GBDT的核心就在于累加所有树的结果作为最终结果。
分类树
决策树的分类算法有很多,以具有最大熵的特征进行分类,以信息增益特征进行分类(ID3),以增益率特征进行分类(C4.5),以基尼系数特征进行分类(CART分类与回归树)等等。这一类决策树的特点就是最后的结果都是离散的具体的类别,比如苹果的好/坏,性别男/女。
回归树
回归树与分类树的流程大致一样,不同的是回归树在每个节点都会有一个预测值,以年龄为例,该节点的预测值就是所有属于该节点的样本的年龄的均值。
那回归树是根据什么来划分特征的呢?
分类树的最大熵、信息增益、增益率什么的在回归树这都不适用了,回归树用的是均方误差。遍历每个特征,穷举每个特征的划分阈值,而这里不再使用最大熵,使用的是最小化均方差——(每个人的年龄-预测年龄)^2/N,N代表节点内样本数。这很好理解,和预测年龄差距越大,均方差也就越大。因此要找到均方差最小的阈值作为划分点。
划分的结束条件一般有两个:第一是划分到每一个节点都只包含一个年龄值,但是这太难了;第二就是划分到一定的深度就停止,取节点内数据的均值作为最终的预测值。
XGBoost
XGBoost其实是由一群训练出来的CART回归树集成出来的模型。
明确目标
我们的目标其实就是训练一群回归树,使这树群的预测值尽量接近真实值,并且有尽可能强大的泛化能力。来看看我们的优化函数:
i表示的是第i个样本,前一项是表示的是预测误差。后一项表示的是树的复杂度的函数,值越小表示复杂度越低,泛化能力越强。我们来看看后一项的表达式:
树的复杂度函数
其中T表示叶子节点的个数,w表示的是节点的预测值(回归树的节点才有预测值)。
我们要做的就是使预测误差尽量小,叶子节点数尽量少,预测值尽量不极端(什么叫预测值尽量不极端?举个栗子,一个人的真实年龄是4岁,有两个模型,第一个模型的第一颗回归树预测值是3岁,第二颗回归树预测值是1岁,第二个模型的第一颗回归树预测值是2岁,第二颗预测值也是2岁,那我们更倾向于选择第二个模型,因为第一个模型学习的太多,有过拟合的风险)
那么我们如何才能把优化函数和回归树的参数联系在一起呢?回归树的参数我们知道有两个:(1)选哪个feature进行分裂(2)如何求取节点的预测值,上述公式并没有很好地反映出这两个问题的答案,那么是如何解决上述两个问题的呢?
答案就是:贪心策略+最优化(二次最优化)
贪心策略
那么是如何运用贪心策略(眼前利益最大化,每个节点的预测值都选最优)的呢?假设我们有一堆样本,放在第一个节点,这时T=1,w是多少呢?暂时不知道,w是计算出来的,这时所有的样本的w都相等,将w和T代入优化函数中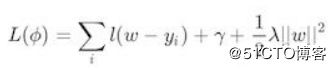
第一步的优化函数
如果我们这里的l(w-y_i)损失函数使用的是平方损失函数,那么上式就变成了一个关于w的二次函数,最小的点就是极值点也就是该节点的预测值。
到这你可能发现了,这不就是二次函数的最优化问题吗?
那如果损失函数不是平方误差函数怎么办?我们采用的是泰勒展开的方式,任何函数总能用泰勒展开的方法表示,不是二次函数我们总能想办法让它变成二次函数。
那么我们再来看我们的两个问题:
(1)选哪个feature进行分裂?最粗暴的枚举法,用损失函数效果最好的那一个(粗暴枚举和XGBoost的并行化等我们在后面介绍)
(2)如何求取节点的预测值,对!就是我们刚刚说到的二次函数求最值(固定套路:二次函数求导为零的点就是最优值)!
那么步骤就是:枚举第一个feature,计算loss_function的最小值,枚举第二个feature,计算loss_function的最小......直到遍历完所有的feature,选择效果最好的feature,将feature的值分成大于w和小于w的两类,这不就把树给分成两叉了吗?
接下来继续分裂,在上一个分类的基础上,又形成一棵树,再形成一棵树,每次都是在最优的基础上进行分裂,不就是我们的贪心策略么。
但是一般这种循环迭代的方式都需要一个终止条件,总不能让它一直跑下去吧。
停止条件
停止条件大概有以下几种:
(1)当引入的分裂带来的增益(loss_function的降低量)小于一个阈值的时候,可以剪掉当前的分裂,所以并不是每一次分裂loss_function都会增加的。
(2)当树达到最大深度时,停止建树,因为树的深度太深容易出现过拟合,这里需要设置一个超参数max_depth。
(3)当样本权重和小于某一个阈值时也停止建树,涉及到一个超参数:最小样本权重和,大意就是如果每个叶子节点包含的样本数量太少也停止,同样是过拟合的原因。
XGBoost的亮点(重点)
节点权值
XGBoost的权值是通过最优化二次函数(求导)求出来的,算是一种创新吧,和普通的求均值的或者其他什么规则不一样。
避免过拟合(正则化、shrinkage与采样技术)
正则化
一说起过拟合,我们的第一反应就是正则化。XGBoost也是这样做的。
我们在loss_function里看到了正则化项(树的复杂度函数),正则化的目的就是防止过拟合。我们再看看这个函数:
树的复杂度函数
这里出现了γ和λ,这是XGBoost自己定义的,在使用XGBoost时,你可以设定它们的值,显然,γ越大,表示越希望获得结构简单的树,因为要整体最小化的话就要最小化T。λ越大也是越希望获得结构简单的树。
Shrinkage
除了使用正则化,我们还有shrinkage与采样技来避免过拟合的出现。
所谓的shrinkage就是在每次的迭代产生的树中,对每个叶子结点乘以一个缩减权重,主要的目的就是缩减该次迭代产生的树的影响力,留给后边迭代生成的树更多发挥的空间。
举个栗子:比如第一棵树预测值为3.3,label为4.0,第二棵树才学0.7,那后面的树就没啥可学的了,所以给他打个折扣,比如3折,那么第二棵树训练的残差为4.0-3.3*0.3=3.01,这就可以发挥了啦,以此类推,作用的话,就是防止过拟合。
采样技术
采样技术有两种,分别是行采样和列采样。
列采样效果比较好的是按层随机的方法:之前提到,每次分裂节点的时候我们都要遍历所有的特征和分割点,来确定最优分割点。如果加入列采样,我们会在同一层的结点分割前先随机选一部分特征,遍历的时候只用遍历这部分特征就行了。
行采样则是采用bagging的思想,每次只抽取部分样本进行训练,不使用全部的样本,可以增加树的多样性。
损失函数
这个点也是XGBoost比较bug的地方,因为XGBoost能够自定义损失函数,只要能够使用泰勒展开(能求一阶导和二阶导)的函数,都可以拿来做损失函数。你开心就好!
支持并行化
一直听别人说XGBoost能并行计算,感觉这才是XGBoost最bug的地方,但是直观上并不好理解,明明每次分裂节点都用到了上一次的结果,明明是个串行执行的过程,并行这个小妖精到底在哪?答案就在我们的第一个问题之中:选哪个feature进行分裂?就是在枚举,选择最佳分裂点的时候进行(读者可以先试着往下读,如果理解不了的话建议将之前文章提过的AdaBoost的代码实现一遍,有助于理解)。
注意:同层级节点之间可以并行。节点内选择最佳分裂点,候选分裂点计算增益使用并行。
每个节点都包含样本,我们要从中节点样本的每一个feature中选择最佳的分裂值。如果feature的值是离散的,比如判断性别男/女,这样的feature计算增益很容易。但是如果feature的值是连续的,从5k-10k都有,总不能一个一个值都当做分裂点来计算增益吧(缺点:1、计算量太大;2、分割后的叶子节点样本过少,过拟合),常用的方法是划分区间,具体怎么划分呢?
XGBoost的作者提出了一种算法:Weighted Quantile Sketch
一般的,我们的loss_function泰勒展开之后长这样: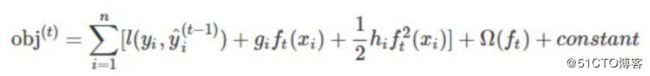
泰勒展开后的一般损失函数
f_t(x_i)是什么?它其实就是f_t的某个叶子节点的值。之前我们提到过,叶子节点的值是可以作为模型的参数的。其中:

g_i和h_i
其实这里的g_i和h_i描述的就是不同的预测值对loss_function的影响。
用通俗的例子来解释算法:
将收入值升序排列:(5k,5.1k,5.2k...,10k),分割线(收入1,收入2,...,),满足(节点内每个间隔的样本的h_i之和/节点总的h_i之和)某个百分比ϵ,所以大约有1/ϵ个分裂点。
针对稀疏数据的解决方法
实际应用中,稀疏数据无法避免,产生稀疏数据的原因:(1)数据缺失;(2)统计上的0;(3)特征表示中的one-hot形式;以往的经验,出现稀疏值的时候算法需要很好地自适应,XGBoost提出的方法如下:
假设样本的第i个特征缺失,无法使用该特征进行样本划分,那我们就把缺失样本默认的分到某个节点,具体分到哪个节点还要根据算法:
算法思想:分别假设缺失属于左节点和右节点,而且只在不缺失的样本上迭代,分别计算样本属于左子树和右子树的增益,选择增益最大的方向作为缺失数据的默认方向。