numpy基础要点
1.生成数组 np.array([])
2.变量的类型 numpy.ndarray
3.数据的类型 int8,float64,float32,bool等
4.数据的类型转换 x.astype("float32")
5.保留N位小数 np.round(x,n)
6.切片和索引
6.1 行选择 x[2]或x[2:,:]
6.2 列选择 x[:,4:]
6.3 连续多行 x[2:,:3]
6.4 不连续的几个值 x[[1,3],[2,4]]注:这是选择(1,2)和(3,4)两个位置的值
6.5 索引具体选择某个值 x[2,3]
7.赋值操作 x[2:,3] = 3
8.布尔索引 x[x>10] = 0
9.三元运算符 np.where(x > 10, 20, 0)
10.剪裁 x.clip(5,10) 把小于5的替换为5,大于10的替换为10
11.转置的方法 x.T,x.transpose(),t.swapaxes(1,0)
12.读取本地文件 np.loadtxt(file_path,delimiter.dtype),file_path文件路径,delimiter分隔符,dtype数据类型
13.关于nan
13.1 nan不是一个数字,
13.2 自身不相等(np.nan!=np.nan),
13.3 nan个数统计np.count_nonzero(np.nan!=np.nan),
13.4 nan类型判断np.isnan(x)
14.inf 表示无穷
15.常用的几个统计函数
15.1 x.sum(axis=0) 在某个维度上求和
15.2 np.median(x,axis=0) 在某个维度上的中位数
15.3 x.mean(axis=0) 在某个维度上的平均值
15.4 x.max(axis=0) 在某个维度上的最大值
15.5 np.ptp 计算极差
15.6 x.std 计算标准差梵音数据的离散程度和稳定程度
import numpy as np
import random
# 1.生成数组 np.array([]),np.array(range()),np.arange()
x = np.array([1,2,3,4,5,6])
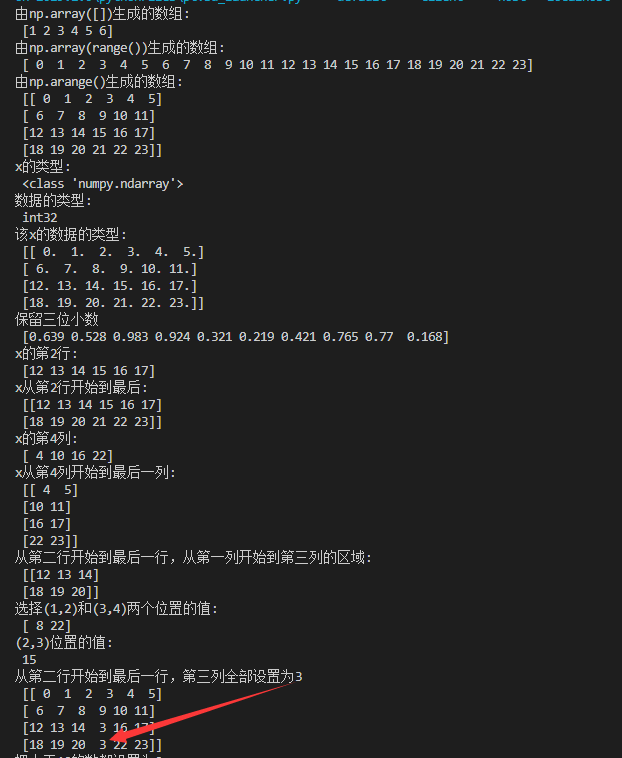
print("由np.array([])生成的数组:\n",x)
x = np.array(range(24))
print("由np.array(range())生成的数组:\n",x)
x = np.arange(24).reshape(4,6)
print("由np.arange()生成的数组:\n",x)
# 2.变量的类型 numpy.ndarray
print("x的类型:\n",type(x))
# 3.数据的类型 int8,float64,float32,bool等
print("数据的类型:\n",x.dtype)
# 4.数据的类型转换 x.astype("float32")
print("该x的数据的类型:\n",x.astype("float32"))
# 5.保留N位小数 np.round(x,n)
#print("保留三位小数",np.round(np.random(4),3))
print("保留三位小数\n", np.round(np.array([random.random() for i in range(10)]),3))
# 6.切片和索引
# 6.1 行选择 x[2]或x[2:,:]索引从0开始
print("x的第2行:\n",x[2])
print("x从第2行开始到最后:\n",x[2:])
# 6.2 列选择 x[:,4:]
print("x的第4列:\n",x[:,4])
print("x从第4列开始到最后一列:\n",x[:,4:])
# 6.3 连续多行 x[2:,:3]
print("从第二行开始到最后一行,从第一列开始到第三列的区域:\n",x[2:,:3])
# 6.4 不连续的几个值 x[[1,3],[2,4]]注:这是选择(1,2)和(3,4)两个位置的值
print("选择(1,2)和(3,4)两个位置的值:\n",x[[1,3],[2,4]])
# 6.5 索引具体选择某个值 x[2,3]
print("(2,3)位置的值:\n",x[2,3])
# 7.赋值操作 x[2:,3] = 3
x[2:,3] = 3
print("从第二行开始到最后一行,第三列全部设置为3\n",x)
x = np.arange(24).reshape(4,6)
# 8.布尔索引 x[x>10] = 0
x[x>10] = 0
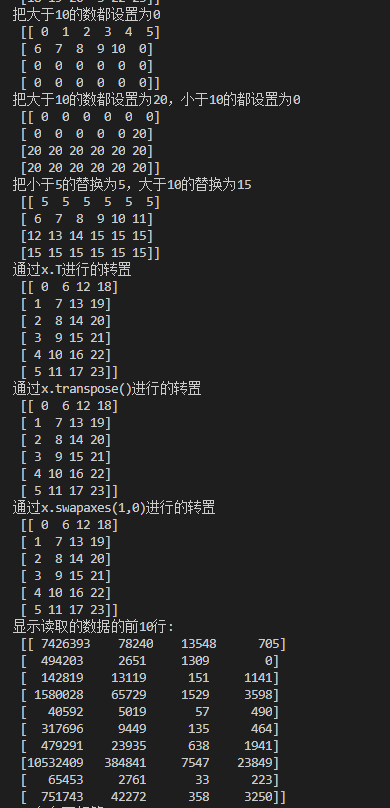
print("把大于10的数都设置为0\n",x)
x = np.arange(24).reshape(4,6)
# 9.三元运算符 np.where(x > 10, 20, 0)
print("把大于10的数都设置为20,小于10的都设置为0\n",np.where(x > 10, 20, 0))
# 10.剪裁 x.clip(5,15) 把小于5的替换为5,大于15的替换为15
print("把小于5的替换为5,大于10的替换为15 \n",x.clip(5,15))
# 11.转置的方法 x.T,x.transpose(),x.swapaxes(1,0)
print("通过x.T进行的转置\n",x.T)
print("通过x.transpose()进行的转置\n",x.transpose())
print("通过x.swapaxes(1,0)进行的转置\n",x.swapaxes(1,0))
# 12.读取本地文件 np.loadtxt(file_path,delimiter.dtype),file_path文件路径,delimiter分隔符,dtype数据类型
data = np.loadtxt("./code/data.csv",delimiter=",",dtype=int)
print("显示读取的数据的前10行:\n",data[:10])
# 13.关于nan
# 13.1 nan不是一个数字,
# 13.2 自身不相等(np.nan!=np.nan),
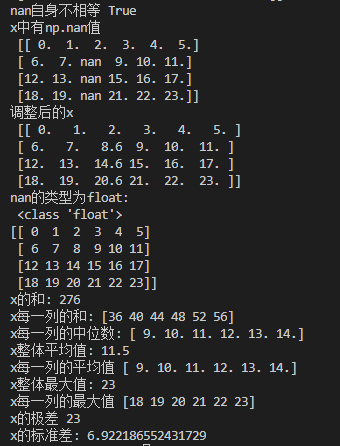
print("nan自身不相等",np.nan!=np.nan)
# 13.3 nan个数统计np.count_nonzero(np.nan!=np.nan),
# 13.4 nan类型判断np.isnan(x)
x = x.astype("float")
x[1:,2] = np.nan
print("x中有np.nan值\n",x)
# 用每行的平均值填充该nan值
for i in range(x.shape[0]):#遍历每一行
temp_row = x[i] #当前行
nan_num = np.count_nonzero(temp_row != temp_row) #统计当前行中nan的个数
if nan_num != 0:#如果nan的个数不为0,则用其他值的平均值来填充该值
temp_not_nan_row = temp_row[temp_row == temp_row]#当前行部位nan的数组
#把平均值赋值为不为nan的均值
temp_row[np.isnan(temp_row)] = temp_not_nan_row.mean()
print("调整后的x\n",x)
print("nan的类型为float:\n",type(np.nan))
#如果不设置x的类型为float类型,则上边的循环是不起作用的。
# 14.inf 表示无穷
# 15.常用的几个统计函数
# 15.1 x.sum(axis=0) 在某个维度上求和
# 15.2 np.median(x,axis=0) 在某个维度上的中位数
# 15.3 x.mean(axis=0) 在某个维度上的平均值
# 15.4 x.max(axis=0) 在某个维度上的最大值
# 15.5 np.ptp 计算极差
# 15.6 x.std 计算标准差梵音数据的离散程度和稳定程度
x = np.arange(24).reshape(4,6)
print(x)
print("x的和:",x.sum())
print("x每一列的和:",x.sum(axis=0))
print("x每一列的中位数:",np.median(x,axis=0))
print("x整体平均值:",x.mean())
print("x每一列的平均值",x.mean(axis=0))
print("x整体最大值:",x.max())
print("x每一列的最大值",x.max(axis=0))
print("x的极差",np.ptp(x))
print("x的标准差:",x.std(axis=None))