接着上一期继续,间隔时间稍微有点久了~
模型评估
从回归模型返回的结果,我们能够得到统计性数据(这里用到了statsmodels库中回归模型的summary方法)。

这些统计指标中:
OLS:模型参数求值采用的是最小二乘法
R-squared/Adj. R-squared:体现回归模型对观测集的拟合程度
F-statistic/Prob (F-statistic):体现模型总体显著性水平(值越大模型越好),衡量模型是否能显著预测因变量的变化。
模型假设
上面的这些统计指标是否真正有效,取决于线性回归模型的前提假设是否能够成立,什么是前提假设呢?它们包括:
1、独立变量不是随机的
关于这个假设,我查阅了一些资料,一起提供给大家便于参考和理解。
参考资料:经典回归分析中假定解释变量(自变量)为确定变量,目的是为了统计检验时能方便地得出一些参数的分布。比如,在得到被解释变量的分布时(Y = a+ bX + u),因为 a+bX 是确定变量,则Y与u有相同的分布。另外也可以这样理解,样本i的解释变量Xi是随机的,但是当你从观测集中抽取出这个样本以后,可以将其视为固定的。
2、观测集误差项的方差是恒定的
这对于评价模型预测准确性的优劣是很重要的。
参考资料:在经典计量模型中,这是一个假设。它的逻辑基础是:如果样本来自于相同的个体,那么它的变异也相似。然而很多时候,这样的假设条件并不满足,比如在使用不同国家数据的时候。
3、误差项不是自相关的
可以通过德宾-沃森检验自相关性。如果检验结果越接近2,那就越表示误差的自相关越弱。
参考资料:经典回归模型误差项假设:第i个误差 ϵi和第j个误差 ϵj是不相关的。误差项的相关性暗示这样的可能:当前构建的模型还没有将观测集中所包含的全部信息表达出来。比如相邻地块的农业数据趋向于有相关的误差,因为它们受共同的外部环境的影响,即回归方程右边有一个“外部环境”变量被忽略,当加入这个变量后,自相关现象消除。自相关对数据分析的影响:回归系数的最小二乘估计是无偏的,但不再具有最小方差(多个解);置信区间和各种显著性检验的结论,严格来说,不再可信。
说明:德宾-沃森(Durbin-Watson)统计检验通过确定两个相邻误差项的相关性是否为零来检验误差项是否存在自相关,是目前检验一阶自相关性最常用的方法。在线性回归中,我们总是假设误差项是彼此不相关的。如果违反相互独立假设 ,一些模型的拟合结果就会成问题。例如,误差项之间的正相关往往会放大解释变量的系数值,从而使解释变量显得更重要 ,而事实上它们可能并不足道。
4、误差项需要呈现正态分布。
否则我们不能使用一些统计方法,例如F检测。
参考资料:在自然条件下,理想化的误差是真正的“随机”,一定是正态分布的。生活中的例子如打靶,目标是靶心,然而你打靶总有误差。这个误差无法消除,你可以提高打靶水平,但只能缩小离靶心的偏离距离(方差),却无法消除总有偏差这一事实,这个偏差呈现正态分布,是一个客观现象。一旦脱离了正态分布,往往暗示着存在潜在的解释变量对于误差有所影响。
这个性质主要是针对线性回归和OLS(普通最小二乘法)估计量而言的,再举个例子:Y = βX + ϵ,其中系数β是真值(确定量而非随机变量,不存在分布之类的概率统计意义上的问题)。根据高斯马尔可夫经典假设,解释变量X也是确定量,从而误差项β服从正态分布,将推导出应变量Y也服从正态分布。
回归分析是建立在两个(或多个)变量存在因果关系的基础之上。如果这些变量之间相互影响,并且无法确定孰因孰果,那么只能做相关分析,而不能做回归分析。也即如果你做的是回归分析,那么就默认了这些变量之间是存在因果关系,其中一些变量(解释变量)是引起另一些变量(被解释变量)的原因,被解释变量是由解释变量变化引起的结果。
在这个逻辑基础上,一般我们把解释变量“默认”为确定量,但是由于各种各样的随机因素的影响,被解释变量的值不可能完全等于解释变量的值代入模型中计算得到的结果(解释变量为确定量,那么被解释变量就成了不确定量,也就是随机变量,因为有一些随机因素在干扰,使得它不等于我们的模型计算出来的由确定的解释变量和确定的模型形式得到的确定量)。
多元线性回归还需要一个额外的假设:
5、解释变量之间不存在显著的线性关系
如不满足,将无法保证求得的系数参数βi是唯一解(可以有很多种不同的系数参数组合,来表达同样的线性关系)。
换句话说,也即一组解释变量之间若存在线性关系(通过协方差计算体现)、互相依赖,那么对于给定的Xi,我们求出的系数参数 βi 会不准确。我们来看一个极端的例子,假设变量Xi 与 Xj 严格线性相关(假设 Xi = Xj ),这时线性回归可以是以下任意一种组合:Y = Xi + 0Xj = 0.5Xi + 0.5Xj = 0Xi + Xj ,而不会影响预测结果。
类似上面讲到的,有时我们的模型系数可能是模棱两可的,基于不同系数参数组合的模型都能很好地拟合观测集。解决含有“变量依赖”问题的一种有效方法,是剔除那些存在相关性的变量。这有助于降低模型过拟合的可能性,使这些βi系数估计值更接近于它们的真实值。
如果上述关于回归模型的五点假设都能一一满足,我们便能放心地使用统计指标来评估模型。例如,R方告诉我们基于回归模型预测的Y值总体变异分数。当进行多元线性回归时,我们更偏爱使用调整后的R方值(修正了在回归模型中增加解释变量而引起的R方值增大,即使他们与因变量没有显著的相关性)。调整后的R方计算公式如下:

公式中n是观测集中样本的个数,k是回归模型中独立变量的个数。其他有用的统计指标包括F-检验和估计标准差。
模型选择
构建回归模型时,如果解释变量(自变量)太多,模型可能过拟合,太少又会欠拟合。一个有效的方法是采用逐步回归。逐步回归是指,先建一个“空模型”模,对每个独立的自变量进行检验,从中选择使得模型最优的一个(通常用赤池系数AIC或贝叶斯系数BIC取最小值)。
然后每次从剩下的自变量中选出一个增加到模型中,使用回归检验自变量组合,通过AIC与BIC找到最优的一个选择,依此类推最终得到最优的模型。这种方法也有其局限性,如果特定的自变量在算法执行的前段就被剔除出算法,该方法可能会找不到理论上的最优模型,所以在现实使用中,逐步回归法还是需要结合人为的判断。
说了那么多,相信大家已经看累了,其实我也说得累了,那就让我们结合实例说明一下吧~
模型示例(自变量存在线性关系的处理)
我们先构建一个线性模型:
随后我们在各自变量之间设定一些关系,特别对于自变量X4,将其设置为与X1严格线性关系( = 5X1),具体如下:

对其进行可视化:

使用statsmodels进行多元线性回归,求出自变量的系数参数:
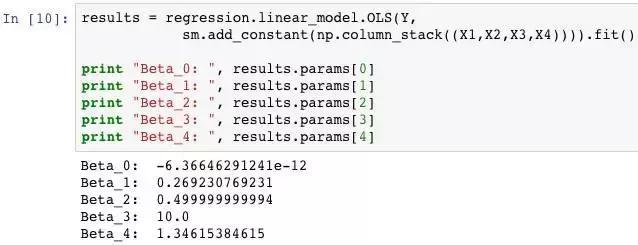
结果β2与β3系数参数估计值还是很准确的,但β1和β4系数参数则存在较大误差,说明了自变量间的严格线性关系会导致回归系数存在多重解(逐步回归法并不能处理该问题)这时可考虑剔除X4。原理前文提到了,如果X1与X4存在严格线性关系(如X1=X2),那么线性方程就可以转化出无数的可能性 ( Y = X1 + X2 = 0.5X1 + 1.5X2 = 1.5X1 + 0.5X2 ) ,只需要保留其中一个解释变量,同时调整对应的参数系数即可。