pickle模块详解
该pickle模块实现了用于序列化和反序列化Python对象结构的二进制协议。 “Pickling”是将Python对象层次结构转换为字节流的过程, “unpickling”是反向操作,从而将字节流(来自二进制文件或类似字节的对象)转换回对象层次结构。pickle模块对于错误或恶意构造的数据是不安全的。
pickle协议和JSON(JavaScript Object Notation)的区别 :
1. JSON是一种文本序列化格式(它输出unicode文本,虽然大部分时间它被编码utf-8),而pickle是二进制序列化格式;
2. JSON是人类可读的,而pickle则不是;
3. JSON是可互操作的,并且在Python生态系统之外广泛使用,而pickle是特定于Python的;
默认情况下,JSON只能表示Python内置类型的子集,而不能表示自定义类; pickle可以表示极其庞大的Python类型(其中许多是自动的,通过巧妙地使用Python的内省工具;复杂的案例可以通过实现特定的对象API来解决)。
pickle 数据格式是特定于Python的。它的优点是没有外部标准强加的限制,例如JSON或XDR(不能代表指针共享); 但是这意味着非Python程序可能无法重建pickled Python对象。
默认情况下,pickle数据格式使用相对紧凑的二进制表示。如果您需要最佳尺寸特征,则可以有效地压缩数据。
模块接口
要序列化对象层次结构,只需调用该dumps()函数即可。同样,要对数据流进行反序列化,请调用该loads()函数。但是,如果您想要更多地控制序列化和反序列化,则可以分别创建一个Pickler或一个Unpickler对象。
pickle模块提供以下常量:
-
pickle.HIGHEST_PROTOCOL -
整数, 可用的最高协议版本。这个值可以作为一个被传递协议的价值函数
dump()和dumps()以及该Pickler构造函数。
-
pickle.DEFAULT_PROTOCOL -
整数,用于编码的默认协议版本。可能不到
HIGHEST_PROTOCOL。目前,默认协议是3,这是为Python 3设计的新协议。
pickle模块提供以下功能,使酸洗过程更加方便:
-
pickle.dump(obj,file,protocol = None,*,fix_imports = True ) -
将obj对象的编码pickle编码表示写入到文件对象中,相当于
Pickler(file,protocol).dump(obj)可供选择的协议参数是一个整数,指定pickler使用的协议版本,支持的协议是0到
HIGHEST_PROTOCOL。如果未指定,则默认为DEFAULT_PROTOCOL。如果指定为负数,则选择HIGHEST_PROTOCOL。文件参数必须具有接受单个字节的参数写方法。因此,它可以是为二进制写入打开的磁盘文件,
io.BytesIO实例或满足此接口的任何其他自定义对象。如果fix_imports为true且protocol小于3,则pickle将尝试将新的Python 3名称映射到Python 2中使用的旧模块名称,以便使用Python 2可读取pickle数据流。
-
pickle.dumps(obj,protocol = None,*,fix_imports = True ) -
将对象的pickled表示作为
bytes对象返回,而不是将其写入文件。参数protocol和fix_imports具有与in中相同的含义
dump()。
-
pickle.load(file,*,fix_imports = True,encoding =“ASCII”,errors =“strict” ) -
从打开的文件对象 文件中读取pickle对象表示,并返回其中指定的重构对象层次结构。这相当于
Unpickler(file).load()。pickle的协议版本是自动检测的,因此不需要协议参数。超过pickle对象的表示的字节将被忽略。
参数文件必须有两个方法,一个采用整数参数的read()方法和一个不需要参数的readline()方法。两种方法都应返回字节。因此,文件可以是为二进制读取而打开的磁盘文件,
io.BytesIO对象或满足此接口的任何其他自定义对象。可选的关键字参数是fix_imports,encoding和errors,用于控制Python 2生成的pickle流的兼容性支持。如果fix_imports为true,则pickle将尝试将旧的Python 2名称映射到Python 3中使用的新名称。编码和 错误告诉pickle如何解码Python 2编码的8位字符串实例; 这些默认分别为'ASCII'和'strict'。该编码可以是“字节”作为字节对象读取这些8位串的实例。使用
encoding='latin1'所需的取储存NumPy的阵列和实例datetime,date并且time被Python 2解码。
-
pickle.loads(bytes_object,*,fix_imports = True,encoding =“ASCII”,errors =“strict” ) -
从
bytes对象读取pickle对象层次结构并返回其中指定的重构对象层次结构。pickle的协议版本是自动检测的,因此不需要协议参数。超过pickle对象的表示的字节将被忽略。
import numpy as np import pickle import io if __name__ == '__main__': path = 'test' f = open(path, 'wb') data = {'a':123, 'b':'ads', 'c':[[1,2],[3,4]]} pickle.dump(data, f) f.close() f1 = open(path, 'rb') data1 = pickle.load(f1) print(data1)

对于python格式的数据集,我们就可以使用pickle进行加载了,下面与cifar10数据集为例,进行读取和加载:
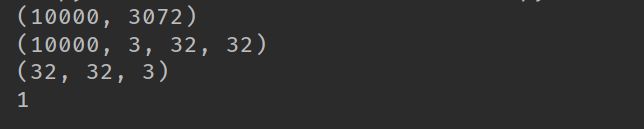
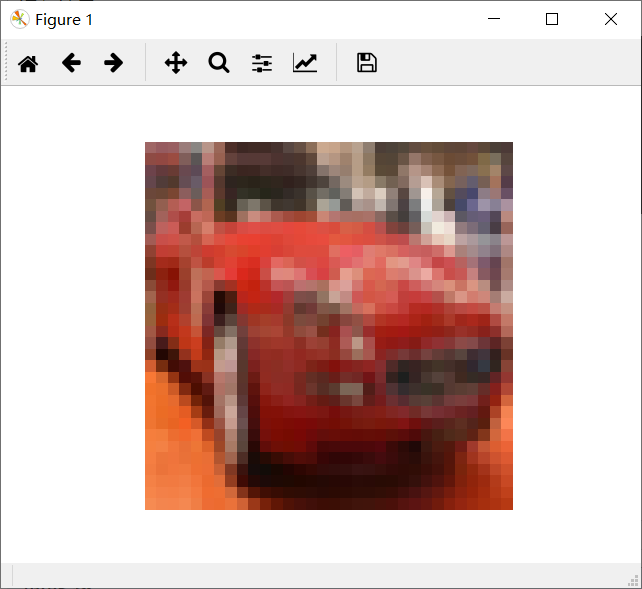
import numpy as np import pickle import random import matplotlib.pyplot as plt from PIL import Image path1 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_1' path2 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_2' path3 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_3' path4 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_4' path5 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\data_batch_5' path6 = 'D:\\tmp\cifar10_data\cifar-10-batches-py\\test_batch' if __name__ == '__main__': with open(path1, 'rb') as fo: data = pickle.load(fo, encoding='bytes') # print(data[b'batch_label']) # print(data[b'labels']) # print(data[b'data']) # print(data[b'filenames']) print(data[b'data'].shape) images_batch = np.array(data[b'data']) images = images_batch.reshape([-1, 3, 32, 32]) print(images.shape) imgs = images[5, :, :, :].reshape([3, 32, 32]) img = np.stack((imgs[0, :, :], imgs[1, :, :], imgs[2, :, :]), 2) print(img.shape) plt.imshow(img) plt.axis('off') plt.show()
运行结果:
接下来就可以读取数据进行训练了。