前言
最近也是在工作之余开发一个Android App,采用当前比较火的框架retrofit+rxjava+rxbus+lamda+greenDao+glide等。有兴趣的小伙伴可以关注一下我的github开源项目。本文主要介绍的是如何利用python抓取糗百的热门段子。
开发环境
- Mac Os
- Python 2.7.10
- Node 7.8.0
编译器:
- python-->Pycharm Ec
- node-->Visual Code Studio
以上开发环境以及编译器大家可以自行百度 or google安装,本文就不一一介绍了。
爬虫开发过程
准备
除了以上所说的编译器以及开发环境的配置外,我们还要明确设计爬虫的目标,找到抓取的url以及分析目标url的dom结构。
- 目标:抓取糗百热门段子第一页中的,所有作者,作者的头像,以及对应的段子内容
- url:http://www.qiushibaike.com/
- dom结构:
可以进入糗百首页,然后查看一下网页源码
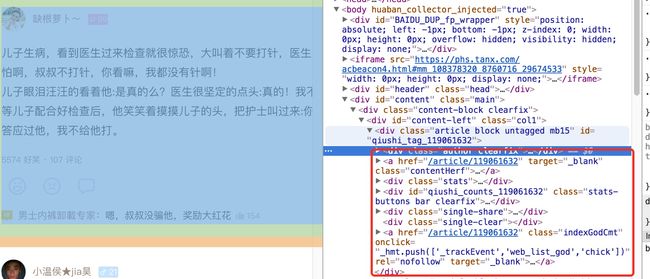
{690D4AFF-447F-E481-B455-CDF6DAF63F7C}.png
如上图中所示,可以看到每个完整的段子都是在class=article block untagged mb15的div下面。西面接着找一下对应作者的头像以及姓名的节点可以看到作者的名字是和img的alt一样的因此只需要找到这个节点就可以得到姓名和头像地址了。最后看下段子的内容,在class= content的div下面的span中。至此所有要的信息的节点都找到了。
爬虫书写过程
框架分为五个个部分:爬虫入口,url管理器,html下载器,html解析器,html输出器
爬虫入口
新建spider_main.py
from baike import url_manager, html_download, html_parser, html_output
class SpiderMain(object):
def __init__(self):
self.urls = url_manager.UrlManager()
self.download = html_download.HtmlDown()
self.parser = html_parser.HtmlParser()
self.out = html_output.HtmlOutput()
def crow(self, root_url):
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d:%s' % (count, new_url)
html_count = self.download.download(new_url)
data = self.parser.parser(html_count)
self.out.collect_data(data)
if count == 1000:
break
count = count+1
except:
print 'craw failed:'
self.out.output_html()
if __name__ == '__main__':
root_url = 'http://www.qiushibaike.com/'
obj_spider = SpiderMain()
obj_spider.crow(root_url)
url管理器
class UrlManager(object):
def __init__(self):
self.new_urls = set()
self.older_urls = set()
def add_new_url(self, url):
if url is None:
return
if url not in self.new_urls and url not in self.older_urls:
self.new_urls.add(url)
def add_new_urls(self, urls):
if urls is None or len(urls) == 0:
return
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
url = self.new_urls.pop()
self.older_urls.add(url)
return url
html下载器
import requests
class HtmlDown(object):
def download(self, url):
if url is None:
return None
response = requests.get(url)
if response.status_code != 200:
return None
return response.text
html解析器
from bs4 import BeautifulSoup
class HtmlParser(object):
def __init__(self):
self.items = []
def parser(self, response):
if response is None:
return None
soup = BeautifulSoup(response, 'html.parser')
nodes = soup.findAll('div', class_='article block untagged mb15')
if nodes is None or len(nodes) == 0:
return None
for node in nodes:
image_node = node.img
image = 'http:' + image_node['src']
user_name = image_node['alt']
content_node = node.span.get_text()
data = {
'image_url': image,
'user_name': user_name,
'content': content_node
}
self.items.append(data)
return self.items
html输出器
import json
class HtmlOutput(object):
def __init__(self):
self.data = []
def collect_data(self, data):
if data is None:
return
self.data = data
def output_html(self):
self.write_to_json(self.data)
fout = open('output.html', 'w')
fout.write("")
fout.write("")
fout.write("")
fout.write("")
fout.write("name ")
fout.write("image ")
fout.write("content ")
fout.write(" ")
if len(self.data) > 0:
for item in self.data:
fout.write("")
fout.write("%s " % (item['user_name']).encode('utf-8'))
fout.write("%s " % (item['image_url']))
fout.write("%s " % (item['content']).encode('utf-8'))
fout.write(" ")
fout.write("
")
fout.write("")
fout.write("")
fout.close()
def write_to_json(self, data):
if data is None:
return
f = open('json.txt', 'w')
json_str = json.dumps(data).encode('utf-8')
print json_str
f.write(json_str)
f.close()
最终将爬去的数据以html的形式和Json形式分表保存在当前路径下面。
只用node书写简单的接口
代码如下:
ar http = require('http');
var rf = require("fs");
var data = rf.readFileSync("/Users/bear/Desktop/workplace/python/baike/json.txt", "utf-8");
console.log(data)
var jsonStr = {
'code': '1',
'message': '操作成功',
"data": {
'items': JSON.parse(data)
}
};
var json = JSON.stringify(jsonStr);
console.log(json);
http.createServer(function (req, res) {
res.writeHead(200);
res.end(json);
}).listen(1377, "0.0.0.0");
console.log('Server running at http://127.0.0.1:/');
然后本地浏览器打开:localhost:1377就能看到最终的json了
其它
app 端接口的调用可以看下Github上的开源项目