导语:
记得刚刚学习Java I/O的时候,被输入输出流的层次结构吓得不轻,一整个流家族里面,包含了各种流类型,其数量超过了60个!这与C中只有单一类型FILE*天差地别,也因为没有理清楚其中的关系,所以对IO流的理解比较混乱,刚好趁此机会好好理一下其中的思路。
一、流概念及I/O流层次结构。
流是一个抽象的概念,代表任何有能力产出数据的数据源或者是有能力接受数据的接收端对象。“流”屏蔽了实际的I/O设备中处理数据的细节。 -java编程思想
之前看到流的时候,第一个想到的就是管道流,以为流就是管道流。后来发现管道流只是流具体抽象的一种实现而已,除了管道流,还有缓冲流,回退流等。在Java中的标准输入输出中,就是以流的方式完成I/O的。所有的I/O(NIO除外,后续有做介绍)都被视为字节的移动,通过Stream对象一次移动一个或者两个字节(具体是一个还是两个得看是字节流还是字符流)。
以下是比较常见的流的层次结构,当初就是被这么一大堆类弄得不知所措,而且还各种相互包装。
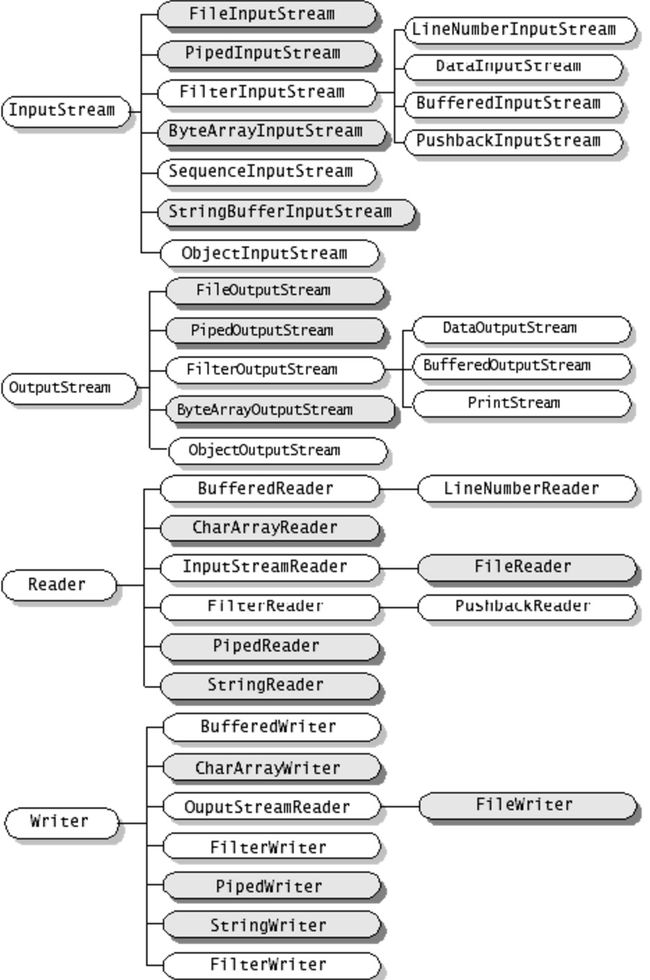
其实Java I/O 流就是一个使用装饰器模式的典型例子,我们可以根据自己的需要来包装组合Java I/O类库中的类,以达到完成不同功能的目的。但是同时也增加了代码的复杂性,有时候我们可能需要创建许多个类才最终得到我们希望的某个最终的I/O对象,不仅使得代码可读性降低,内存中也需要维护多个对象。不过也正是这么多原理各异,功能不同的类,减轻了开发者的实际开发量,统一了规范,使得开发者几乎不需要再编写相关底层代码就能完成任务,相信这个也是I/O类库如此丰富的原因所在。
二、常用流使用介绍及分类
1.流的分类及其原理
看了许多博客,大多数人都是把流分为字节流和字符流,还有输入流和输出流,其实这两个都比较好理解。其实字节流和字符流的原理是相同的,只不过传输的单位不同而已,前者是一次一个字节,后者是两个字节组成Unicode格式的字符,并且根据相关的字符集进行编码和解码。在这里,按照其功能,分为节点流和处理流。
节点流
节点流从一个特定的数据源读写数据。即节点流是直接操作文件、网络等的流,例如FileInputStream和FileOutputStream,他们直接从文件中读取或往文件中写入字节流。

处理流
处理流,就是已经存在的节点流或者处理流上,在包装一层或几层具有特定功能的类,从而使得程序能对数据的处理效率更好,或者具备更加强大的功能。例如BufferedInputStream和BufferedOutputStream,使用已经存在的节点流来构造,提供带缓冲的读写,提高了读写的效率,再比如DataInputStream和DataOutputStream,提供了读写Java中的基本数据类型的功能。他们都属于处理流。这里面有几个较为典型的例子:
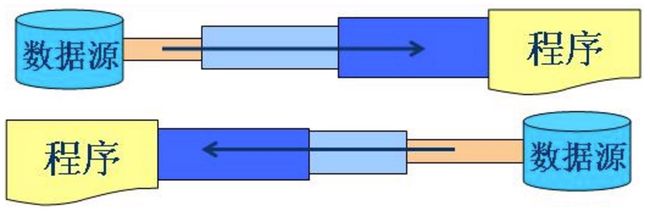
具有缓冲的处理流
在原来的节点流上包装一层BufferedInputStream,就可以将一些有未来有可能会读取到的数据读入缓存中,当下次读取时,就可以直接从换从中获取,减少I/O。写入也是一样,将数据写入缓存中,当缓存中的数据满了或者手动直接或间接调用flush,才把缓存的内容写到文件中。最开始接触Java I/O的时候,老是搞不懂为什么有些写入需要flush,有些却不需要。其实很简单,只要判断处理流中是否含有缓存的相关类就可以确定是否需要调用flush。
具有可读写转换成Java基本类型的处理流
在Java I/O中,提供了DataInputStream和DataOutputStream,使用已经存在的节点流来构造,提供了读写Java中的基本数据类型的功能。他们都属于过滤流,后面有例子详细介绍。其实继承自FilterInputStream和FilterOutputStream的都是属于过滤流,他们或者完成数据类型的转换,或许提供行号添加,或许可以支持在读取完最近的字节后还能将其回退至缓存中的“过滤”功能。虽然Java I/O结构繁多,但是理清以后,可以体会到其中的相关字面意思和思想。
2.常见流使用
虽然I/O类库中的类(接口)非常的多,组合也非常的灵活,但是典型的使用方式无非就如下这几种(以下代码均直接抛出异常,仅关注流的使用,小节最后会专门讲流的关闭及异常捕获):
输入输出对象为文件:
String inputfilename = "/xxx/xxx/input.txt";
String outputfilename = "/xxx/xxx/output.txt";
String s;
BufferedReader in = new BufferedReader(new FileReader(inputfilename));
PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter(outputfilename)));
StringBuilder sb = new StringBuilder();
while ((s = in.readLine()) != null){
out.println(s);
sb.append(s);
}
in.close();
out.close();
这里只展示了在字符上对文件进行文件写入写出,在字节上更加简单,就不再给出实例代码。
多线程的管道输入输出:
class Sender implements Runnable {
private Random rand = new Random(47);
private PipedWriter out = new PipedWriter();
public PipedWriter getPipedWriter() { return out; }
public void run() {
try {
for(char c = 'A'; c <= 'z'; c++) {
out.write(c);
TimeUnit.MILLISECONDS.sleep(rand.nextInt(500));
}
} catch(IOException e) {
System.out.print(e + " Sender write exception");
} catch(InterruptedException e) {
System.out.print(e + " Sender sleep interrupted");
}
}
}
class Receiver implements Runnable {
private PipedReader in;
public Receiver(Sender sender) throws IOException {
in = new PipedReader(sender.getPipedWriter());
}
public void run() {
try {
while(true) {
// Blocks until characters are there:
System.out.print("Read: " + (char)in.read() + ", ");
}
} catch(IOException e) {
System.out.print(e + " Receiver read exception");
}
}
}
public class PipedIO {
public static void main(String[] args) throws Exception {
Sender sender = new Sender();
Receiver receiver = new Receiver(sender);
ExecutorService exec = Executors.newCachedThreadPool();
exec.execute(sender);
exec.execute(receiver);
TimeUnit.SECONDS.sleep(4);
exec.shutdownNow();
}
}
这个类似于一个生产者-消费者的模型,管道实质上是一个阻塞的队列。当receiver在管道中没有数据可获取的时候,将自动进入阻塞,直至sender向管道写入数据。
格式化的内存输入输出:
DataOutputStream out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("Data.txt")));
out.writeInt(12344);
out.writeInt(56789);
out.writeDouble(3.123231);
out.writeUTF("哈哈");
out.writeDouble(3.23124);
out.writeUTF("world");
out.close();
DataInputStream in = new DataInputStream(new BufferedInputStream(new FileInputStream("Data.txt")));
System.out.println(in.readInt());
System.out.println(in.readInt());
System.out.println(in.readDouble());
System.out.println(in.readUTF());
System.out.println(in.readDouble());
System.out.println(in.readUTF());
System.out.println("end1");
in.close();
这种用法现在也比较少了,虽然可以按照特定的格式去写入和还原不同类型的数据。但是我们必须知道流中数据所在的确切位置和顺序,一旦数据类型和读入的类型不相符,就会抛出异常。因此要么固定文件特定的格式,要么将额外的信息保存到文件中。基于以上特性,对象序列化xml可能是更容易的存储和读取复杂数据结构的方式。
3.流的关闭
既然使用Java I/O打开了磁盘文件等物理资源,那在使用完以后,就应该显示地关闭这些资源。虽然运行环境较为复杂,有时候不可避免的会出现错误或者异常,如果需要程序能处理这些错误后仍然希望关闭这些资源,我们就需要在finally语句中关闭这些资源。但同时也要意识到,Java I/O 中的相关类接口提供的close方法也有可能会抛出异常,这意味着在finally语句中我们也需要捕获处理相关的异常,所以,考虑到了所有的异常处理的代码如下:
private static void exceptionEtc1(){
Wolf wolfOutput = new Wolf("wuqke","male");
Wolf wolfInput = null;
ObjectOutputStream objectOutputStream = null;
ObjectInputStream objectInputStream = null;
try {
//throw Exception
doSomethingWrong();
//initial outputStream and inputStream
objectOutputStream = new ObjectOutputStream(new FileOutputStream("sa.bin"));
objectInputStream = new ObjectInputStream(new FileInputStream("sa.bin"));
// serializa and output object
objectOutputStream.writeObject(wolfOutput);
objectOutputStream.flush();
wolfInput = (Wolf) objectInputStream.readObject();
}catch (IOException ex){
ex.printStackTrace();
}catch (ClassNotFoundException ex){
ex.printStackTrace();
} catch (Exception ex) {
ex.printStackTrace();
} finally {
try {
if (objectInputStream != null) {
objectInputStream.close();
}
if (objectOutputStream != null) {
objectOutputStream.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
虽然上述代码的逻辑比较简单,但是这么一写,就会发现代码非常的臃肿,这样的代码必然会使得程序的可读性降低。为了解决这个问题,Java 7新增了自动关闭资源的try语句:它允许在try关键字后紧跟一对圆括号,括号中可以声明,实例化一个或多个资源,try语句会在该语句结束时自动关闭这些资源。
需要说明的是,声明实例化的资源实现类,必须实现AutoCloseable或者Closeable接口
使用新特性的语句如下:
private static void exceptionEtc1(){
Wolf wolfOutput = new Wolf("wuqke","male");
Wolf wolfInput = null;
try (
//create outputStream and inputStream
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("a.bin"));
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("a.bin"));
)
{
//throw Exception
doSomethingWrong();
// serializa and output object
objectOutputStream.writeObject(wolfOutput);
objectOutputStream.flush();
wolfInput = (Wolf) objectInputStream.readObject();
} catch (Exception ex) {
ex.printStackTrace();
}
}
三、NIO
在传统的Java I/O编程中,使用的是流的方式以单个字节为单位来完成所有I/O。NIO 相较于原来的I/O,是通过块的方式去读取和写入数据的,它把最耗时的I/O操作(即从源填充数据到缓冲区或者从缓冲区提取数据到端)转移回操作系统。我们知道主流的文件操作系统存取数据的单位是块,而这个在操作系统级别上以块的为单位进行处理数据,无论是读取的速度还是存取的数据量,都比流的方式要更快更多,因此可以极大地提高速度。当然,这个是从底层数据操作来描述NIO和I/O的区别。
我们更加关注的是NIO在逻辑层面上的结构和其提供的相关功能。想要了解NIO的逻辑原理,就要从通道(FileChannel)和缓冲区(ByteBuffer)说起.
以下引用Java编程思想对其的形容:通道(FileChannel)是一个包含煤层(数据)的矿藏,而缓冲器(ByteBuffer)则是派送到煤藏的卡车。卡车载满煤炭而归,我们再从卡车上获得煤炭。也就是说,我们并没有直接和通道交互,我们只是和缓冲器交互,并把缓冲器送到通道。通道要么从缓冲器获得数据,要么向缓冲器发送数据。
以上大概就是通道和缓冲器的关系。在旧的I/O类库中有三个类被修改,用于产生FileChanel。这三个被修改的类是FileInputStream、FileOutputStream和RandomAccessFile。因为都是字节流,所以和底层的NIO性质一致。字符流相关类可通过java.nio.channel.Channels类提供的方法来产生。
下面给出一个简单的例子做一个逐行解释,相信就对NIO有了基本的了解。
public class ChannelCopy {
private static final int BSIZE = 1024;
public static void main(String[] args) throws Exception {
if(args.length != 2) {
System.out.println("arguments: sourcefile destfile");
System.exit(1);
}
//从字节流中获取到输入流和输入流各自的通道。
FileChannel
in = new FileInputStream(args[0]).getChannel(),
out = new FileOutputStream(args[1]).getChannel();
//创建一个缓冲区,指定该缓冲区的大小为1k
ByteBuffer buffer = ByteBuffer.allocate(BSIZE);
while(in.read(buffer) != -1) {
//修改相ByteBuffer的静态变量,变读为写
buffer.flip(); // Prepare for writing
out.write(buffer);
//重置ByteBuffer的静态变量,“清空”缓存
buffer.clear(); // Prepare for reading
}
}
}
上面的例子是一个读写结合的例子,可以看出两个通道之间其实只是通过一个buffer来进行通信的。那既然两个通道之间共享同一个数据块,那应该有个机制来保证两边通道可以正常协作,不会发现多读,少读,重读缓存区里面的数据。而上述实例buffer.flip()和buffer.clear()就是这个保证正常读写的机制。
要讲清楚中间的机制,就不得不说到缓冲器的细节。
其实缓冲区主要就是由一个final的byte数组和四个私有的变量组成:
缓冲器对象中有四个私有的变量:
final byte[] hb;
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
private int position = 0;
private int limit;
private int capacity;
byte数组用于存储数据。然后通过下面四个私有变量来确定byteBuffer中实际的有效数据及其范围
Position
position 变量跟踪已经写了多少数据。更准确地说,它指定了下一个字节将放到数组的哪一个元素中。因此,如果从通道中读三个字节到缓冲区中,那么缓冲区的 position 将会设置为3,指向数组中第四个元素。
同样,在写入通道时,是从缓冲区中获取数据。 position 值跟踪从缓冲区中获取了多少数据。更准确地说,它指定下一个字节来自数组的哪一个元素。因此如果从缓冲区写了5个字节到通道中,那么缓冲区的 position 将被设置为5,指向数组的第六个元素。
Limit
limit 变量表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
position 总是小于或者等于 limit。
Capacity
缓冲区的 capacity 表明可以储存在缓冲区中的最大数据容量。实际上,它指定了底层数组的大小 ― 或者至少是指定了准许我们使用的底层数组的容量。
mark
该变量用于想将position固定于标记,调用mark()标记某处位置后,使用reset()函数可以将position设置回标记处。
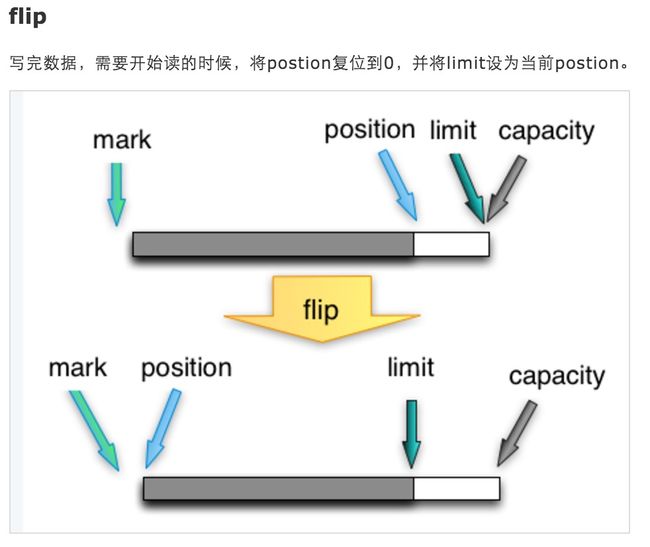
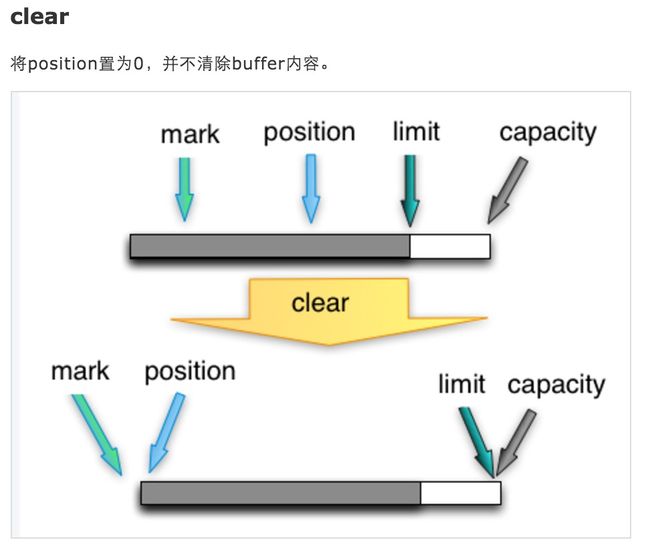
如上图及其描述所示。buffer.flip()其实就是通过调整几个私有变量,然后使得输出的管道能知道应该读取确切范围的有效数据到端中。当输出成功后,又调用,buffer.clear()操作重置相关变量,虽然没有清空Buffer内容,但是重置了相关变量,下次用该buffer写入数据的时候,到达对应的下标就直接覆盖,使用起来就像是清空的字节数组一般,从而也节省了删除数据的开销。
上述大概简单介绍了NIO,如果想详细了解NIO及其相关函数方法,建议阅读参考资料中的两篇blog。
四、I/O及NIO的区别
在 JDK 1.4 中原来的 I/O 包和 NIO 已经很好地集成了。java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如, java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在更面向流的系统中,处理速度也会更快,也能受益于NIO带来的速度的提高。所以大多数情况下并不需要非得用NIO包中的类和接口来编写代码。
但是,由于NIO的一些新的特性和功能,是旧I/O中所不具备的,在这场景下,结合NIO的使用就变得非常有必要(目前就想到这几个,如果还有其它情景,欢迎留言讨论添加):
1.大文件。如果一个文件有上百兆甚至上千兆,将其一次性读入内存会使内存非常紧张甚至不可能。这时候就需要使用内存映射文件,按需读入指定位置和映射长度的数据,这样我们就只需要讲某个大文件中的较小部分读入内存。
int length = 0x8ffffff;//128MB
MappedByteBuffer mapOut = new RandomAccessFile("/xxxx/xxxx/test.txt", "rw").getChannel().map(FileChannel.MapMode.READ_WRITE, 0, length);
for (int i = 0; i < length; i++) {
mapOut.put((byte) 'x');
}
System.out.print("Finished writing");
for (int i = length / 2; i < length / 2; i++) {
System.out.print((char) mapOut.get(i));
}
2.文件加锁。由于文件是分布在文件系统上的,也许对同一文件的访问可能出现在不同的JVM中,甚至是不同的进程。NIO中的文件锁,是在操作系统级别上对其它进程可见的。
FileOutputStream fos = new FileOutputStream("file.txt");
FileLock fl =fos.getChannel().tryLock();//非阻塞式获取
//FileLock fl =fos.getChannel().lock();//阻塞式获取
if(fl != null){
//doSomething.....
Thread.sleep(1000);
//done and realese lock
fl.release();
}
3.多线程环境。在老的IO包中,serverSocket和socket都是阻塞式的,因此一旦有大规模的并发行为,而每一个访问都会开启一个新线程。这时会有大规模的线程上下文切换操作(因为都在等待,所以资源全都被已有的线程吃掉了),这时无论是等待的线程还是正在处理的线程,响应率都会下降,并且会影响新的线程。
而NIO包中的serverSocket和socket就不是这样,只要注册到一个selector中,当有数据放入通道的时候,selector就会得知哪些channel就绪,这时就可以做响应的处理,这样服务端只有一个线程就可以处理大部分情况(当然有些持续性操作,比如上传下载一个大文件,用NIO的方式不会比IO好)。
参考资料
- Java编程思想 (第四版) 机械工业出版社
- Java 核心技术 卷二(原书第九版) 机械工业出版社
- 通过 Greg Travis 的 "NIO 入门"和该博客下相关的参考资料 入门和深入了解NIO
- 通过 黄亿华 的Java NIO学习笔记之二-图解ByteBuffer 的博客了解了ByteBuffer相关原理并在本文中使用相关插图