集合
集合的特点
不存放重复的元素
集合使用场合
存放新增IP,统计新增IP量;存放词汇,统计词汇量等
集合的接口设计

集合实现思路
集合可以通过我们的之前介绍的数据结构去实现,例如有动态数组,链表,二叉搜索数(AVL数,红黑树)等,因为我们之前说过红黑树的性能相对来说会比较好,所以demo中我们会采取红黑树去实现,具体代码会在文章末尾给出来
映射(Map)
Map概念
Map在一些编程语言之后又称作字典(dictionary,比如OC,Swift,Python等)
是一个键值对来的,买一个value都对应这个一个key,同理通过key可以获取到相应的value,如下图所示

Map中的每一个key都是唯一的
Map的接口设计

通过对比Map与Set,发现Map中所有的key组合在一起,其实就是一个Set,其实也可以间接利用Map来做内部实现
哈希表
哈希表出现原由?假设现在设计一个写字楼通讯录,存放所有公司的通讯信息,座机号码座位key(假设座机号码最长是8位),公司详情(名称地址等)作为value,添加,删除,搜索的时间复杂度要求是O(1)
我们可以通过数组来满足这个任务:

这样设计会存在什么问题呢?
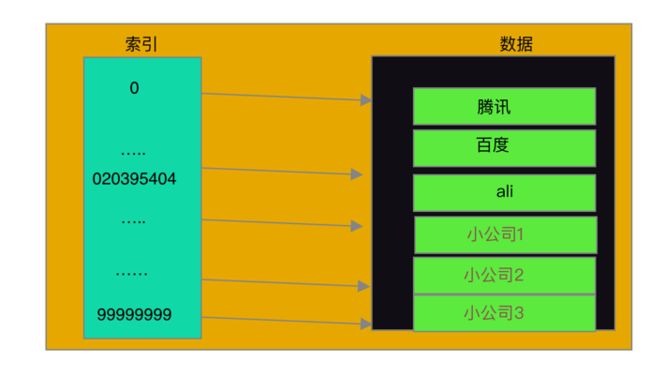
从demo图可以看到,这个就是一个哈希表,但是这样的设计会导致空间使用率非常低,并且浪费内存空间,因此这个时候哈希表的高效处理就派上用途了。
它是如何实现高效处理数据的?请看下图:
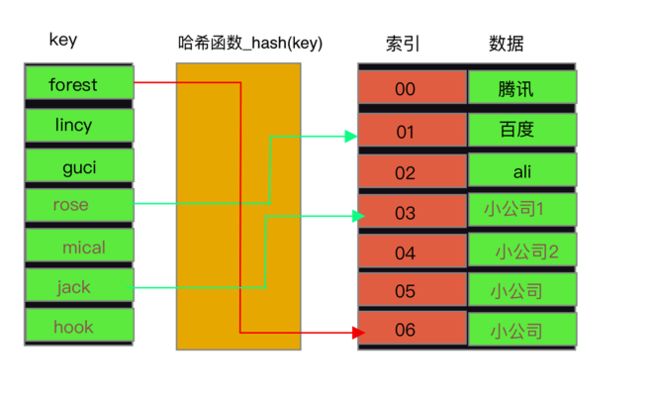
但是会存在一种问题,就是有可能会导致哈希冲突,意思就是两个不同的key,经过哈希函数计算出相同的结果,这种现象称为哈希冲突,如下:

解决哈希冲突的方法
1.开放地址法(Open Addressing)
按照一定规则向其他地址探测,知道遇到空桶
2.再哈希法(Re-Hashing)
设计多个哈希函数
3.链地址法(Separate Chaining)
比如通过链表或者红黑树将同一index的元素串起来


哈希函数
生成哈希表中哈希函数的实现步骤如下:
1.下生成key的哈希值(必须是整数)
2.再让key的哈希值跟数组的大小进行相关运算,生成一个索引值
public int hash(Object key){
return hash_code(key) % table.lenght;
}
为了提高效率,可以使用&位运算取代%运算,墙体是数组的长度设计为2的幂
public int hash(Object key) {
return hash_code(key) & (table.lenght - 1)
}
如何生成key的哈希值
良好的哈希函数能够让哈希值更加均匀分布,减少哈希冲突次数,提升哈希表性能
key的常见种类可能有如下:
1.整数,浮点数,字符串,自定义对象
2.不同种类的key,哈希值的生成方式不一样,当目标是一样的(尽量让每个key的哈希值是唯一,尽量让key的所有信息参与运算)
下面以JAVA语言为例说明相关内容:
在Java中,HashMap的key必须实现hashCode,equal方法,并且允许key为nil
当key为整数(整数值当做哈希值)
public static int hashCode(int Value){
return value;
}
当key为浮点数
将存储的二进制格式转为整数值
float类型
public static int hashCode(float value){
return floatToIntBits(value);
}
Long类型
public static int hashCode(long value){
return (int)(value ^ (value >>> 32));
}
Double类型
public static int hashCode(double value){
long bits = doubleToLongBits(value);
return (int)(bits ^ (bits >>> 32));
}
上面的>>>和^的作用是用来将value的高32bit和低32bit混合计算出32bit的哈希值,如下图所示:

当key是字符串
字符串是由若干个字符组成的,比如字符串jack,由j,a,c,k四个字符组成,因此jack的哈希值可以表示为
j * + a * + c * + k * 等价于[*j * n + a) * n + c] * n + k,在JDK中,乘数n为31,为什么使用31呢?
是因为31是一个奇素数(既是奇数,又是素数,也就是质数),素数和其他数相乘的结果比其他方式更容易产生唯一性,减少哈希冲突,并且JVM会将31 * i优化成(i << 5)-i;
自定义对象的哈希值
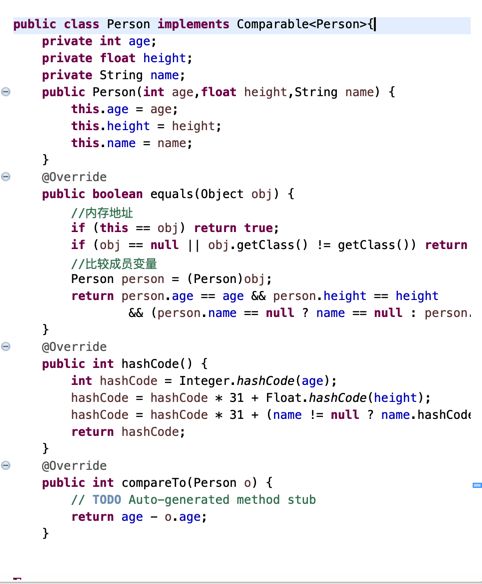
自定义对象作为key
自定义对象作为key,最好同时重写hashCode,equals方法
equals:用于判断2个key是否为同一个key
自反性:对于任何非null的x,x.equals(x) 必须返回true
对称性:对于任何非null的x,y,如果y.equals(x)返回true,x.equals(y)必须返回true
传递性:对于任何非null的x,y,z,如果x.equals(y),y.equals(z)返回true,那么x.equals(z)必须返回true
一致性:对于任何非null的x,y,只要equals的比较操作在对象中所用的信息没有被修改,多次调用x.equals(y),就会一致地返回true,或者一致地返回false,另外对于任何非null的x,x.equals(null)必须返回false
hasCode
必须保证equals为true的2个key的哈希值一样,反过来hashCode相等的key,不一定equals为true
接口设计

接口的设计和实现会在例子中给出来,因为都是基于红黑树来实现的,所以这里就不一一再次解释,不懂可以回到红黑树文章想看一篇,然后再看例子哈,稍微有不同的就是元素节点类型不一样,以前是Node
private Node node(Node node, K k1) 查找Node节点图

这个方法是先比较哈希值,1.哈希值大的从右边取,2.哈希值小的从左边取,3.哈希值相等判断key是否相同,如果相同直接返回node值,4.如果哈希值相等,但是key不相等,并且key不等于空且是同一种类型并具有可比性的话,对比compareTo的结果,为什么需要对比呢,假设有个Person对象存放三个属相new Person("forest","23","m") new Person("macal","23","m"),如果compareTo比较的仅仅是年龄的话,判断cmp=0,就直接覆盖,这样的操作明显是错误的,所以这里需要获取compareTo的结果,cmp大于0的取后边,cmp小于0的取左边,cmp等于0的话,再扫描其他节点(左右节点)
public V put(K key, V value) 添加元素
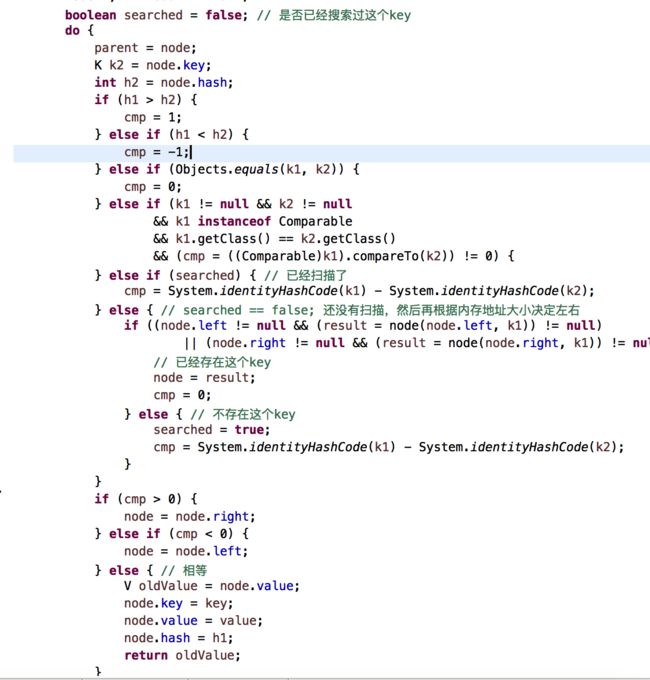
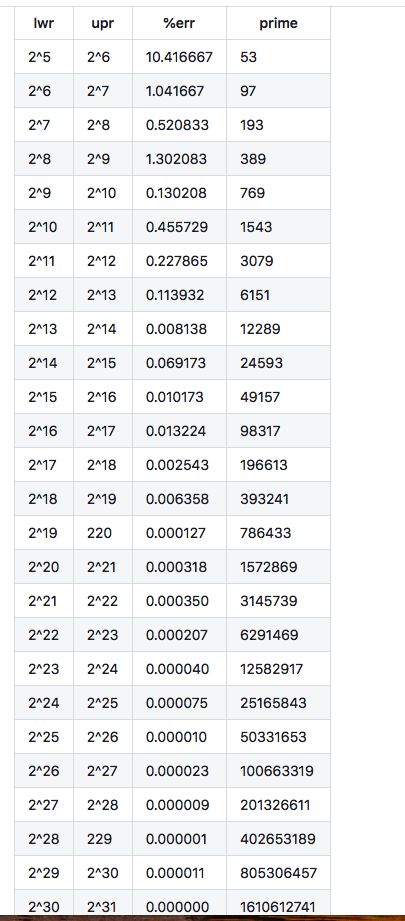
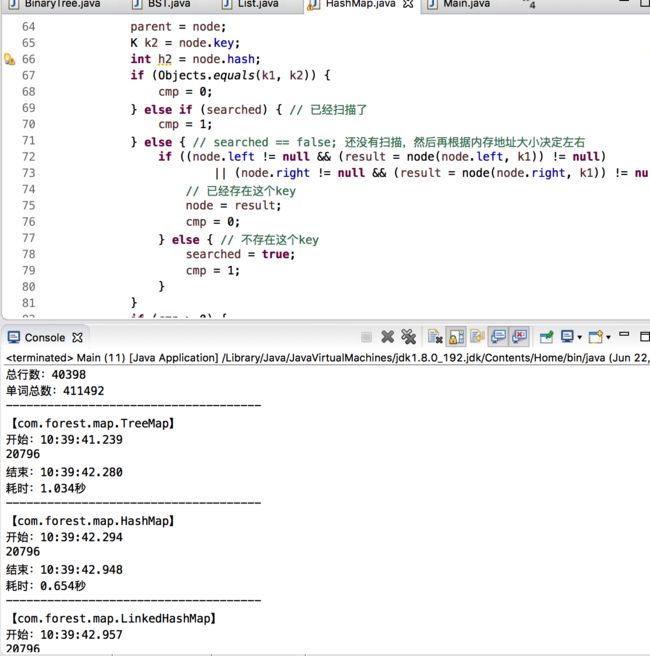
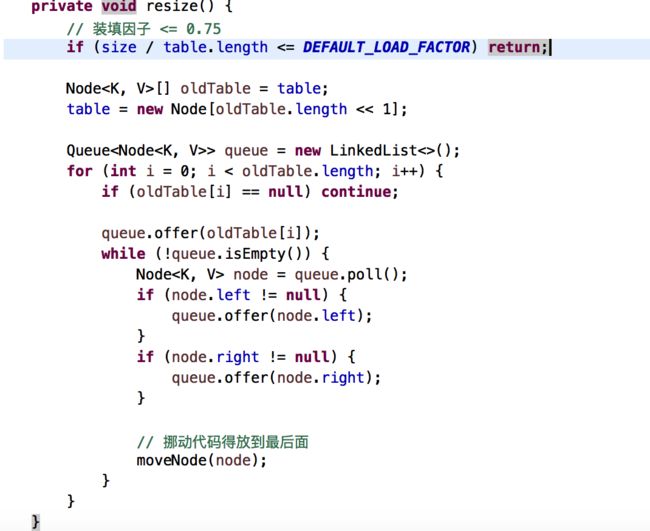
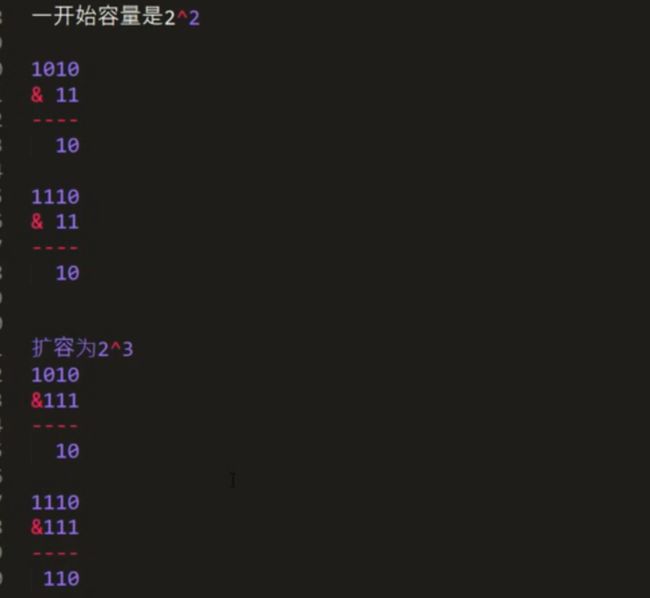
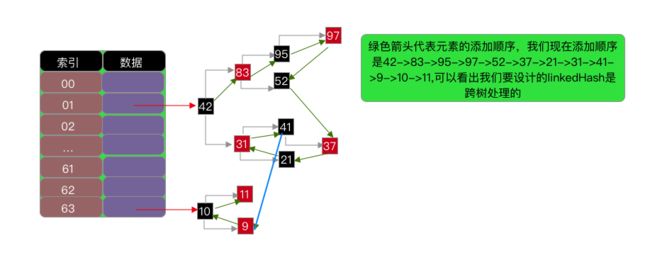
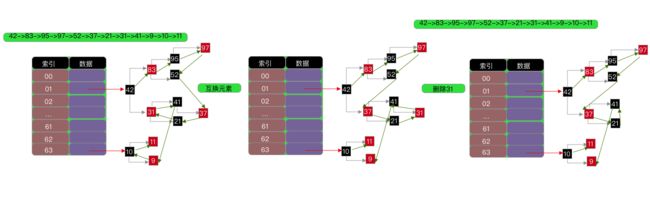
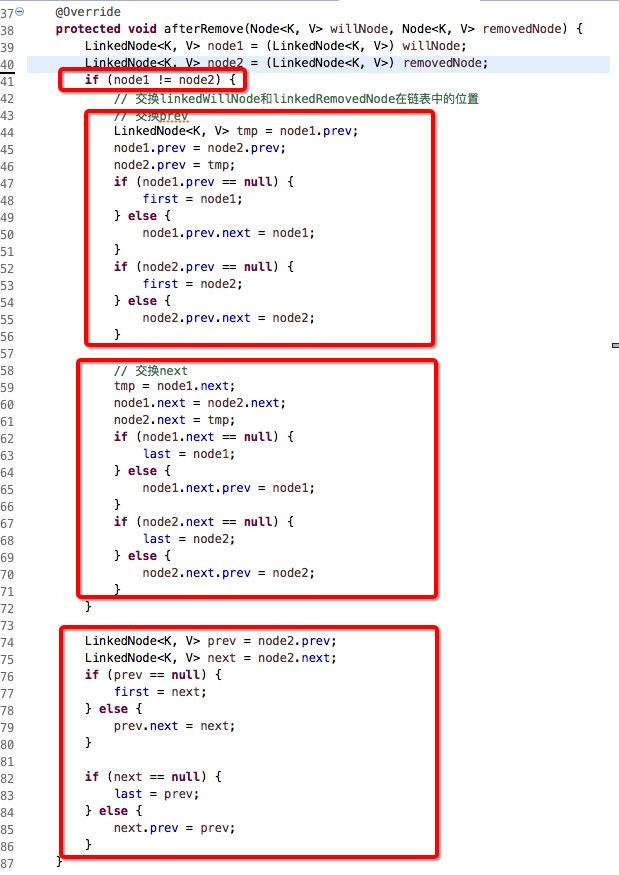
大致分析思路和上面说寻找node节点的差不多,但是可以看到多啦searched这个bool变量值,这个bool变量值是用来标志是否已经搜索个整个树了,这样可以提高算法效率,另外或者这里有人会有疑问,就是,我将h1>h2和h1 扰动计算private int hash(K key); 对key的hashCode进行扰动计算,防止不同hashCode的高位不同但低位相同导致的hash冲突。简单点说,就是为了把高位的特征和低位的特征组合起来,降低哈希冲突的概率; private void resize() 扩容 在讲扩容之前,我们先看看索引的情况先: 当扩容为原来容量的2倍时,节点的索引有两种情况,第一种:保持不变;第二种:index = index + 旧容量; 扩容的思路是将我们原来哈希表上面的值,直接移到新的哈希表上,这样可以节省空间内存,可以看到上面方法中有一个移动的操作: 可以看到会有一个重置的操作,为什么需要重置?是因为将节点移动过去之后,原来的parent,left,right等属性都还在,但是我们不能保持原来的这种关系,我们要维护的是新的关系表,所以需要重置,但是为了防止重置影响扩容,所在在扩容方法执行move之前,需要将left,right入队,这也是为什么moveNode要放在queue.offer 方法后面; linkedHashMap是指遵循一定的添加顺序的,使得遍历的结果是遵从添加顺序的,可以在HashMap的基础上维护元素的添加顺序,使得遍历的结果是遵从添加顺序的,设计形式如下图所示: 因为是基于HashMap实现的,所以很多东西都是相同的,只有个小细节需要更改一下,第一个是需要自定义一个节点继承原来的节点Node,并在自定义的新节点里面添加两个变量子节点,命名为prev,next(因为是用双链表实现的),另外一个就是需要在put方法里面做修改,创建节点的时候,暴露一个创建节点的方法给子节点去实现(目的是为了创建的时候建立双链表的指向链接)代码图如下: createNode 是由多肽方式实现的,实际就是在父类的put方法里面创建所调用,也就是添加元素,到此,添加元素已经可以说是设计完毕了,另外,还有一个方法就是删除方法,删除方法稍微会复杂点,因为涉及到度为2的叶子节点,我们用之前的双链表删除的方法是否还能达到效果呢?且看一下: 可以发现以前的删除双链表元素的方法在这里稍微会有点问题,正确的做法,是在执行删除代码之前,先互换一下删除节点和前驱\后继节点的位置,然后再进行删除,示例图如下: 代码实现图: 第一个红框判断,如果是度为2的叶子节点,就会进入,因为节点会被重新赋值,所以会有不相等的情况 第二个红框交换prev的值 第三个红框交换next的值 第四个红框删除元素 到这里哈希表可以说是介绍完了,具体的实现代码会上传到demo中; 1.关于使用%来计算索引 如果使用%来计算索引,建议把哈希表的长度设计为素数,这样可以大大减少哈希冲突 下面表格列出了不同数据规模对应的最佳素数,特点如下:每个素数略小于前一个素数的2倍,每个素数尽可能接近2的幂


LinkedHashMap



补充知识