使用 Python 模块 re 实现解析小工具
孙 翎, 贺 皓, 和 张 晗
2011 年 4 月 12 日发布
概要
在开发过程中发现,Python 模块 re(Regular Expression)是一个很有价值并且非常强大的文本解析工具,因而想要分享一下此模块的使用方法。
有这样一个简单而有趣的实践范例:对于喜欢追看美剧的年轻人,最新一集美剧的播出时间常常是一个让人头疼的问题,一个实时更新美剧播出时间表的小工具会很受欢迎。
本文通过以上这个实例,描述如何抓获 TV.com 网站上的文本信息,利用 Python 的 re 模块进行解析,并将热门美剧播出时间显示在自己的网页上,希望能够以娱乐的方式很好的解释 re 模块的用法。
Python 正则表达式模块 (re) 简介
Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使用这一内嵌于 Python 的语言工具,尽管不能满足所有复杂的匹配情况,但足够在绝大多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。Python 会将正则表达式转化为字节码,利用 C 语言的匹配引擎进行深度优先的匹配。
Python 正则表达式语法
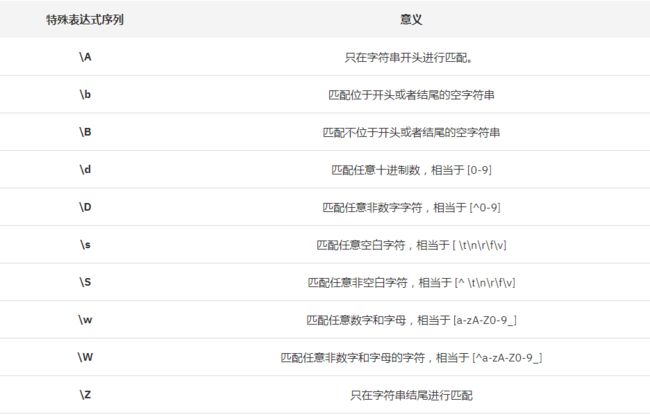
正则表达式可以包含普通字符和特殊字符,普通字符(比如数字或者字母)可以直接对目标字符串进行匹配,在本文中我们主要讨论利用特殊字符来模糊匹配某一些字符串的方法,比如'|'或者'(',使用这些特殊字符,正则表达式可以表示某一类的普通字符,或者是改变其周围的正则表达式的含义。具体如表 2-1 所示:
表 1. 正则表达式语法 (真的是通俗易懂了~)
关于*?, +?, ?? 这个部分的例子有些纰漏. <.*>是贪婪匹配, <.*?>是非贪婪匹配(最小匹配)
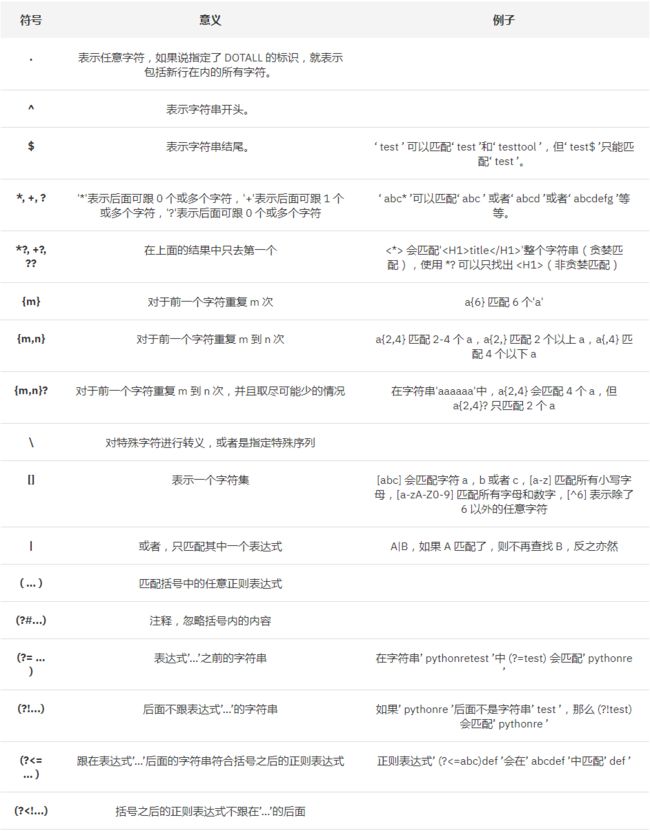
包含’ \ ’的特殊序列的意义如表 2-2:
表 2. 正则表达式特殊序列
Python re 的主要功能
Python 的 re 正则表达式模块定义了一系列函数,常量以及异常;同时,正则表达式被编译成‘ RegexObject ’实例,本身可以为不同的操作提供方法。接下来简要介绍一下这些函数的功能和用法。
compile
re.compile(pattern[, flags])
把正则表达式的模式和标识转化成正则表达式对象,供 match() 和 search() 这两个函数使用。
re 所定义的 flag 包括:
re.I 忽略大小写
re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
re.M 多行模式
re.S 即为’ . ’并且包括换行符在内的任意字符(’ . ’不包括换行符)
re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
re.X 为了增加可读性,忽略空格和’ # ’后面的注释
例:以下两种用法结果相同:
A)
compiled_pattern = re.compile(pattern)
result = compiled_pattern.match(string)
B)
result = re.match(pattern, string)
search
re.search(pattern, string[, flags])
在字符串中查找匹配正则表达式模式的位置,返回 MatchObject 的实例,如果没有找到匹配的位置,则返回 None。
对于已编译的正则表达式对象来说(re.RegexObject),有以下 search 的方法:
search (string[, pos[, endpos]])
若 regex 是已编译好的正则表达式对象,regex.search(string, 0, 50) 等同于 regex.search(string[:50], 0)。
具体示例如下。
>>> pattern = re.compile("a")
>>> pattern.search("abcde") # Match at index 0
>>> pattern.search("abcde", 1) # No match;
match
re.match(pattern, string[, flags])
判断 pattern 是否在字符串开头位置匹配。对于 RegexObject,有:
match(string[, pos[, endpos]])
match() 函数只在字符串的开始位置尝试匹配正则表达式,也就是只报告从位置 0 开始的匹配情况,而 search() 函数是扫描整个字符串来查找匹配。如果想要搜索整个字符串来寻找匹配,应当用 search()。
split
re.split(pattern, string[, maxsplit=0, flags=0])
此功能很常用,可以将将字符串匹配正则表达式的部分割开并返回一个列表。对 RegexObject,有函数:
split(string[, maxsplit=0])
例如,利用上面章节中介绍的语法:
>>> re.split('\W+', 'test, test, test.')
['test', 'test', 'test', '']
>>> re.split('(\W+)', ' test, test, test.')
[' test ', ', ', ' test ', ', ', ' test ', '.', '']
>>> re.split('\W+', ' test, test, test.', 1)
[' test ', ' test, test.']
对于一个找不到匹配的字符串而言,split 不会对其作出分割,如:
>>> re.split('a*', 'hello world')
['hello world']
findall
re.findall(pattern, string[, flags])
在字符串中找到正则表达式所匹配的所有子串,并组成一个列表返回。同样 RegexObject 有:
findall(string[, pos[, endpos]])
示例如下:
#get all content enclosed with [], and return a list
>>> return_list = re.findall("(\[.*?\])",string)
finditer
re.finditer(pattern, string[, flags])
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并组成一个迭代器返回。同样 RegexObject 有:
finditer(string[, pos[, endpos]])
sub
re.sub(pattern, repl, string[, count, flags])
在字符串 string 中找到匹配正则表达式 pattern 的所有子串,用另一个字符串 repl 进行替换。如果没有找到匹配 pattern 的串,则返回未被修改的 string。Repl 既可以是字符串也可以是一个函数。对于 RegexObject 有:
sub(repl, string[, count=0])
此语法的示例有:
>>> p = re.compile( '(one|two|three)')
>>> p.sub( 'num', 'one word two words three words')
'num word num words num words'
同样可以用以下方法,并指定 count 为 1(只替换第一个):
>>> p.sub( 'num', ' one word two words three words', count=1)
' num word two words three words'
subn
re.subn(pattern, repl, string[, count, flags])
该函数的功能和 sub() 相同,但它还返回新的字符串以及替换的次数。同样 RegexObject 有:
subn(repl, string[, count=0])
实例分析 - 使用 re 模块实现美剧时间表
这一章节将描述使用 re 模块进行文本解析并实现美剧播出时间表小工具的细节。我们会引用实际的代码片段,解释在实际程序中,应当如何使用 re 模块实现文本解析的功能。
需求分析
为了将我们感兴趣的信息全部提取出来渲染到一个单独的页面上,我们选取 www.tv.com 的 html 作为数据源,获取到其 HTML 文本之后用正则表达式解析并获得相关内容。
请注意用正则表达式分析 HTML 或 XML 是痛苦的。随处可见的变化使得写出一个通用的正则表达式变得极为困难,象这样的任务使用专用的 HTML 或 XML 解析器更为适宜 ( 如 http://www.crummy.com/software/BeautifulSoup/, 值得一提的是,这个解析器也是用 Python RE 实现的 ),为了演示 Python RE 的使用,本文全部使用正则表达式处理文本。
实现步骤
因为此工具的最后结果会被呈现在一个网页上,它的主要功能就是从上述的 html code 中提取出我们感兴趣的 element, 并按照我们自己的对内容的选择重新生成一个个性化过的页面,请参见附件查看我们将要解析的 html 文本。
通过检视此 html 文件,我们需要提取的 html element 只有被 head 标签修饰的文档信息元素,和被 div 标签修饰,id 值为 episode_listing 的块级区域。
下面对实现这部分功能的主要代码进行一些分析。
以只读方式打开所需处理文本并读入其内容:
fh = open("~/vampire_episode.html", "r")
fh_str = fd.read()
读取剧集标题,使用正则表达式匹配以“”结束的元素,注意此处使用非贪婪匹配以获取首次匹配的内容:
title = re.findall("", fds)
查看一下变量类型和内容:
In [74]: type(title)
Out[74]:
In [75]: print title
-------> print(title)
['The Vampire Diaries Season 2 Episode Guide on TV.com']
读取 html 文本中 id 值为 episode_listing 的 div 元素,注意由于此元素会跨越多行,我们在调用 findall 函数时需要指定 re.S 标志,同样使用非贪婪匹配:

此时我们已经获取到全部所需内容,将他们写入另一个 html 文件:
'''
部分测试用的website失效. 且的语法规则对程序code支持不够好. 跳过.
需要阅读的可以查看:https://www.ibm.com/developerworks/cn/opensource/os-cn-pythonre/index.html
'''
小结
尽管对于 Python 正则表达式模块(re)的语法和相关函数的描述并不全面,但文章以简洁的方式介绍了最常用的正则表达式语法和函数调用方法,关于更为复杂和深入的用法讨论,读者可以参考官方文档。在之后的章节中,本文直观地通过网页文本解析的实例,讲解了美剧播出时间解析小工具的实现方法和步骤,希望最后的网站示例和演示结果能够提供给这一模块的功能学习提供一些有趣并有用的帮助。
相关主题
参考 Python 使用文档中 RE 相关章节The Python Standard Library - Regular expression operations,查看 RE 语法使用细节。
参看文章Regular Expressions Primer,了解更多 Python RE 的使用实例。
参看 developerWorks 中的文章可爱的 Python:Python 中的文本处理,了解使用 Python RE 进行文本解析的实例。