StarGAN的引入是为了解决多领域间的转换问题的,之前的CycleGAN等只能解决两个领域之间的转换,那么对于含有C个领域转换而言,需要学习C*(C-1)个模型,但StarGAN仅需要学习一个,而且效果很棒,如下:
创新点:为了实现可转换到多个领域,StarGAN加入了一个域的控制信息,类似于CGAN的形式。在网络结构设计上,鉴别器不仅仅需要学习鉴别样本是否真实,还需要对真实图片判断来自哪个域。

整个网络的处理流程如下:
- 将输入图片x和目标生成域c结合喂入到生成网络G来合成fake图片
- 将fake图片和真实图片分别喂入到鉴别器D,D需要判断图片是否真实,还需要判断它来自哪个域
- 与CycleGAN类似,还有一个一致性约束,将生成的fake图片和原始图片的域信息c'结合起来喂入到生成器G要求能输出重建出原始输入图片x
下面分析一下各个部分的损失函数:
一:GAN常见的对抗损失:

二:对于给定的输入图片x和目标域标签c,网络的目标是将x转换成输出图片y,输出图片y能够被归类成目标域c。为了实现这一点就需要鉴别器有判别域的功能。所以作者在D的顶端加了一个额外的域分类器,域分类器loss在优化D和G时都会用到,作者将这一损失分为两个方向,分别用来优化G和D。(这很容易理解,因为如下分析可以看到公式(3)没有办法为D提供训练需要的监督信息)
一个是真实图片的域分类损失用来优化D,另一个是fake图片的域分类损失来优化G。
1)
Dcls(c'|x)代表D对真实图片计算得到的域标签概率分布。这一学习目标将会使得D能够将输入图片x识别为对应的域c',这里的(x,c')是训练集给定的。
2)
 fake图片的域分类的损失函数定义如(3),它用来优化G,也就是让G尽力去生成图片让它能够被D分类成目标域c。
fake图片的域分类的损失函数定义如(3),它用来优化G,也就是让G尽力去生成图片让它能够被D分类成目标域c。
三:还有一个重建损失
通过最小化对抗损失与分类损失,G努力尝试做到生成目标域中的现实图片。但是这无法保证学习到的转换只会改变输入图片的域相关的信息而不改变图片内容。所以加上了周期一致性损失:
 这里就是将G(x,c)和图片x的原始标签c'结合喂入到G中,将生成的图片和x计算1范数差异。
这里就是将G(x,c)和图片x的原始标签c'结合喂入到G中,将生成的图片和x计算1范数差异。
总体损失:
 在实际操作上,作者将对抗损失换成了WGAN的对抗损失:
在实际操作上,作者将对抗损失换成了WGAN的对抗损失:

以上对于单个数据集的训练来说已经足够了,但是现在想想另一个问题,假如我要联合训练多个数据集呢?
举例来说,celebA和RaFD数据集,前者有发色和性别信息,后者有面部表情信息,我能将celebA中的人物改变一下面部表情吗?
一个很简单的想法是如果我原来的域标注信息是5位的onehot编码,现在变长为8位不就可以了。但是这存在一个问题就是celebA中的人其实也有表情,只是没有标注,RaFD其实也有性别区别,但对于网络来说没标记就是未知的。简单扩充域标记信息位是肯定不行的。我们希望网络只关注它有明确信息的那一部分标注。
因此,作者加了一个mask。在联合多个数据集训练时把mask向量也输入到生成器。
 以上的ci代表第i个数据集的标签,已知标签ci如果是二进制属性则可以表示为二进制向量,如果为类别属性表示一个onehot。剩下的n-1个则指定为0。m则是一个长度为n的onehot编码。这样网络就会只关注已给定的标签。
以上的ci代表第i个数据集的标签,已知标签ci如果是二进制属性则可以表示为二进制向量,如果为类别属性表示一个onehot。剩下的n-1个则指定为0。m则是一个长度为n的onehot编码。这样网络就会只关注已给定的标签。
论文部分到此结束,下面来分析一下代码:
主要的代码有model.py和solver.py两个。
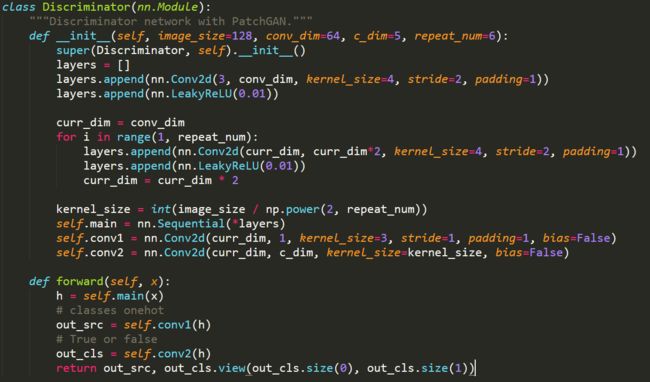
在model.py中作者创建了生成器G与鉴别器D。
在生成器中先对模型降维缩小为原来4倍,再使用多个残差网络获得等维度输出,接着使用转置卷积放大4倍,最后通过一层尺寸不变的卷积,取tanh作为输出。

另外一个值得注意的是生成器如何将输入图片与目标域c一起结合作为输入的,代码中可以看出就是直接在第四维度上进行拼接(pytorch一般为N*C*H*W,所以看起来是在第二维)。
 对于鉴别器,使用conv1的输出代表域的预测概率,conv2的输出代表图片是否为真的判断。这两个的关系是并行的。
对于鉴别器,使用conv1的输出代表域的预测概率,conv2的输出代表图片是否为真的判断。这两个的关系是并行的。
Solver.py比较长,挑选重要的部分来解释:
首先是梯度惩罚,这一部分来自WGAN的改善工作,主要是为了满足Lipschitz连续这个WGAN推导中需要的数学约束。

令人疑惑的是分类loss并不都是交叉熵损失,这是因为CelebA的标签是多属性的,不是一个onehot,所以使用了一个多个二分类的形式,而RaFD则是一个onehot。
 下面来看看在多个训练集训练时代码上是怎么操作的。
下面来看看在多个训练集训练时代码上是怎么操作的。
在数据加载上其实还是单个数据集轮流进行操作的,如下:

以上提到在多数据集训练时,我们需要mask向量,mask向量的形成按如下形式进行拼接,前面是celebA的label后面是RaFD的label,最后是onehot,代表了哪个数据集的标签是已知的。

以生成器为例,计算损失时也是只在输出判断向量中提取该数据集已知的部分进行loss计算。
