写在最前面:
这篇文章是我看了很多博文之后,自己实践后备忘的,在文中也标注了借鉴的地方,非常感谢原博主的分享。
ELK日志分析工具的部署和简单应用:
简介:
面对如此海量的数据,又是分布在各个不同地方,如果我们需要去查找一些重要的信息,难道还是使用传统的方法,去登陆到一台台机器上查看?看来传统的工具和方法已经显得非常笨拙和低效了。于是,一些聪明人就提出了建立一套集中式的方法,把不同来源的数据集中整合到一个地方。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急,我们使用集中化的日志管理集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
对于一个大流量的Web应用通常以Stateless方式设计,这样可以更方便的进行水平扩容。但是随着应用实例数量越来越多,我们查询日志就越来越困难。在没有日志系统的情况下,首先我们需要定位到请求的服务器地址,如果每台服务器都部署了多个应用实例,我们则需要去每个应用实例的日志目录下去找日志文件。每个服务可能还会设置日志滚动策略(如:每200M一个文件),还有日志压缩归档策略。
我们查询一条出错信息就要在茫茫多的日志文件里去找到它,于是使出我们的十八般武艺head less tail grep wc awk count cut,但是如果需要统计最近3天的某个接口的异常次数。。。。
除了上面出现的状况我们还需要考虑:日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询,ELK就是帮我们来解决这些问题的。
开源实时日志分析ELK平台能够完美的解决我们上述的问题,ELK由ElasticSearch、Logstash和Kiabana三个开源工具组成。官方网站:https://www.elastic.co
注:以上内容来自于:http://www.jianshu.com/p/a3cad629fa40
和https://www.zhihu.com/question/59957272/answer/170694929
环境:
-CentOS 6.5
- elasticsearch-2.3.4
- kibana-4.5.3-linux-x64
- logstash-2.3.4
- filebeat-1.3.1
- jdk1.8.0_131
过程:
-安装JDK
-安装Elasticsearch
-安装Kibana
-安装Logstash
-配置Logstash
-安装filebeat
-访问
安装Java 环境:
下载JDK的安装包并解压:
tar -zxvf jdk-8u131-linux-x64.tar.gz
配置环境变量:vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_131
CLASSPATH=$JAVA_HOME/lib/
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
使设置的环境变量生效:
source /etc/profile
安装Elasticsearch:
下载Elasticsearch的安装包并解压:
tar -zxvf elasticsearch-2.3.4.tar.gz
更改配置文件:vim config/elasticsearch.yml
network.host: 0.0.0.0
http.port: 9200
cluster.name: es_cluster_yangkg
node.name: node-1
(没有目录的请自行创建)
path.data: /usr/local/elk/elasticsearch-2.3.4/data
path.logs: /usr/local/elk/elasticsearch-2.3.4/logs
启动(会有报错):
cd /usr/local/elk/elasticsearch-2.3.4
bin/elasticsearch
#会有报错,信息如下:
Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:93)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:144)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:270)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:35)
Refer to the log for complete error details.
报错信息提示我们es无法用root用户启动,所以可以创建elk用户,来启动
解决方法:如下
创建elk用户来启动elasticsearch如:创建elk用户组以及elk用户
groupadd elk组名)
useradd elk(用户名) -g elk(组名) -p elk(密码)
更改Elasticsearch文件夹以及内部文件的所属用户以及组为elk
chown -R elk:elk elasticsearch-2.3.4
更改后的权限如图所示:

在启动中可能还会遇到很多问题:
可以参考博客解决:
http://blog.csdn.net/hey_wonderfulworld/article/details/73612929
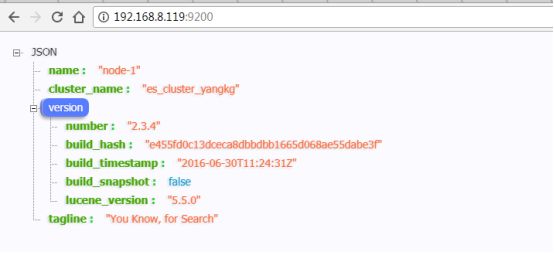
启动成功后在浏览器输入:ip地址:9200/
能看到如下页面表示启动成功:
安装head插件:
经过多次尝试,终于还是安装上了,但是这个插件真是难装,所以我推荐一种简单的方法:在谷歌浏览器的安装插件(ElasticSearch Head),
如下图:
安装kibana:
下载并解压安装包:
tar -zxvf kibana-4.5.3-linux-x64
修改配置文件:vim config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
kibana.index: ".kibana"
启动,观察是否有报错信息:
cd /usr/local/elk/kibana-4.5.3-linux-x64
bin/kibana
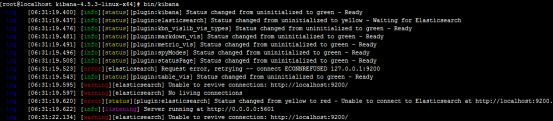
在浏览器输入:ip地址:5601
出现如下页面表示启动成功,上图中出现警告说明elasticsearch的服务没有启动。
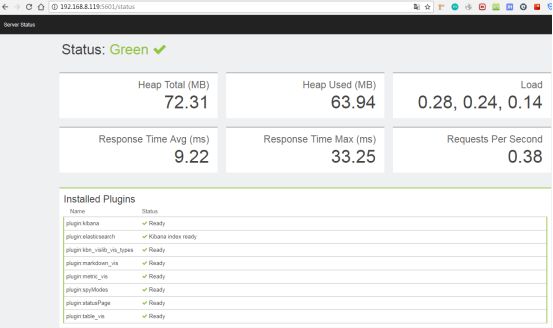
安装Logstash:
下载并解压安装包:
tar -zxvf logstash-2.3.4.tar.gz
启动服务:
cd /usr/local/elk/logstash-2.3.4
bin/logstash -e 'input { stdin { } } output { stdout {} }'
启动完成后输入:hello world测试服务输出是否正常。
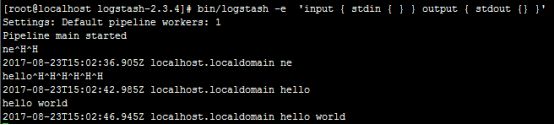
客户端安装filebeat:
下载解压安装包:
修改filebeat.yml
cd /usr/local/filebeat
vim filebeat.yml
写入:
filebeat:
prospectors:
-
paths:
- /var/log/*
input_type: log
document_type: log
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts: ["服务端IP:5044"]
tls:
certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"]
shipper:
logging:
files:
rotateeverybytes: 10485760 # = 10MB
启动:
cd /usr/local/filebeat
nohup ./filebeat -e -c filebeat.yml &
Logstash实战:
内容来源于:http://www.jianshu.com/p/25ed5ed46682
vLogstash使用配置:
运行:bin/logstash -f config/logstash.conf
vlogstash.conf整个配置文件分为三部分:input,filter,output
input {
#输入
}
filter{
#过滤匹配
}
output {
#输出
}
vinput配置:
nfile{}(文件读取)
监听文件变化,记录一个叫.sincedb的数据库文件来跟踪被监听的日志文件的当前读取位(也就是时间戳).
格式:
input {
#file可以多次使用,也可以只写一个file而设置它的path属性配置多个文件实现多文件监控
file {
path =>["/var/log/access.log", "/var/log/message"]#监听文件路径
type => "system_log"#定义事件类型
start_position =>"beginning"#检查时间戳
}
}
参数说明:
exclude:排除掉不想被监听的文件
stat_interval:logstash每隔多久检查一次被监听文件状态(是否有更新),默认是1秒。
start_position:logstash默认是从结束位置开始读取文件数据,也就是说logstash进程会以类似tail -f的形式运行。如果你是要导入原有数据,把这个设定改成“beginning”,logstash进程就按时间戳记录的地方开始读取,如果没有时间戳则从头开始读取,有点类似cat,但是读到最后一行不会终止,而是继续变成tail -f。
ncodec(定义编码类型)
优化建议:直接输入预定义好的JSON数据,这样就可以省略掉filter/grok配置,从而减轻过滤器logstash的CPU负载消耗;
配置文件示例:
input {
file {
type =>"access_u_ex"
#添加自定义字段
add_field => {"fromhost"=>"EIR"}
#监听文件的路径
path =>"D:/java/logs/test/test1*"
#排除不想监听的文件
exclude =>"test13.log"
#监听文件的起始位置
start_position =>"beginning"
#增加标签
#tags => "tag1"
#设置多长时间扫描目录,发现新文件
#discover_interval=> 15
#设置多长时间检测文件是否修改
#stat_interval => 1
codec => multiline {
charset =>"GB2312"
patterns_dir => ["d:/java/logstash-2.3.4/bin/patterns"]
pattern =>"^%{SECOND_TIME}"
negate =>true
what =>"previous"
}
}
}
从上到下,解释下配置参数的含义:
file :读取文件。
path :日志文件绝对路径(只支持文件的绝对路径)。
type :定义类型,以后的filter、output都会用到这个属性。
add_field:添加字段,尽量不要与现有的字段重名。重名的话可能会有不同错误出现。
start_position:从什么位置开始读取文件,默认是结束位置。如果要导入原有数据,把这个设定改为beginning .
discover_interval:设置多长时间检查一个被监听的path下面是否有新文件。默认时间是15秒.
exclude:不想监听的文件排除出去。
stat_interval:设置多久时间检查一次被监听的文件(是否有更新),默认是1秒。
说明:
a、有时候path可能需要配置多个路径:
`path => ["D:/java/logs/test/test1*","D:/java/logs/test/test2*"]
b、add_field添加字段时,想判断要添加的字段是否存在,不存在时添加
if![field1]{
mutate{
add_field=> {"field1" => "test1"}
}
}
codec编码插件
logstash实际上是一个input | codec | filter | codec |
output的数据流。codec是用来decode、encode事件的。
Multiline合并多行数据
Multiline有三个设置比较重要:pattern、negate、what .
pattern:必须设置,String类型,没有默认值。匹配的是正则表达式。上面配置中的含义是:通过SECOND_TIME字段与日志文件匹配,判断文件开始位置。
negate:boolean类型,默认为false .如果没有匹配,否定正则表达式。
what:必须设置,可以设置为previous或next .(ps:还没弄清楚两者之间的关系,目前我用的都是previous )。
根据上面的配置,还有两个设置:charset、patterns_dir。
charset :一般都知道是编码,这个就不多说了。
patterns_dir:从配置中看到的是一个文件路径。
vfilter过滤器配置:
ndata(时间处理)
用来转换日志记录中的时间字符串,变成LogStash::Timestamp对象,然后转存到@timestamp字段里。
注意:因为在稍后的outputs/elasticsearch中index常用的%{+YYYY.MM.dd}这种写法必须读取@timestamp数据,所以一定不要直接删掉这个字段保留自己的时间字段,而是应该用filters/date转换后删除自己的字段!至于elasticsearch中index使用%{+YYYY.MM.dd}这种写法的原因后面会说明。
格式:
filter{
grok {
match =>["message", "%{HTTPDATE:logdate}"]
}
date {
match=> ["logdate", "dd/MMM/yyyy:HH:mm:ss Z"]
}
}
ngrok(正则匹配)
可参考:https://grokdebug.herokuapp.com/
http://blog.csdn.net/liukuan73/article/details/52318243/
语法格式如下:
%{正则表达式或正则子句:你要赋值的变量名}
filter{
grok {
match => [ "message","\s+(?\d+?)\s+" ]#跟python的正则有点差别
}
}
%{语法:语义}
“语法”指的就是匹配的模式,例如使用NUMBER模式可以匹配出数字,IP则会匹配出127.0.0.1这样的IP地址:
%{NUMBER:lasttime}%{IP:client}
默认情况下,所有“语义”都被保存成字符串,你也可以添加转换到的数据类型
%{NUMBER:lasttime:int}%{IP:client}
目前转换类型只支持int和float
优化建议:如果把“message”里所有的信息都grok到不同的字段了,数据实质上就相当于是重复存储了两份。所以可以用remove_field参数来删除掉message字段,或者用overwrite参数来重写默认的message字段,只保留最重要的部分。
filter {
grok {
patterns_dir =>"/path/to/your/own/patterns"
match => {"message" =>"%{SYSLOGBASE} %{DATA:message}"}
overwrite => ["message"]
}
}
filter {
grok {
match => ["message", "%{HTTPDATE:logdate}"]
remove_field =>["logdate"]
}
}
Logstash内置正则文件:/patterns/grok-patterns
可以在此文件中进行添加项;
覆盖overwrite:
使用Grok的overwrite参数也可以覆盖日志中的信息
filter {
grok {
match =>{ "message" => "%{SYSLOGBASE} %{DATA:message}" }
overwrite=> [ "message" ]
}
}
日志中的message字段将会被覆盖
这里有很多语法,不过多说,网上有很多资料,需要啥,直接找就是。
vOutput
output {
stdout{ codec=>rubydebug}#直接输出,调试用起来方便
#输出到redis
redis {
host => '10.120.20.208'
data_type => 'list'
key => '10.99.201.34:access_log_2016-04'
}
#输出到ES
elasticsearch {
hosts =>"192.168.0.15:9200"
index => "%{sysid}_%{type}"
document_type => "%{daytag}"
}
}
附:
1、Grok正则在线验证http://grokdebug.herokuapp.com/
2、Logstash配置https://my.oschina.net/shawnplaying/blog/670217
3、Logstash最佳实践http://udn.yyuap.com/doc/logstash-best-practice-cn/index.html