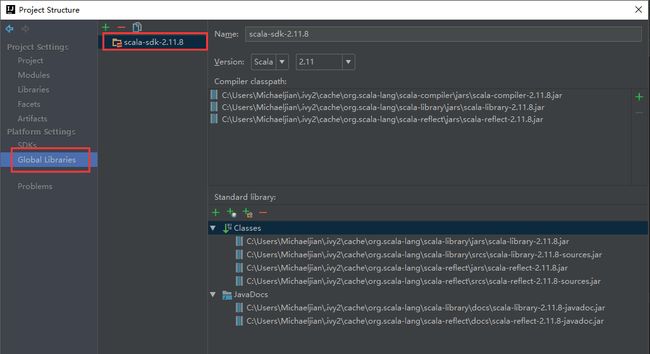
这是非常重要的一步:编写spark程序时需要提前将Scala的SDK添加到Global Libraries,如下图所示:
新建Scala的class类:
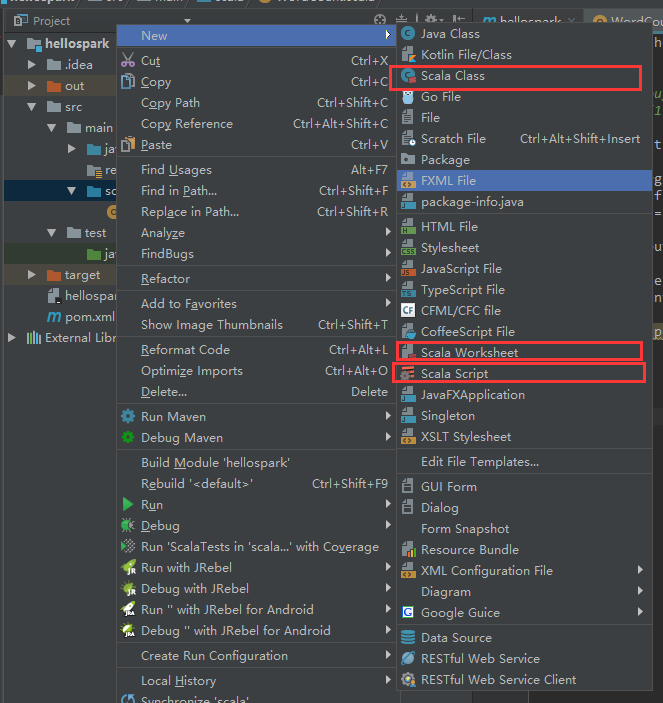
添加依赖(官方介绍):
可以像这样定义一个依赖,其中 groupId, artifactId 和 revision 都是字符串:
libraryDependencies += groupID % artifactID % revision
或者像这样, 用字符串或者 Configuration val 当做 configuration:
libraryDependencies += groupID % artifactID % revision % configuration
方法 % 从字符串创建 ModuleID 对象,然后将 ModuleID 添加到 libraryDependencies 中。
当然,要让 sbt(通过 Ivy)知道从哪里下载模块。如果你的模块和 sbt 来自相同的某个默认的仓库,这样就会工作。例如,Apache Derby 在标准的 Maven2 仓库中:
libraryDependencies += "org.apache.derby" % "derby" % "10.4.1.3"
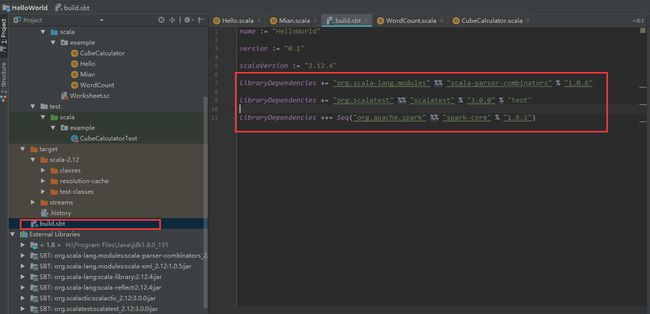
不推荐使用这用手动添加依赖的方式,推荐使用Maven管理依赖的方法,请往下面看。
5.将Spark程序打包(Jar包)
打包设置选项:
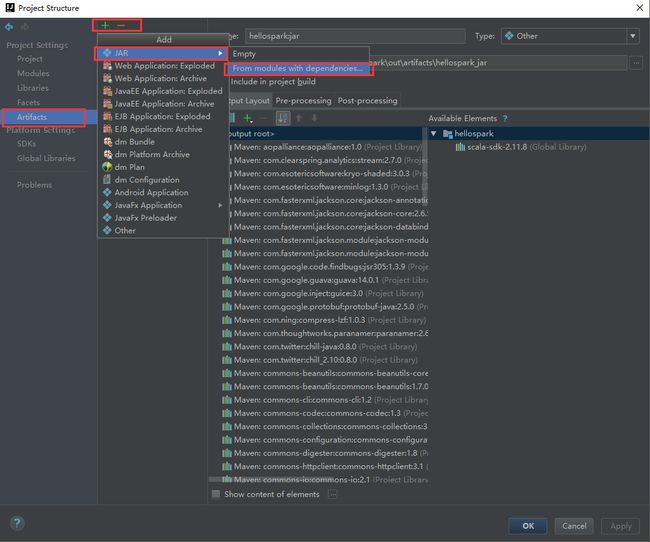
打包参数设置:1.选择主函数;2.选择只打包Scala程序
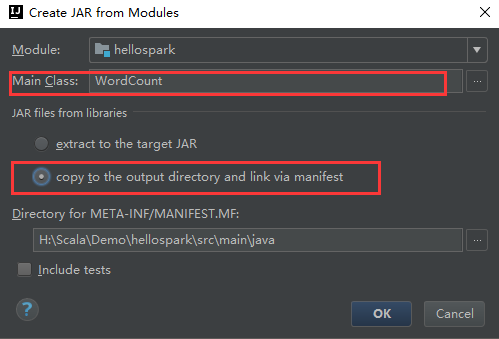
在Build 中选择Build Artifacts 后选择build即可打包成功
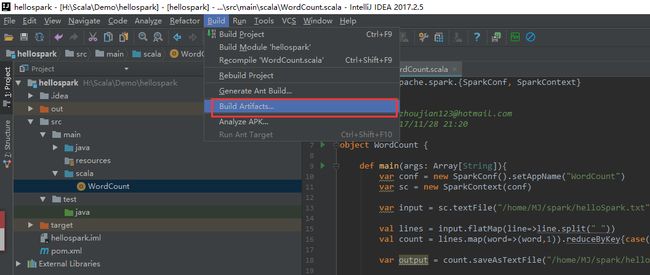
选择build ,然后等待打包结束
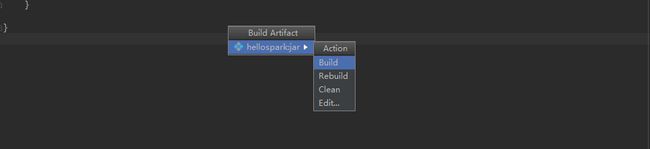
打包的jar包的位置:
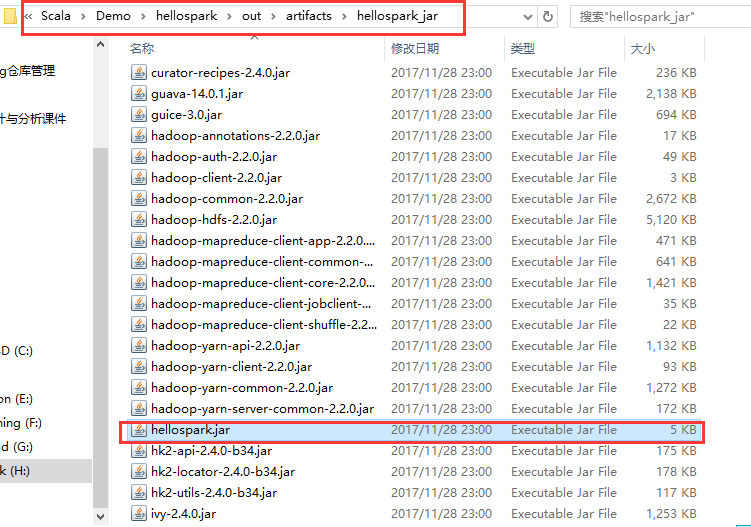
将jar包利用XFtp工具上传到Spark运行环境(对应程序运行地址):
6.将Jar包上传至Spark运行环境并启动和运行
启动Spark运行环境需要依次执行下面三个命令:
在执行了master进程和worker进程后,可以执行curl 127.0.0.1:8080 得到Spark Master at spark://MJ:7077 ,注意这个地址每个机器上都是不一样的,注意区分一下。
Spark Master at spark://MJ:7077
#启动master进程
./sbin/start-master.sh
#启动worker进程
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://MJ:7077
#提交作业 master后面的地址通过localhost:8080得到 class后面的是自己的项目的名称和对应jar包的地址
./bin/spark-submit --master spark://MJ:7077 --class WordCount /home/MJ/spark/hellospark.jar
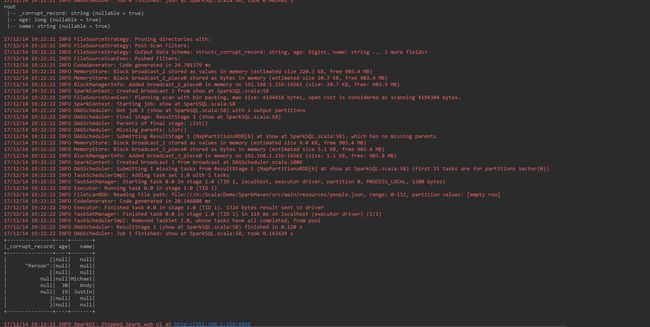
7.查看Spark运行的结果
提交作业之后,可以查看作业运行的结果:
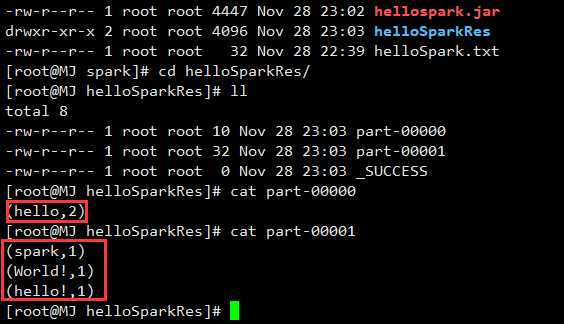
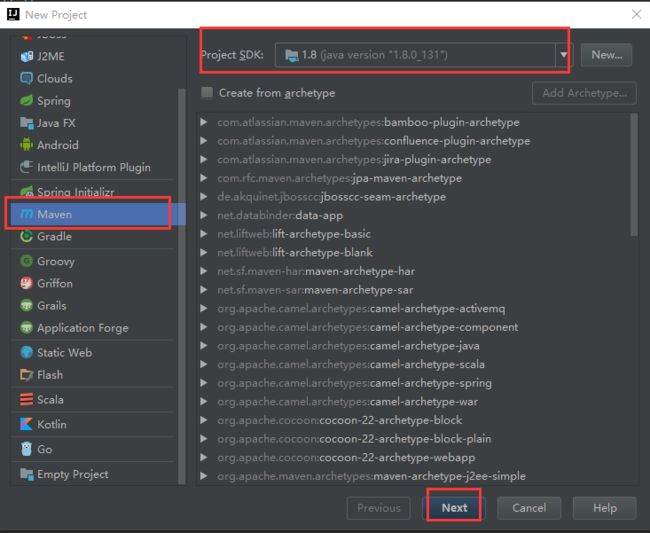
8.构建Maven管理Spark项目
首先是New Project 项目选择Maven,JDK选择最好是1.8+,然后点击next:
新建项目之后的目录结构是这样的:
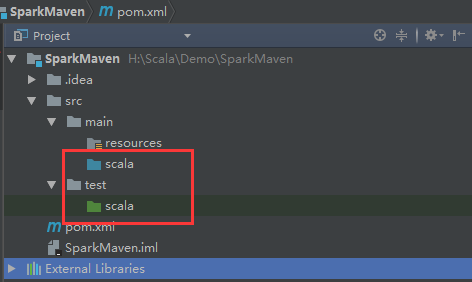
把其中的java和test文件夹都重新命名为scala文件夹,如下图
右键项目名出现Add Frameworks support ,并选择scala:
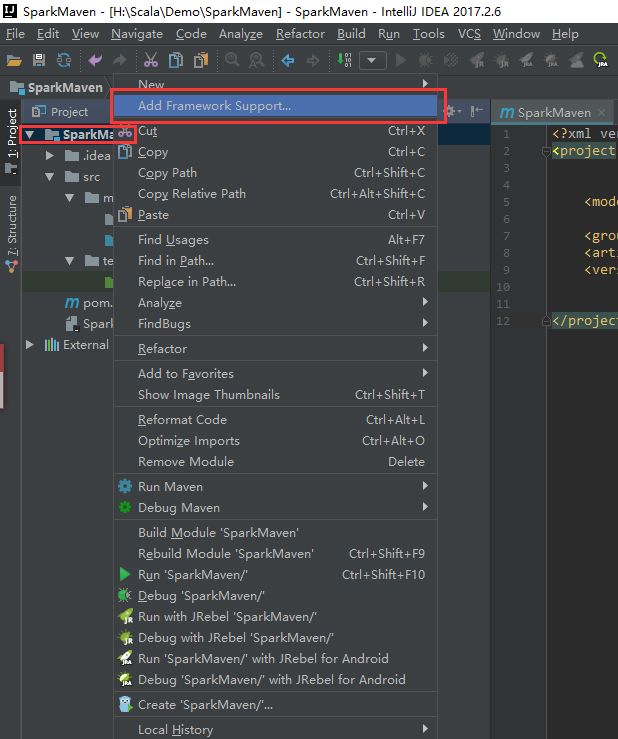
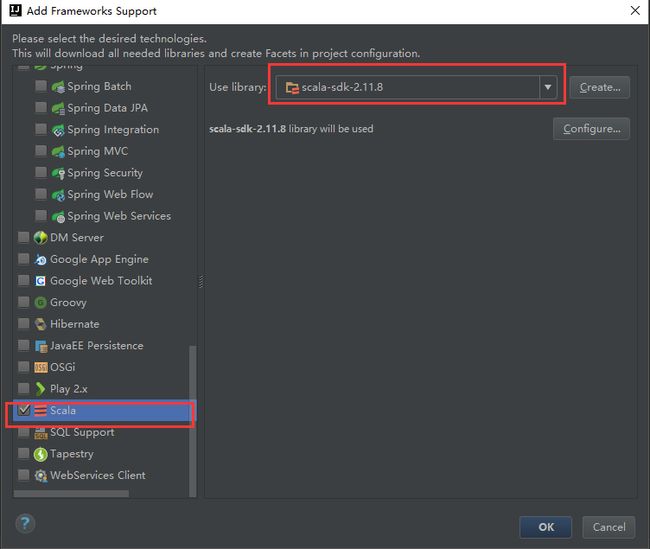
选择之后,然后新建一个Package 包文件夹,最后就是新建scala文件
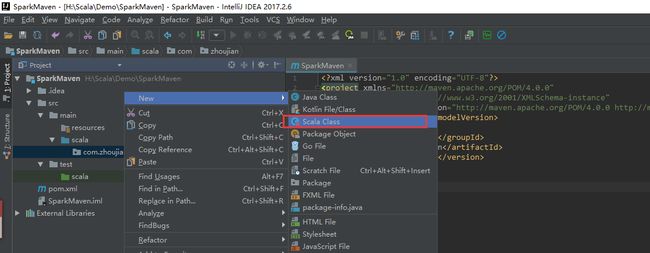
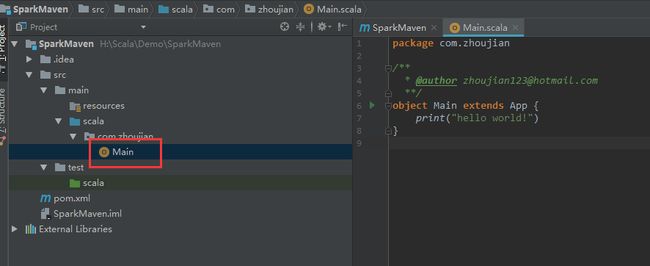
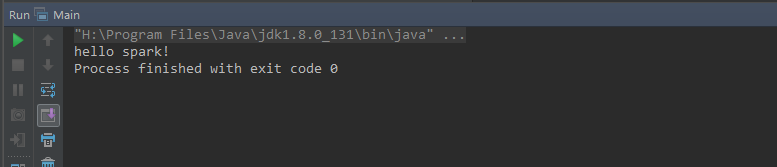
新建一个Main 文件,打印出hello spark! 字样
添加必要的关于Spark的pom 文件,点击添加Group: org.apache.spark
Spark Project Core
org.apache.spark
spark-core_2.11
2.2.1
Spark Project SQL
org.apache.spark
spark-sql_2.11
2.2.1
Spark Project Hive
org.apache.spark
spark-hive_2.11
2.2.1
9.可能出现的问题
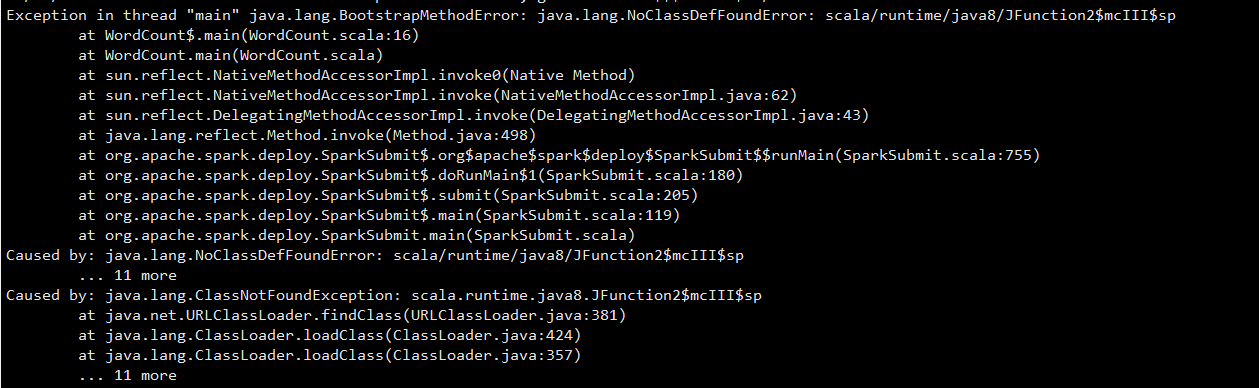
出现这种情况是由于在IDEA和Linux中安装的Scala版本不一样,把两者选择成一样的就会编译通过。
http://blog.csdn.net/u013054888/article/details/54600229
进入/usr/local/spark-2.2.0-bin-hadoop2.7/jars 找到Scala编译的版本号:
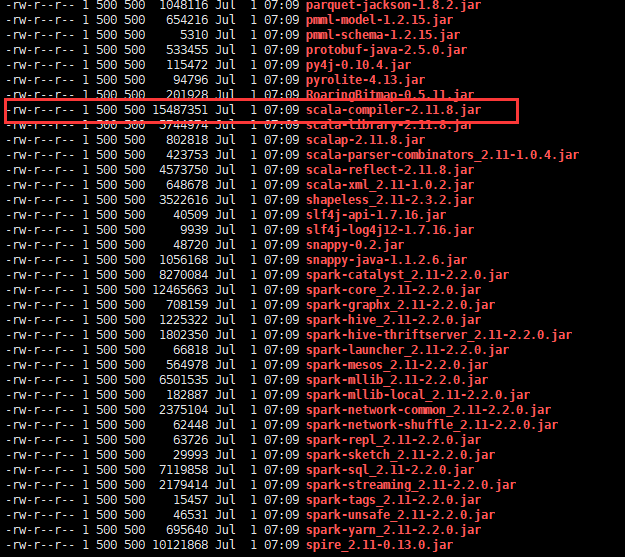
在IDEA中的Project Structure中选择对应的Scala版本:

出现下面错误:
exception in thread main org.apache.spark.sparkexception:A master URL must be set in your..
从提示中可以看出找不到程序运行的master,此时需要配置环境变量。
传递给spark的master url可以有如下几种:
local 本地单线程
local[K] 本地多线程(指定K个内核)
local[*] 本地多线程(指定所有可用内核)
spark://HOST:PORT 连接到指定的 Spark standalone cluster master,需要指定端口。
mesos://HOST:PORT 连接到指定的 Mesos 集群,需要指定端口。
yarn-client客户端模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
yarn-cluster集群模式 连接到 YARN 集群。需要配置 HADOOP_CONF_DIR。
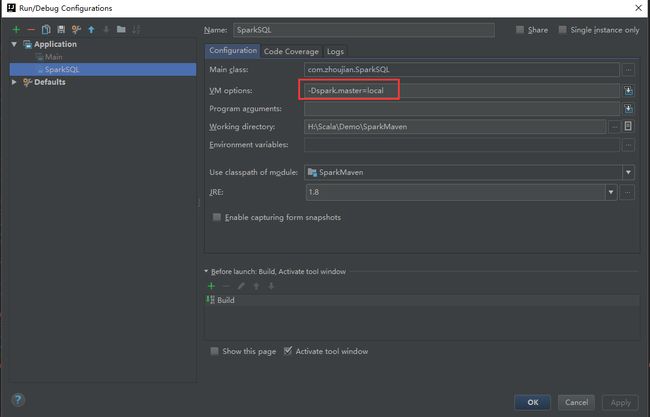
点击edit configuration,在左侧点击该项目。在右侧在右侧VM options中输入“-Dspark.master=local”,指示本程序本地单线程运行,再次运行即可。从提示中可以看出找不到程序运行的master,此时需要配置环境变量。
点击edit configuration,在左侧点击该项目。在右侧
在右侧VM options中输入“-Dspark.master=local”
,指示本程序本地单线程运行,再次运行即可。
运行成功的结果:
10.参考资料
http://docs.scala-lang.org/getting-started.html
http://www.jianshu.com/p/ecc6eb298b8f
http://www.jianshu.com/p/7c0d22847548
http://blog.csdn.net/u012373815/article/details/53266301
http://www.scala-sbt.org/1.x/docs/zh-cn/Library-Dependencies.html