1.join 概述

Join 绝对是关系型数据库中最常用一个特性,然而在分布式环境中,跨分片的 join 确是最复杂的,最难解决一个问题。
下面我们简单介绍下各种 Join 操作。
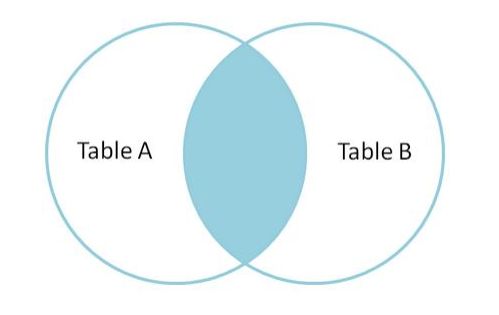
INNER JOIN
内连接,也叫等值连接,inner join 产生同时符合 A 表和 B 表的一组数据。
如图:
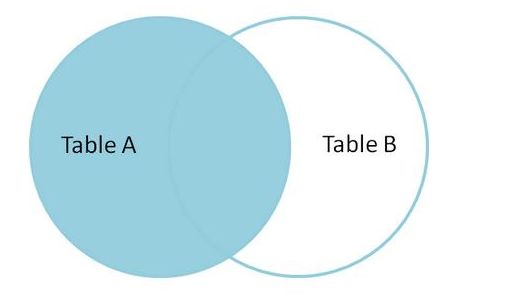
LEFT JOIN
左连接从 A 表(左)产生一套完整的记录,与匹配的 B 表记录(右表) .如果没有匹配,右侧将包含 null,在 Mysql 中等同于 left outer join。
如图:
RIGHT JOIN
同 Left join,AB 表互换即可。
CROSS JOIN
交叉连接,得到的结果是两个表的乘积,即笛卡尔积。笛卡尔(Descartes)乘积又叫直积。假设集合A={a,b},集合 B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以扩展到多个集合的情况。类似的例子有,如果 A 表示某学校学生的集合,B 表示该学校所有课程的集合,则 A 与 B 的笛卡尔积表示所有可能的选课情况。
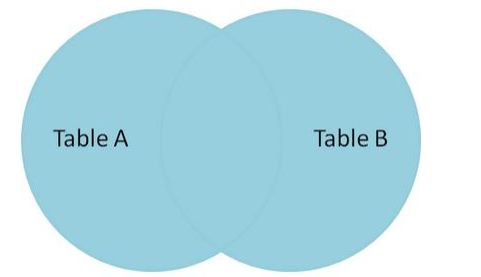
FULL JOIN
全连接产生的所有记录(双方匹配记录)在表 A 和表 B。如果没有匹配,则对面将包含 null。
性能建议
尽量避免使用 Left join 或 Right join,而用 Inner join
在使用 Left join 或 Right join 时,ON 会优先执行,where 条件在最后执行,所以在使用过程中,条件尽可能的在 ON 语句中判断,减少 where 的执行,少用子查询,而用 join。
Mycat 目前版本支持跨分片的 join,主要实现的方式有四种。
全局表,ER 分片,catletT(人工智能)和 ShareJoin,ShareJoin 在开发版中支持,前面三种方式 1.3.0.1 支持
2.全局表
一个真实的业务系统中,往往存在大量的类似字典表的表格,它们与业务表之间可能有关系,这种关系,可以理解为“标签”,而不应理解为通常的“主从关系”,这些表基本上很少变动,可以根据主键 ID 进行缓存,下面这张图说明了一个典型的“标签关系”图:
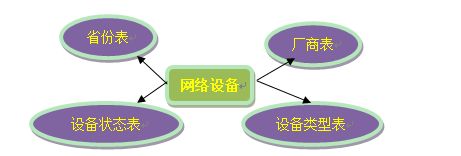
在分片的情况下,当业务表因为规模而进行分片以后,业务表与这些附属的字典表之间的关联,就成了比较棘手的问题,考虑到字典表具有以下几个特性:
• 变动不频繁
• 数据量总体变化不大
• 数据规模不大,很少有超过数十万条记录。
鉴于此,MyCAT 定义了一种特殊的表,称之为“全局表”,全局表具有以下特性:
• 全局表的插入、更新操作会实时在所有节点上执行,保持各个分片的数据一致性
• 全局表的查询操作,只从一个节点获取
• 全局表可以跟任何一个表进行 JOIN 操作
将字典表或者符合字典表特性的一些表定义为全局表,则从另外一个方面,很好的解决了数据 JOIN 的难题。
通过全局表+基于 E-R 关系的分片策略,MyCAT 可以满足 80%以上的企业应用开发。
配置
全局表配置比较简单,不用写 Rule 规则,如下配置即可:
需要注意的是,全局表每个分片节点上都要有运行创建表的 DDL 语句
3.ER Join
MyCAT 借鉴了 NewSQL 领域的新秀 Foundation DB 的设计思路,Foundation DB 创新性的提出了 TableGroup 的概念,其将子表的存储位置依赖于主表,并且物理上紧邻存放,因此彻底解决了 JION 的效率和性能问题,根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上。
customer 采用 sharding-by-intfile 这个分片策略,分片在 dn1,dn2 上,orders 依赖父表进行分片,两个表的关联关系为 orders.customer_id=customer.id。于是数据分片和存储的示意图如下:

这样一来,分片 Dn1 上的的 customer 与 Dn1 上的 orders 就可以进行局部的 JOIN 联合,Dn2 上也如此,再合并两个节点的数据即可完成整体的 JOIN,试想一下,每个分片上 orders 表有 100 万条,则 10 个分片就有 1 个亿,基于 E-R 映射的数据分片模式,基本上解决了 80%以上的企业应用所面临的问题。
配置
以上述例子为例,schema.xml 中定义如下的分片配置:
4.Share join
ShareJoin 是一个简单的跨分片 Join,基于 HBT 的方式实现。
目前支持 2 个表的 join,原理就是解析 SQL 语句,拆分成单表的 SQL 语句执行,然后把各个节点的数据汇集。
配置
支持任意配置的 A,B 表如:
A,B 的 dataNode 相同:
A,B 的 dataNode 不同
或
代码测试
先把表 company 从全局表修改下配置
重新插入数据


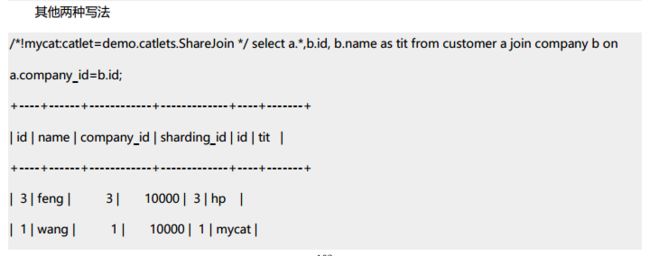
下面可以看下普通的 join 和 sharejoin 的区别:



5.catlet(人工智能)
解决跨分片的 SQL JOIN 的问题,远比想象的复杂,而且往往无法实现高效的处理,既然如此,就依靠人工的智力,去编程解决业务系统中特定几个必须跨分片的 SQL 的 JOIN 逻辑,MyCAT 提供特定的 API 供程序员调用,这就是 MyCAT 创新性的思路——人工智能。
以一个跨节点的 SQL 为例
Select a.id,a.name,b.title from a,b where a.id=b.id
其中 a 在分片 1,2,3 上,b 在 4,5,6 上,需要把数据全部拉到本地(MyCAT 服务器),执行 JOIN 逻辑,具体过程如下(只是一种可能的执行逻辑):
EngineCtx ctx=new EngineCtx();//包含 MyCat.SQLEngine
String sql=,“ select a.id ,a.name from a ” ;
//在 a 表所在的所有分片上顺序执行下面的本地 SQL
ctx.executeNativeSQLSequnceJob(allAnodes,new DirectDBJoinHandler());
DirectDBJoinHandler 类是一个回调类,负责处理 SQL 执行过程中返回的数据包,这里的这个类,主要目的是用 a 表返回的 ID 信息,去 b 表上查询对于的记录,做实时的关联:
DirectDBJoinHandler{
Private HashMap rows;//Key 为 id,value 为一行记录的 Column 原始 Byte 数组,这里是a.id,a.name,b.title 这三个要输出的字段
Public Boolean onHeader(byte[] header){
//保存 Header 信息,用于从 Row 中获取 Field 字段值
}
Public Boolean onRowData(byte[] rowData){
String id=getColumnAsString(“ id” );
//放入结果集,b.title 字段未知,所以先空着
rows.put(getColumnRawBytes(“ id” ),rowData);
//满 1000 条,发送一个查询请求
String sql=” select b.id, b.name from b where id in (………….)” ;
//此 SQL 在 B 的所有节点上并发执行,返回的结果直接输出到客户端
ctx.executeNativeSQLParallJob(allBNodes,sql ,new MyRowOutPutDataHandler(rows));
}
Public Boolean onRowFinished(){}
Public void onJobFinished(){
If(ctx.allJobFinished()){
{///used total time ….}
}
}
最后,增加一个 Job 事件监听器,这里是所有 Job 完成后,往客户端发送 RowEnd 包,结束整个流程。
ctx.setJobEventListener(new JobEventHandler(){public void onJobFinished(){ client.writeRowEndPackage()}});
以上提供一个 SQL 执行框架,完全是异步的模式执行,并且以后会提供更多高质量的 API,简化分布式数据处理,比如内存结合文件的数据 JOIN 算法,分组算法,排序算法等等,期待更多的牛人一起来完善
6.Spark/Storm 对 join 扩展
看到这个标题,可能会感到很奇怪,Spark 和 Storm 和 Join 有关系吗? 有必要用 Spark,storm 吗?
mycat 后续的功能会引入 spark 和 storm 来做跨分片的 join,大致流程是这样的在 mycat 调用 spark,storm的 api,把数据传送到 spark,storm,在 spark,storm 进行 join,在把数据传回 mycat,mycat 在返回给客户端。

本文摘抄于:mycat用户指南