Hbase
列式存储以流的方式在列中存储所有的数据。对于任何记录,索引都可以快速地获取列上的数据;列式存储支持行检索,但这需要从每个列获取匹配的列值,并重新组成行。HBase(Hadoop Database)是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase是Google BigTable的开源实现,模仿并提供了基于Google文件系统的BigTable数据库的所有功能。HBase可以直接使用本地文件系统或者Hadoop作为数据存储方式,不过为了提高数据可靠性和系统的健壮性,发挥HBase处理大数据量等功能,需要使用Hadoop作为文件系统。HBase仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务,主要用来存储非结构化和半结构化的松散数据。
Hbase中表的特点:大,稀疏,面向列
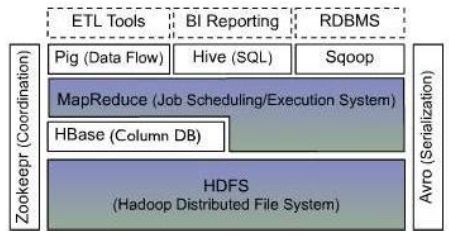
Hadoop生态系统中的各层系统
HBase位于结构化存储层;
HDFS为HBase提供了高可靠性的底层存储支持;
MapReduce为HBase提供了高性能的计算能力;
Zookeeper为HBase提供了稳定服务和失败恢复机制;
Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单;
Sqoop则为HBase提供了方便的RDBMS数据导入功能,方便数据迁移;
Hbase在互联网存储的几个应用场景:
1.抓取增量数据
使用HBase 作为数据存储,抓取来自各种数据源的增量数据,如抓取用户交互数据,以备之后进行分析、处理
2.内容服务
传统数据库最主要的使用场合之一是为用户提供内容服务,如URL短链接服务,可以HBase为基础,存储大量的短链接以及和原始长链接的映射关系
3.信息交换
Facebook的短信平台每天交换数十亿条短信,HBase可以很好的满足该平台的需求:高的写吞吐量,极大的表,数据中心的强一致性
Hbase与传统关系型数据库区别:
数据类型
HBase只有简单的字符串类型,所有类型都由用户自己处理,它只保存字符串;
关系数据库有丰富的类型选择和存储方式。
数据操作
HBase操作只有很简单的插入、查询、删除、清空等,表和表之间是分离的,没有复杂的表和表之间的关系,所以也不能也没有必要实现表和表之间的关联等操作;
传统的关系数据通常有各种各样的函数、连接操作。
存储模式
HBase是基于列存储的,每个列族都有几个文件保存,不同列族的文件是分离的;
传统的关系数据库是基于表格结构和行模式保存的。
数据维护
HBase的更新正确来说应该不叫更新,而且一个主键或者列对应的新的版本,而它旧有的版本仍然会保留,所以它实际上是插入了新的数据;
传统关系数据库里面是替换修改。
可伸缩性
HBase和BigTable这类分布式数据库就是直接为了这个目的开发出来的,能够轻易的增加或者减少(在硬件错误的时候)硬件数量,而且对错误的兼容性比较高;
传统的关系数据库通常需要增加中间层才能实现类似的功能。
修改表模式需要先将表设置为不可用(disable),模式修改完成再启用表(enable)
HBase的三个主要的功能组件
库函数:链接到每个客户端;一个HMaster主服务器;许多个HRegion服务器。
Hbase三层结构
1.Zookeeper文件:它记录了-ROOT-表的位置信息,即root region的位置信息。
2.-ROOT-表:只包含一个root region,记录了.META.表中的region信息。通过root region,我们就可以访问.META.表的数据。
3.META.表:记录了用户表的HRegion信息,.META.表可以有多个HRegion,保存了HBase中所有数据表的HRegion位置信息。
Hbase两种文件类型
HFile:HBase中KeyValue数据的存储格式,HFile是Hadoop的二进制格式文件,实际上HStoreFile就是对HFile做了轻量级包装,即HStoreFile底层就是HFile。
HLogFile:HBase中WAL(Write Ahead Log)的存储格式,物理上是Hadoop的顺序文件。
Redis
Redis是一个key-value存储系统,key为字符串类型,只能通过key对value进行操作,支持的数据类型包括string、list、set、zset(有序集合)和hash。Redis支持主从同步,数据可以从主服务器向任意数量的从服务器上同步。
Redis事务允许一组命令在单一步骤中执行。事务有两个属性:在一个事务中的所有命令作为单个独立的操作顺序执行;Redis事务是原子的,原子意味着要么所有的命令都执行,要么都不执行。Redis 事务由指令 MULTI 发起的,之后传递需要在事务中和整个事务中,最后由 EXEC 命令执行所有命令的列表。
Redis分区
是将数据分割成多个 Redis 实例,使每个实例将只包含键子集的过程.它允许更大的数据库,使用多台计算机的内存总和,它允许按比例在多内核和多个计算机计算,以及网络带宽向多台计算机和网络适配器。劣势:涉及多个键时,Redis事务无法使用;数据处理比较复杂;加和删除的容量可能会很复杂。
分区类型:范围分区;散列分区
Redis 数据库可以配置安全保护的,所以任何客户端在连接执行命令时需要进行身份验证。
应用:统计
MongodDB
一个基于分布式文件存储的开源数据库系统,为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB 将数据存储为一个文档,数据结构由键值(key value)对组成。
特点:
面向集合存储,易存储对象类型的数据;模式自由;支持动态查询;支持完全索引,包含内部对象;支持查询;支持复制和故障恢复;使用高效的二进制数据存储,包括大型对象(如视频);自动处理碎片,以支持云计算层次的扩展性;支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言;文件存储格式为BSON(一种JSON的扩展);可通过网络访问。
适用场景:网站数据;缓存;大尺寸,低价值的数据;高伸缩性的场景;用于对象及JSON 数据的存储。
不适用场景:高度事务性的系统;传统的商业智能应用;需要SQL 的问题。
*聚合管道将文档在一个管道处理完毕后将结果传递给下一个管道处理,管道操作是可以重复的。
引用式文档查询:需要两次查询
第一次查询用户地址的对象id(ObjectId);第二次通过查询的id获取用户的详细地址信息。
集合中索引不能超过64个;索引名的长度不能超过125个字符;一个复合索引最多可以有31个字段。mongorestore 命令来恢复备份的数据。
Neo4j
是一个高性能的 NoSQL 图形数据库,把数据保存为图中的节点以及节点之间的关系。Neo4j 中两个最基本的概念是节点和边
节点表示实体,边则表示实体之间的关系。节点和边都可以有自己的属性,不同实体通过各种不同的关系关联起来,形成复杂的对象图。
Neo4j 提供了在对象图上进行查找和遍历的功能:深度搜索、广度搜索。
特点:
完整的ACID支持;高可用性;轻易扩展到上亿级别的节点和关系;通过遍历工具高速检索数据;属性是由Key-Value键值对组成。
应用:社交网络,歌曲信息,状态图
数据库转化
关系型数据库
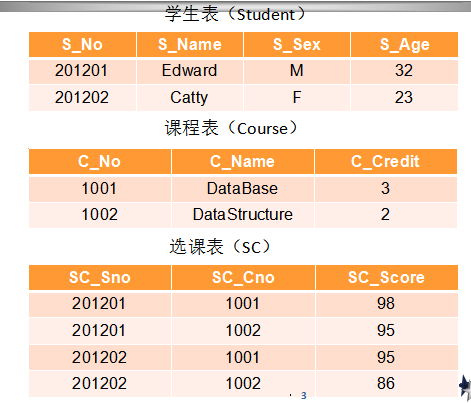
Hbase
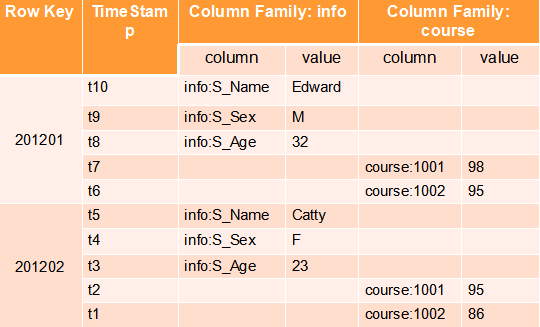
Redis
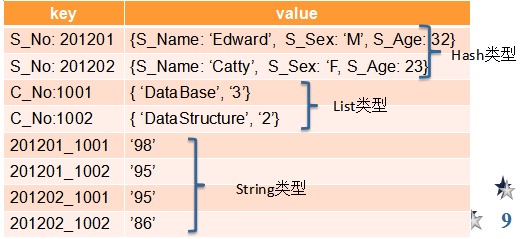
MongoDB
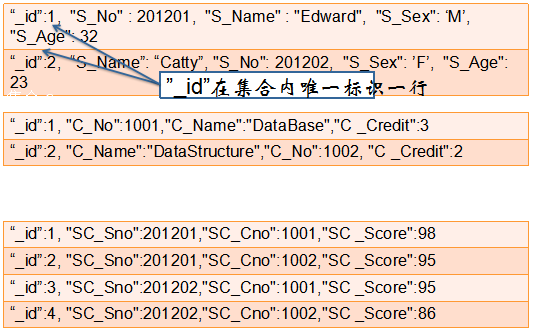
Neo4j

NewSQL
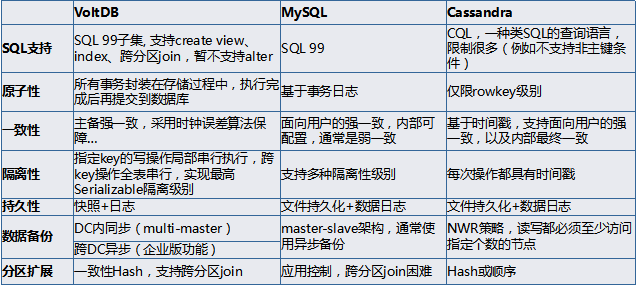
是对各种新的可扩展/高性能数据库的简称。具有NoSQL对海量数据的存储管理能力,保持了传统数据库支持ACID和SQL等特性。
NewSQL共同特点:支持关系数据模型;使用SQL作为其主要的接口。
转载:https://blog.csdn.net/qq_34116402/article/details/79578187