K均值算法
上一期介绍了机器学习中的监督式学习,并用了离散回归与神经网络模型算法来解决手写数字的识别问题。今天我们介绍一种机器学习中的非监督式学习算法——K均值算法。
所谓非监督式学习,是一种与监督式学习相对的算法归类,是指样本并没有一个与之对应的“标签”。例如上一期中的识别手写数字照片的例子,样本是照片的像素数据,而标签则是照片代表的数字。非监督式学习因为没有这个标签,因此就没有对样本的一个准确的“答案”。非监督式学习主要是用来解决样本的聚类问题。
K均值算法是一种迭代求解的聚类分析算法,其步骤为:
- 随机选取K个对象作为初始的聚类中心
- 计算每个对象与各个聚类中心之间的距离
- 把每个对象分配给距离它最近的聚类中心
- 将同一聚类中的对象的平均值作为新的聚类中心
- 从第2步开始循环,直到聚类中心不再变化
代码实现
随机初始化
% 样本随机排列
randidx = randperm(size(X, 1));
% 取前K个随机样本作为聚类中心
centroids = X(randidx(1:K), :);其中X为样本矩阵,每一行为一个样本,每一列为样本的维度,centroids就是随机出的K个作为聚类中心的样本矩阵。
分配聚类中心
% 遍历所有样本
for i = 1:size(X, 1)
distance = 9999999999;
for j = 1:K
% 距离公式:A(a1, a2)与B(b1, b2)之间的距离为根号下(a1-b1)^2 + (a2 - b2)^2
dist = sum((X(i, :) - centroids(j, :)) .^ 2);
if dist < distance
idx(i) = j;
distance = dist;
end
endfor
endfor通过两层循环,第一层为遍历所有样本,找到每个样本所属的聚类中心。第二层循环为遍历所有聚类中心,计算样本与聚类中心的距离,找出与类聚中心最小的距离,将该类聚中心作为样本的类聚中心。
更新聚类中心
- 方式一:循环样本
count = zeros(K, 1);
for i = 1 : m
id = idx(i);
% 累加该聚类中心下的所有样本
centroids(id, :) = centroids(id, :) + X(i, :);
count(id) = count(id) + 1;
endfor
% 均值作为新的聚类中心
centroids = centroids ./ count;- 方式二:循环类聚中心(效率更高)
for i = 1:K
% 直接通过mean函数计算均值
centroids(i,:) = mean(X(idx==i,:),1);
end可以看到,通过matlab内置的mean函数,可以更加便捷的计算出矩阵对应行的均值,并且计算过程也会比累加的方式执行更加高效。
步骤演示
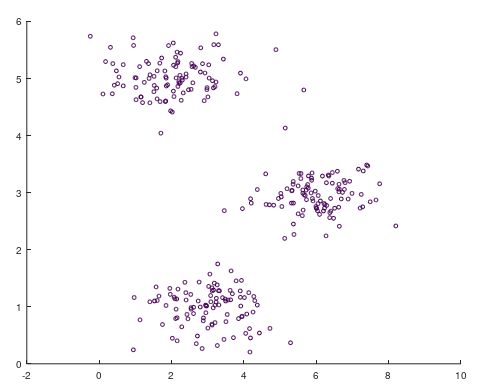
如上图所示,有一些无标签的二维坐标点。通过一些基本的判断,我们大致可以将上述的数据分为左上、中右部、左下三个聚类,但是有些中间位置的点可能不太好划分,如下图所示。
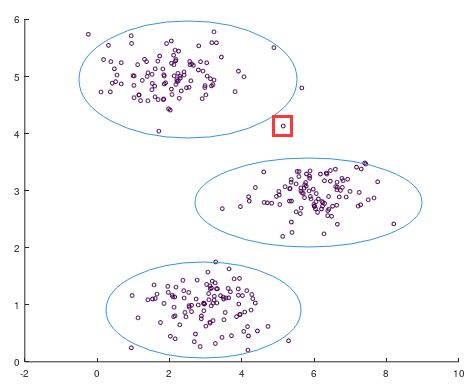
但是如何才能让机器为我们做出分类呢?机器又如何决策这些处于中间位置的点呢?于是我们来运行上述已经写好的K均值算法。
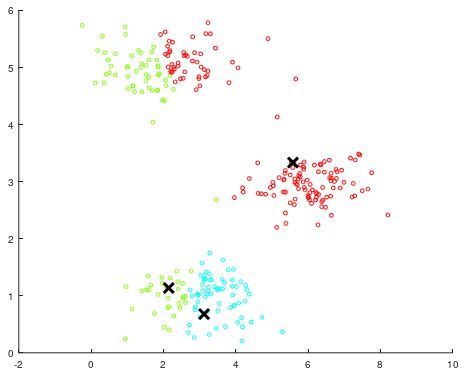
如图所示,是运行了K均值算法的第一步:随机初始化后的聚类。可以看到图中的绿色、蓝色、红色分布,因为聚类中心点是随机的,初始的聚类中心并不正确,于是我们继续运行K均值算法的后面步骤。

以绿色的聚类来举例,绿色的聚类通过一次均值计算之后,新的聚类中心点上升了许多。根据新的聚类中心点,再计算样本归属时,则会判断出下方的点已经不再属于绿色,而属于蓝色,因此就对之前的聚类进行了修正。
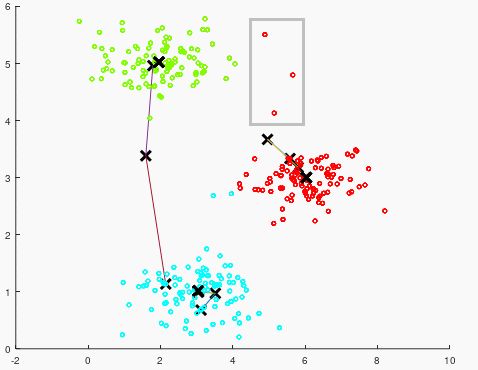
再看之前比较有疑问的绿色聚类与红色聚类之间的中间点(灰色框中所示),这几个点在感官上距离两个聚类都差不多,但根据与聚类中心点的计算对比,从数值上计算得出这几个点实际上属于红色聚类。
进行多次循环之后,聚类中心点不再变化,则说明K均值算法应用成功,分出了3个聚类并用不同颜色表示。
图片压缩

我们知道,图片是由许多像素点组成的,而每个像素点需要有RGB值。所谓RGB值是一种颜色标准,是通过对红(R)、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的。每个颜色的强度值是0-255,刚好是1个字节的大小。而3个颜色就是3个字节的大小,所以每个像素点所占大小为3字节,即24比特(故又称24位真彩色图,有1677万多色)。
以一张700*700像素的图为例,一共有490,000个像素点,每个像素点占24比特,合计11,760,000比特。如果能够应用K均值算法来实现图片的压缩呢?
压缩的前提数据有冗余,或者近似冗余。一张图片中数十万的像素点,肯定有许多像素点的RGB值是比较相似的,即图片中可能有某些位置都是同一个颜色。那么就可以应用K均值算法,将图片分成许多个聚类,用一张聚类表来存储每个聚类的颜色值,再用一张像素表来存储每个像素所在的聚类,就可以达到压缩的目的。
我选择了K=16,即有16个聚类,则原图片从1677万色变成了16色。聚类表占用的大小为16 * 24bit,即384比特。16个聚类是2的4次方只需要4个比特就可以存储聚类信息,则像素表的大小为490,000 * 4,即1,960,000。总大小为1,960,000+384=1,960,384比特,通过计算可得(压缩后大小/压缩前大小),压缩率为16.67%。即如果是100KB的图片,压缩后的大小只有16.67KB。
图片数据处理
% 调用imread读取图片
A = double(imread('test.png'));
% 将像素值处理到0-1
A = A / 255;
% 将数据从3维降到2维
img_size = size(A);
X = reshape(A, img_size(1) * img_size(2), 3);获取聚类中心
% 随机初始化
initial_centroids = kMeansInitCentroids(X, K);
% 调用之前写好的K均值算法
[centroids, idx] = runkMeans(X, initial_centroids, max_iters);压缩
% 调用之前写好的“分配聚类中心”
idx = findClosestCentroids(X, centroids);解压缩
% 通过聚类表获取原始像素值
X_recovered = centroids(idx,:);
% 将数据升至3维
X_recovered = reshape(X_recovered, img_size(1), img_size(2), 3);压缩效果展示

可以看到,压缩后的图片仍然具有较清晰的轮廓,只是色彩没有那么丰富(只有16种颜色),某些细节有一些失真,但是不影响图片的整体表达。
总结
- K均值算法是最常用也是最简单的非监督式学习聚类算法
- 第一步的随机聚类中心对聚类结果有一定影响,因此可以运行多次以达到比较好的聚类结果
- 将聚类算法的思想作用在图片上,可以达到图片压缩的目的。
- 如果想要有更好的图片质量,可以提高聚类数量K,但这样会得到较差的压缩率,需要在实践中以平衡。